Краткая история НЛП — trEnings.ru: всё о НЛП
Нейро-лингвистическое программирование (НЛП) – околопсихологическая дисциплина, появившаяся в 70-е годы в США и до сих пор популярная как у себя на родине, так и в Европе, по другую сторону океана. Основатели НЛП с самого начала поставили себя в оппозицию к академической психологии, немедленно снискав неоднозначную репутацию – но, тем не менее, это направление продолжает расти и развиваться вот уже более 30 лет. Что же представляло и представляет собой НЛП? Не устарело ли оно? Что произошло с ним за столь немалый срок? Цель этой статьи – помочь читателю сориентироваться в мире НЛП и понять, чем эта область может быть интересна, с чего можно начать обучение и чем продолжить.*
Родина НЛП – город Санта-Круз в Калифорнии. Именно там находилось отделение калифорнийского университета, в котором один из основателей НЛП, Джон Гриндер, работал профессором на кафедре лингвистики, а Ричард Бэндлер – второй основатель НЛП, обучался математике и программированию. Бэндлер был увлечен работой Фрица Перлза, одного из столпов гештальт-терапии. Он редактировал его книги, смотрел видеозаписи, и, весьма успешно копируя методы его работы, проводил сессии с клиентами и даже семинары. На один из таких семинаров в 1972 году был приглашен Джон Гриндер, увлеченный лингвистикой психолог, бывший ассистент Джорджа Миллера, отца когнитивной психологии. Цель его прихода была проста: понять, как Бэндлер делает то, что он делает и попытаться воспроизвести это.
Бэндлер был увлечен работой Фрица Перлза, одного из столпов гештальт-терапии. Он редактировал его книги, смотрел видеозаписи, и, весьма успешно копируя методы его работы, проводил сессии с клиентами и даже семинары. На один из таких семинаров в 1972 году был приглашен Джон Гриндер, увлеченный лингвистикой психолог, бывший ассистент Джорджа Миллера, отца когнитивной психологии. Цель его прихода была проста: понять, как Бэндлер делает то, что он делает и попытаться воспроизвести это.
Гриндер попробовал объяснить работу Бэндлера на языке трансформационной грамматики и общей семантики. А помог ему в этом Грегори Бэйтсон – всемирно известный антрополог, кибернетик и лингвист, проживавший по соседству. Вместе они создали дисциплину, основным направлением которой стало моделирование – изучение и воспроизводство поведения «гениев», людей обладающих уникальными способностями.
Кстати, организатором тех семинаров по гештальту был Френк Пьюселик – впоследствии ставший одним из лучших тренеров НЛП, сейчас живущий в Одессе и регулярно проводящий тренинги в Москве. В 1975 году вышла основополагающая книга по НЛП, «Структура магии». В ней были описаны лингвистические паттерны Перлза, а также других известных психотерапевтов того времени: Милтона Эриксона и Вирджинии Сатир. Кроме лингвистики – искусства задавания вопросов и изменения отношения к ситуациям, был описан ряд моделей, позволявшие терапевтам «читать» своих клиентов, словно открытую книгу, и помогать им в разрешении сложных ситуаций. Так появилось классическое НЛП, основной фокус внимания которого – эффективная коммуникация и помощь другим.
В 1975 году вышла основополагающая книга по НЛП, «Структура магии». В ней были описаны лингвистические паттерны Перлза, а также других известных психотерапевтов того времени: Милтона Эриксона и Вирджинии Сатир. Кроме лингвистики – искусства задавания вопросов и изменения отношения к ситуациям, был описан ряд моделей, позволявшие терапевтам «читать» своих клиентов, словно открытую книгу, и помогать им в разрешении сложных ситуаций. Так появилось классическое НЛП, основной фокус внимания которого – эффективная коммуникация и помощь другим.
Около 1980-го года между основателями НЛП произошел «развод», в результате которого каждый из них стал двигаться в своем направлении. Бэндлера заинтересовали субмодальности – тонкие различия в структуре нашего восприятия. Как яркость вспоминаемой «картинки» зависит от интенсивности переживаний? Как, управляя этими вещами, мы можем менять наше восприятие и отношение к ситуациям? Такими вопросами задался Бэндлер, и его дальнейшие исследования вертелись вокруг этой темы. Сейчас Ричард ведет тренинги по Design Human Engineering (DHE), что примерно можно перевести как «инженерное моделирование человека». Это способ «встраивать» себе внутрь различные «приборы»: часы, компасы, регуляторы пульса – и таким образом управлять собой. Кроме того, Бэндлер ведет семинары по Neuro-Hypnotic Repatterning – «нейро-гипнотическому перепрограммированию», модель, которая представляет собой рафинированные паттерны гипноза Милтона Эриксона.
Сейчас Ричард ведет тренинги по Design Human Engineering (DHE), что примерно можно перевести как «инженерное моделирование человека». Это способ «встраивать» себе внутрь различные «приборы»: часы, компасы, регуляторы пульса – и таким образом управлять собой. Кроме того, Бэндлер ведет семинары по Neuro-Hypnotic Repatterning – «нейро-гипнотическому перепрограммированию», модель, которая представляет собой рафинированные паттерны гипноза Милтона Эриксона.
Джон Гриндер пошел другой, хотя в чем-то очень похожей дорогой. В середине 80-х он по его словам, «оглядел мир НЛП и обнаружил, что многие люди, преуспевшие во влиянии на других явно не способны помочь сами себе». Тогда он создал подход, известный как «Новый Код НЛП», предназначенный для самоприменения. Основная идея Нового кода – работа с состояниями и доверие бессознательному, использование его ресурсов для принятия решений.
В конце 1980-годов из НЛП выделились еще несколько групп со своими, оригинальными подходами. Среди них можно назвать Тони Роббинса, отца лайф-коучинга, Тодда Джеймса, развивающего подход под названием «терапия на линии времени» и, конечно же, Роберта Дилтса. Изрядно разбавив НЛП теорией систем и другими аналитическими методами, Дилтс создал школу, известную как «Системное НЛП».
Изрядно разбавив НЛП теорией систем и другими аналитическими методами, Дилтс создал школу, известную как «Системное НЛП».
Примерно тогда же, в конце 1980-х, НЛП попало в Россию. Первые российские НЛП-Практики из Новосибирска проходили обучение у Джона Гриндера в Калифорнии. Они создали базис – площадку для «заезжих звезд» и последующее поколение российских тренеров училось уже в России. Пожалуй, самые известные и частые гости – Энн Энтус и Мерелин Аткинсон, коллеги Роберта Дилтса. Соответственно, большая часть российского НЛП – это «Системное НЛП». Кроме того, два раза в нашей стране проводил семинары Джон Гриндер: в 1997 и 2004 году. У него учились практически все российские тренера Нового кода. Ричард Бэндлер в России не бывал – однако, несколько тренеров (их число измеряется единицами) обучались у него в Великобритании и даже прошли сертификацию.
С чего начать обучение НЛП? Если вас интересуют коммуникативные навыки и консультирование, то лучший выбор – это базовый, стандартный курс «НЛП-Практик». Он может продолжаться до 20 дней и проходит в нескольких вариантах: выходные раз в месяц, два-четыре раза в месяц и непрерывно (интенсивный курс). Ожидайте много разговоров – лингвистики, много работы в тройках: клиент-консультант-супервизор. Если вам понравится, и вас заинтересуют более «продвинутые» лингвистические паттерны, работа с убеждениями и моделирование – добро пожаловать на курс «НЛП-Мастер». Если вы хотите скорее помочь себе и научиться общаться с собой – вам подойдет Новый код НЛП. Как правило, это короткий двухдневный семинар, который предусматривает последующую самостоятельную работу.
Он может продолжаться до 20 дней и проходит в нескольких вариантах: выходные раз в месяц, два-четыре раза в месяц и непрерывно (интенсивный курс). Ожидайте много разговоров – лингвистики, много работы в тройках: клиент-консультант-супервизор. Если вам понравится, и вас заинтересуют более «продвинутые» лингвистические паттерны, работа с убеждениями и моделирование – добро пожаловать на курс «НЛП-Мастер». Если вы хотите скорее помочь себе и научиться общаться с собой – вам подойдет Новый код НЛП. Как правило, это короткий двухдневный семинар, который предусматривает последующую самостоятельную работу.
Начав заниматься НЛП, вы можете получить множество позитивных результатов. Но НЛП – не «волшебная таблетка». Нельзя сказать, что НЛП подойдет всем. Это довольно специфический подход, где многое основано не на строгих научных выкладках, а на блестящих догадках и ощущении, что «это работает». В ряде областей, таких как коммуникативная компетентность, личностное развитие и консультирование, НЛП имеет заслуженную репутацию «технологии успеха». И если вы откроете книгу по НЛП или придете на тренинг – возможно, у вас будет шанс понять это для себя.
И если вы откроете книгу по НЛП или придете на тренинг – возможно, у вас будет шанс понять это для себя.
* — В статье специально не упоминаются имена российских тренеров – но желающие без труда найдут их.
Краткая история НЛП
- Подробности
- Автор: Vladislav Troshin
- Просмотров: 5758
Краткая история «НЛП»
НЛП (Нейро — Лингвистическое программирование) возникло в начале 1970-х и стало плодом сотрудничества Джона Гриндера, который в то время был ассистентом профессора лингвистики в университете Калифорнии в городе Санта Круз и Ричарда Бендлера — студента этого же университета. Они вместе изучали действия трех выдающихся психотерапевтов: Фрица Перлза, новатора психотерапии и основоположника школы терапии, известной под названием гештальт-терапии,
Вирджинии Сатир, необыкновенного семейного психотерапевта, которой удавалось разрешать такие семейные взаимоотношения, которые многие другие семейные психотерапевты считали неприступными. И наконец, Милтона Эриксона, всемирно известного гипнотерапевта.
И наконец, Милтона Эриксона, всемирно известного гипнотерапевта.
Джон Гриндер и Ричард Бендлер, вовсе не собирались открывать новую школу терапии, они лишь хотели определить паттерны, используемые выдающимися терапевтами и передать их другим. Их не интересовали теории, они создавали модели успешной терапии, которые работали на практике, которым можно было научиться самим и научить других.
Трое терапевтов, которых они моделировали, представляли собой индивидуальности, значительно отличавшихся друг от друга. Джону и Ричарду удалось выделить удивительно схожие основные паттерны, которые использовал каждый из них. Обнаружив эти паттерны, Бендлер и Гриндер рафинировали их и построили изящную модель, которая может быть применена как в эффективной коммуникации, так и личностном изменении или ускоренном обучении. И конечно же, в получении большего удовольствия от жизни.
В 1975-77 годах, Гриндер и Бендлер опубликовали свои первые значительные открытия в книгах:
«Структура магии»(том I), «Структура магии»(том II), «Наведение транса» (1 часть) и «Паттерны гипнотических техник Милтона Эриксона» (2 часть).
С тех пор, количество публикуемой литературы по НЛП и Эриксоновскому гипнозу увеличивается с нарастающей скоростью.
В то время Джон и Ричард встретились с Грегори Бэйтсоном, выдающимся англо-американским антропологом, автором работ по коммуникации и теории систем. Научные интересы Бэйтсона были чрезвычайно широки: биология, кибернетика, этнология и культурная антропология, психология и психиатрия. Он всемирно известен разработкой теории «двойного послания» (англ. double bind). Двойное послание — коммуникативный парадокс, впервые описанный в контексте изучения шизофрении. Его вклад в эти дисциплины чрезвычайно велик. И вероятно, только сейчас становится все более очевидным, насколько он был глубок.
Физик Фритьоф Капра в книге «Уроки Мудрости», писал: «будущие историки сочтут Грегори Бейтсона одним из наиболее влиятельных мыслителей нашего времени. Уникальность его мышления связана с широтой и обобщённостью. Во времена, характеризующиеся разделением и сверхспециализацией, Бейтсон противопоставил основным предпосылкам и методам различных наук, поиск паттернов, лежащих за паттернами и процессов, лежащих в основе структур.
Начиная с этих первоначальных моделей НЛП развивалось в двух взаимодополняющих направлениях.
Во-первых, как процесс обнаружения паттернов мастерства в любой области человеческой деятельности.
Во-вторых, как эффективный способ мышления и коммуникации, присущий выдающимся людям.
Эти паттерны и умения могут быть использованы сами по себе, но кроме того могут служить обратной связью в процессе моделирования, чтобы сделать его еще более мощным.
В 1977 году Джон и Ричард провели серию весьма успешных публичных семинаров по всей Америке. С тех пор, НЛП начинает очень быстро распространяться по всему миру.
Санта Круз. Калифорния. США. 1976 год
Весной 1976 года Джон и Ричард собрали воедино все открытия, которые они сделали к этому времени. Тогда же, они задали себе вопрос о том, как все это будет называться.
В результате получилось: Нейро-Лингвистическое Программирование — громоздкое словосочетание, за которым скрываются три простые идеи.
Слово «Нейро-» в названии, отражает ту фундаментальную идею, что поведение берет начало в неврологических процессах видения, слушания, восприятия запаха, вкуса, прикосновения и ощущения. Мы воспринимаем мир через пять своих органов чувств, извлекаем «смысл» из информации. Наша неврология включает в себя не только невидимые мыслительные процессы, но и видимые физиологические реакции на идеи и события. Одно, просто является отражением другого на физическом уровне. Тело и разум образуют неразделимое единство, человеческое существо.
Слово «-Лингвистическое» показывает, что мы используем язык для того, чтобы упорядочивать наши мысли и поведение и чтобы вступать в коммуникацию с другими людьми.
Слово «Программирование» указывает на те способы, которыми мы организуем свои идеи и действия, чтобы получать результаты.
НЛП имеет дело со структурой субъективного опыта человека: тем, как мы организуем то, что видим, слышим и ощущаем, и как мы редактируем и фильтруем с помощью органов чувств то, что получаем из внешнего мира. НЛП также исследует то, как мы описываем это в языке и как мы действуем — намеренно или ненамеренно — чтобы получать результаты.
НЛП также исследует то, как мы описываем это в языке и как мы действуем — намеренно или ненамеренно — чтобы получать результаты.
Некоторые, значимые даты в истории НЛП с 1972 года.
1972 год. Джон Гриндер – доктор, преподаватель лингвистики, математики и экономики; Ричард Бендлер – студент факультета кибернетики.
1975 год. Выходит в свет основополагающая книга по НЛП – «Структура магии» (том I).
1978 год. Состоялся 1-й сертификационный курс «НЛП-Практик».
1980 год. Ричард Бендлер поссорился с Джоном Гриндером и развелся со своей женой Лесли Камерон-Бендлер, которая впоследствии ввела свой бренд — «Императивный самоанализ».
1987 год. В Пентагоне заслушали доклад по результатам 4-летнего изучения НЛП, которое проходило в рамках программы «Джидай».
1988 год. НЛП становится доступным широкому кругу людей за пределами США.
1989 год. Роберт Дилтс и Джудит Делозье отделились от Джона Гриндера со своим новым брендом – «Системное НЛП».
1989 год. НЛП появляется в СССР (России).
1996 год. Ричард Бендлер подал иск в суд за использование бренда НЛП, требуя по 10 млн. долларов с каждого: Джона Гриндера; Кармен Бостик СентКлер; Стива и Кониру Андреас.
2000 год. Верховный Суд США вынес решение: НЛП не подлежит патентованию.
2001 год. Джон Гриндер и Ричард Бендлер делают совместное заявление, в котором оба признают соавторство и равный вклад друг друга в создание и раннее развитие НЛП. Это заявление опубликовано в книге «Шепот на ветру».
2010 год. Джон Гриндер и Ричард Бендлер, отдельно друг от друга, проводят открытые тренинги, соответственно: по Новому Коду НЛП и DHE (Design Human Engineering), а также по Эриксоновскому Гипнозу.
- Вперёд >
Обработка естественного языка (NLP) | Эволюция и будущее
Что такое обработка естественного языка?
Обработка естественного языка Подмножество техники искусственного интеллекта, которая используется для сокращения разрыва в общении между компьютером и человеком.
Простыми словами язык можно понимать как набор правил или символов. Эти символы интегрируются и затем используются для передачи, а также трансляции информации. Здесь применяются правила для подавления символов. Область обработки естественного языка разделена на подобласти, то есть генерацию естественного языка и понимание естественного языка, которые, как следует из названия, связаны с генерацией и пониманием текста. Следующая диаграмма в общих чертах показывает эти точки. Не запутайтесь в этих новых терминах, таких как фонология, прагматика, морфология, синтаксис и семантика.
- Фонология — Эта наука помогает разобраться с моделями, присутствующими в звуке и речи, относящимися к звуку как к физическому объекту.
- Прагматика — Эта наука изучает различные способы использования языка.
- Морфология — Эта наука занимается структурой слов и систематическими отношениями между ними.
- Синтаксис — Эта наука занимается структурой предложений.
- Семантика — Эта наука имеет дело с буквальным значением слов, фраз и предложений.
Способность машин понимать и интерпретировать человеческий язык так, как он написан или произнесен. Нажмите, чтобы узнать о методах и приложениях НЛП
Какова история обработки естественного языка?
История обработки естественного языка описана:
Начало
Как сказано выше, идея возникла из-за потребности в машинном переводе в 1940с. Тогда исходным языком был английский и русский. Но использование других слов, таких как китайский, также возникло в начальный период 1960-х годов. Затем в 1966 году для МТ/НЛП наступила паршивая эра, этот факт подтверждался отчетом ALPAC, согласно которому чуть не умер, потому что исследования в этой области не имели в то время темпов. Это состояние снова улучшилось в 1980-х годах, когда связанный с ним продукт начал приносить клиентам некоторые результаты. Достигнув умирающего состояния в 1960-е годы получили новую жизнь, когда возникла идея и потребность в искусственном интеллекте.
Тогда исходным языком был английский и русский. Но использование других слов, таких как китайский, также возникло в начальный период 1960-х годов. Затем в 1966 году для МТ/НЛП наступила паршивая эра, этот факт подтверждался отчетом ALPAC, согласно которому чуть не умер, потому что исследования в этой области не имели в то время темпов. Это состояние снова улучшилось в 1980-х годах, когда связанный с ним продукт начал приносить клиентам некоторые результаты. Достигнув умирающего состояния в 1960-е годы получили новую жизнь, когда возникла идея и потребность в искусственном интеллекте.
LUNAR разработан в 1978 году компанией W.A. Woods; он может анализировать, сравнивать и оценивать химические данные о составе лунной породы и почвы, которые накапливались в результате лунных миссий Аполлона, и может ответить на связанный с этим вопрос. В 1980-х годах область вычислительной грамматики стала очень активной областью исследований, которая была связана с наукой о рассуждениях о значении и учете убеждений и намерений пользователя. В период 1990-х, темпы его роста увеличились. Грамматика, инструменты и практические ресурсы, связанные с этим, стали доступны с парсерами.
В период 1990-х, темпы его роста увеличились. Грамматика, инструменты и практические ресурсы, связанные с этим, стали доступны с парсерами.
Исследования по основным и футуристическим темам, таким как устранение неоднозначности смысла слов и статистически окрашенное НЛП, работа над лексикой получили научное направление. К этому поиску его появления присоединились другие важные темы, такие как статистическая обработка языка, извлечение информации и автоматическое суммирование.
Первый чат-бот — ЭЛИЗА
Обсуждение истории нельзя считать полным без упоминания ELIZA, программы чат-бота, которая разрабатывалась с 1964 по 1966 год в Лаборатории искусственного интеллекта Массачусетского технологического института. Он был создан Джозефом Вейценбаумом. Это была программа, основанная на сценарии под названием DOCTOR, который был создан для роджерианского психотерапевта и использовал правила для ответов на вопросы пользователей, основанные на психометрии. Это был один из чат-ботов, способных в то время пройти тест Тьюринга.
Правительство постепенно внедряет современные новые технологии в свою архитектуру. Нажмите, чтобы узнать о роли и использовании NLP в правительстве
Каковы приложения обработки естественного языка?
В наши дни все хотят, чтобы машина говорила, а компьютер может говорить только через нее. Возьмем пример Alexa, диалогового продукта от Amazon. Запрос передается ему посредством голоса, и он может ответить тем же средством, т. е. голосом. Его можно использовать, чтобы спросить что-нибудь, найти что-нибудь, для воспроизведения песен или даже для заказа такси. Кажется, что это магия, но это не из-за какого-то магического заклинания, см. диаграмму ниже. Эта простая диаграмма демонстрирует процедуру обработки естественного языка в Alexa.
Alexa не является единственным примером, и эти говорящие машины, которые широко известны как Chatbot, могут даже управлять сложными взаимодействиями и процессами, связанными с оптимизированным бизнесом, только с их помощью. В прошлом чат-боты использовались только для взаимодействия с клиентами с ограниченными возможностями общения, поскольку они, как правило, основывались на правилах, но после появления обработки естественного языка и ее интеграции с машинным обучением и глубоким обучением теперь чат-бот может обрабатывать множество различных областей, таких как человеческие ресурсы и здравоохранение. Это не единственный случай его использования, когда он меняет правила игры; есть и другие примеры. Давайте кратко рассмотрим их. Ниже приведено описание некоторых вариантов использования.
В прошлом чат-боты использовались только для взаимодействия с клиентами с ограниченными возможностями общения, поскольку они, как правило, основывались на правилах, но после появления обработки естественного языка и ее интеграции с машинным обучением и глубоким обучением теперь чат-бот может обрабатывать множество различных областей, таких как человеческие ресурсы и здравоохранение. Это не единственный случай его использования, когда он меняет правила игры; есть и другие примеры. Давайте кратко рассмотрим их. Ниже приведено описание некоторых вариантов использования.
- Здравоохранение
- Анализ настроений
- Когнитивная аналитика
- Обнаружение спама
- Вербовка
- Разговорная платформа
Здравоохранение
Медицинские службы Amazon Comprehend, которые используются для извлечения сведений о заболеваниях, могут проводить сеансы медитации и отслеживать результаты лечения, используя отчеты о клинических испытаниях, электронные медицинские карты и записи пациентов.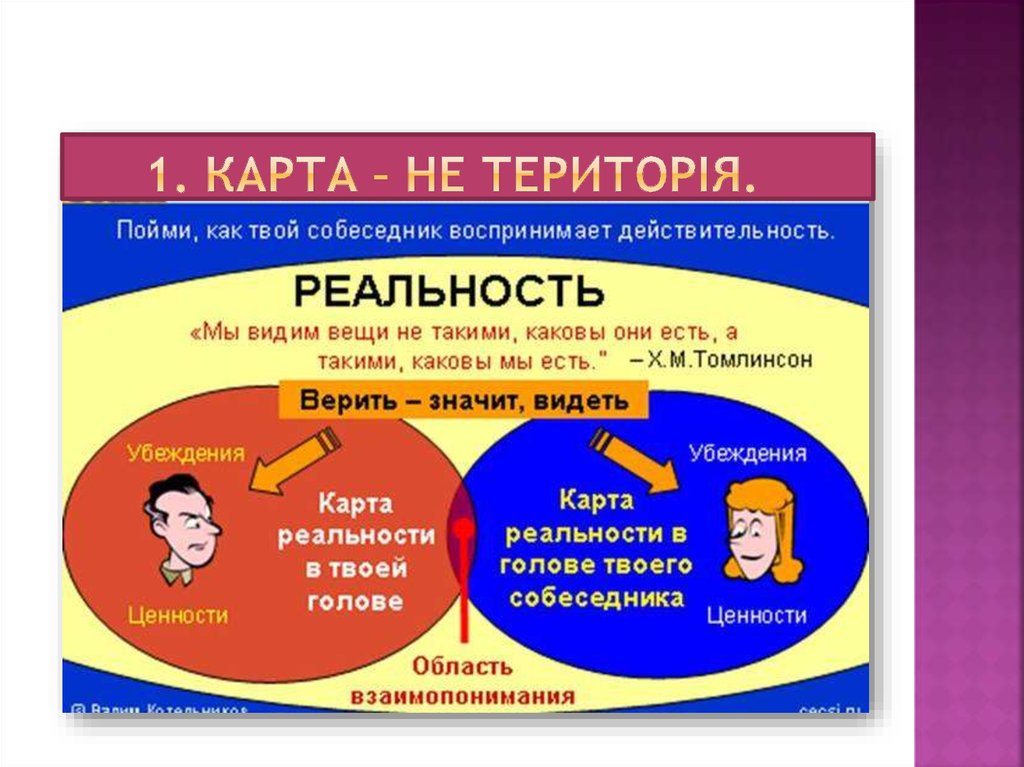 Это пример НЛП в аналитике здоровья, где с помощью языковой обработки возможно прогнозирование различных заболеваний с использованием методов распознавания образов, речи пациента и его электронной медицинской карты.
Это пример НЛП в аналитике здоровья, где с помощью языковой обработки возможно прогнозирование различных заболеваний с использованием методов распознавания образов, речи пациента и его электронной медицинской карты.
Анализ настроений
В настоящее время компании и организации концентрируются на различных способах узнать своих клиентов, чтобы можно было обеспечить индивидуальный подход. Используя анализ настроений (который возможен только с использованием НЛП), можно определить чувства, стоящие за словами. Анализ настроений может предложить много знаний о поведении клиентов и их выборе, которые можно рассматривать как важные факторы, влияющие на принятие решений.
Когнитивная аналитика Это лучший пример сотрудничества различных технологий, но обе они находятся под одной крышей искусственного интеллекта. Возможны диалоговые структуры, которые могут принимать команды с помощью голоса или текста. Используя когнитивную аналитику, теперь возможна автоматизация различных технических процессов, таких как создание технического билета, связанного с технической проблемой, а также обработка ее автоматическим или полуавтоматическим способом. Совместная работа этих методов может привести к автоматизированному процессу решения технических проблем внутри организации или к предоставлению клиенту решения некоторых технических проблем также автоматизированным способом.
Совместная работа этих методов может привести к автоматизированному процессу решения технических проблем внутри организации или к предоставлению клиенту решения некоторых технических проблем также автоматизированным способом.
Получите больше полезных результатов из вашего текста, расширьте возможности интеллектуального поиска для получения результатов и упростите анализ тональности. Источник: Amazon NLP
Обнаружение спама
Гиганты технического мира, такие как Google и Yahoo, используют NLP для классификации и фильтрации электронных писем, подозреваемых в спаме. Этот процесс известен как обнаружение спама и фильтрация спама соответственно. Это приводит к автоматизированному процессу, который может классифицировать электронную почту как спам и останавливать ее для входа в папку «Входящие».
Подбор персонала Он также может использоваться как на этапах поиска, так и на этапах выбора в процессе набора персонала. Фактически, чат-бот также может использоваться для обработки запроса, связанного с работой, на начальном уровне, который также включает определение необходимых навыков для конкретного работа и обработка тестов и экзаменов начального уровня.
Фактически, чат-бот также может использоваться для обработки запроса, связанного с работой, на начальном уровне, который также включает определение необходимых навыков для конкретного работа и обработка тестов и экзаменов начального уровня.
Эта технология и связанные с ней устройства в наши дни приобретают все большую популярность. Alexa, которая была показана выше, является одним из них, но есть Siri от Apple и Ok Google от Google, которые являются примерами тех же вариантов использования технологий.
Каково будущее обработки естественного языка?
Экспоненциальный рост, который, как ожидается, достигнет отметки в 16 миллиардов долларов к 2021 году при совокупном темпе роста 16 % в год. Причиной этого роста является рост числа чат-ботов, стремление узнать мнение клиентов, переход технологии обмена сообщениями от ручного к автоматизированному и многие другие задачи, которые необходимо автоматизировать и в какой-то момент задействовать язык/речь. Хотя, как указано выше, функциональность вращается вокруг языка/речи, которая относится к словам в их базовой необработанной форме. Каким бы ни было средство коммуникации, будь то устное или письменное, слова являются основной фундаментальной единицей функциональности. Но в настоящее время, кажется, есть разница в производительности НЛП, когда он обрабатывает тексты и когда он обрабатывает голос. Эта задача обязательно будет решена в ближайшем будущем. Рассмотрим разные сценарии.
Хотя, как указано выше, функциональность вращается вокруг языка/речи, которая относится к словам в их базовой необработанной форме. Каким бы ни было средство коммуникации, будь то устное или письменное, слова являются основной фундаментальной единицей функциональности. Но в настоящее время, кажется, есть разница в производительности НЛП, когда он обрабатывает тексты и когда он обрабатывает голос. Эта задача обязательно будет решена в ближайшем будущем. Рассмотрим разные сценарии.
Подмножество Искусственного Интеллекта, потребность в котором возрастает с совершенствованием его вспомогательных технологий день ото дня. Нажмите, чтобы узнать о приложениях НЛП для бизнесаЭволюция от взаимодействия человека с компьютером к общению человека с компьютером
Только в случае взаимодействия можно использовать одно средство, которое может быть любым вербальным или невербальным общением . Но для общения необходимо использовать оба средства, вербальные и невербальные вместе. Хотя существует мнение, что с развитием обработки естественного языка и биометрии такие машины, как роботы-гуманоиды, приобретут способность читать выражения лиц, а также языки тела и слова. Для этого необходима интеграция многих современных технологий, таких как распознавание пользователей-людей, анализ настроений, анализ рекомендаций и методы с участием в беседах, что возможно в динамической манере.
Хотя существует мнение, что с развитием обработки естественного языка и биометрии такие машины, как роботы-гуманоиды, приобретут способность читать выражения лиц, а также языки тела и слова. Для этого необходима интеграция многих современных технологий, таких как распознавание пользователей-людей, анализ настроений, анализ рекомендаций и методы с участием в беседах, что возможно в динамической манере.
Область невербальной коммуникации включает язык тела, прикосновения, жесты и выражение лица. Таким образом, чтобы внедрить в игру невербальную коммуникацию, необходимо использовать биометрические данные, такие как распознавание лиц, сканер отпечатков пальцев и сканер сетчатки глаза. В настоящее время использование этой биометрии также становится главной особенностью в области обеспечения безопасности на ноутбуках, планшетах или даже на смартфонах, что также дает уверенность в использовании биометрии для поиска закономерностей в выражениях лица человека для распознавания чувств. и эмоции от него. Точно так же, как разные слова используются для составления целого предложения, различные микровыражения также используются для выражения чувств в разговоре. Эти микровыражения являются ключом к выявлению различий между различными чувствами и эмоциями, и если их можно связать с блоками обработки естественного языка, то эта интеграция может открыть совершенно новый уровень взаимодействия, в результате которого человек взаимодействует с машиной посредством общения
и эмоции от него. Точно так же, как разные слова используются для составления целого предложения, различные микровыражения также используются для выражения чувств в разговоре. Эти микровыражения являются ключом к выявлению различий между различными чувствами и эмоциями, и если их можно связать с блоками обработки естественного языка, то эта интеграция может открыть совершенно новый уровень взаимодействия, в результате которого человек взаимодействует с машиной посредством общения
Каждой душе нужно тело, чтобы выражать себя. Точно так же существует потребность в физической единице, чтобы передать продвижение НЛП в надлежащей и коммерческой среде. Мысленные устройства, такие как iPad, интерактивное телевидение, специализированные разговорные устройства (такие как Siri и Google Home) начали охватывать эту область, но все же это лишь царапина на поверхности, потому что они имеют ограничения, такие как использование определенного диапазона чувств (слышите, говорить, до некоторой степени видеть, но не чувствовать прикосновения). Это взаимодействие должно быть двунаправленным и в него должно быть включено четвертое чувство (осязание); например, человек общается с другим человеком лицом к лицу. Роботы-гуманоиды являются необходимостью такого рода связи, поскольку это может быть тело для запрограммированной искусственной души. Поскольку рост НЛП и биометрии также набирает темпы и точность, эти технологии могут вывести на совершенно новый уровень исследования роботов-гуманоидов, чтобы они могли выражать себя через движения, позы и выражения.
Это взаимодействие должно быть двунаправленным и в него должно быть включено четвертое чувство (осязание); например, человек общается с другим человеком лицом к лицу. Роботы-гуманоиды являются необходимостью такого рода связи, поскольку это может быть тело для запрограммированной искусственной души. Поскольку рост НЛП и биометрии также набирает темпы и точность, эти технологии могут вывести на совершенно новый уровень исследования роботов-гуманоидов, чтобы они могли выражать себя через движения, позы и выражения.
Используйте возможности НЛП на основе ИИ для расширения возможностей предприятий с помощью решений для анализа настроений, извлечения информации, распознавания намерений и категоризации текста. Ознакомьтесь с услугами NLP XenonStack
Целостная стратегия
Чтобы узнать больше об использовании и приложениях обработки естественного языка в различных областях, мы рекомендуем выполнить следующие шаги:
- Узнайте больше о Google Cloud Natural Language Solutions
- Знайте разницу между НЛП, НЛУ и НЛГ
SEM1A5 — Часть 1 — Краткая история НЛП
SEM1A5 — Часть 1 — Краткая история НЛПКраткая история обработки естественного языка
НЛП невероятно старо. Использование компьютера для расчета артиллерийских таблиц и взлома кодов было менее актуальным в течение нескольких лет после 1945 года. Мирное время дало исследователям возможность дать волю своему воображению над новыми приложениями. Примерно до 1960 года было вполне реально написать исчерпывающую историю НЛП с обзорами всех без исключения значимых работ. Однако с тех пор было проведено столько исследований, что писать исчерпывающие истории уже нецелесообразно. Однако можно выделить наиболее влиятельные системы и возникшие тенденции, чем и занимается данный раздел.
Использование компьютера для расчета артиллерийских таблиц и взлома кодов было менее актуальным в течение нескольких лет после 1945 года. Мирное время дало исследователям возможность дать волю своему воображению над новыми приложениями. Примерно до 1960 года было вполне реально написать исчерпывающую историю НЛП с обзорами всех без исключения значимых работ. Однако с тех пор было проведено столько исследований, что писать исчерпывающие истории уже нецелесообразно. Однако можно выделить наиболее влиятельные системы и возникшие тенденции, чем и занимается данный раздел.
Предыстория НЛП
Предложения по механическим переводчикам языков появились еще до изобретения цифрового компьютера. Первым узнаваемым приложением НЛП была система поиска по словарю, разработанная в Биркбек-колледже в Лондоне в 1948 году. Интерес Америки обычно восходит к меморандуму, написанному Уорреном Уивером в 1949 году. Уивер участвовал во взломе кодов во время Второй мировой войны. Его идея была проста: учитывая, что люди всех наций во многом одинаковы (несмотря на то, что они говорят на разных языках), документ на одном языке можно рассматривать как написанный в коде. Как только этот код будет взломан, можно будет вывести документ на другом языке. С этой точки зрения немецкий код был английским.
Как только этот код будет взломан, можно будет вывести документ на другом языке. С этой точки зрения немецкий код был английским.В качестве исследовательской идеи это быстро прижилось, и в США, Великобритании, Франции и Советском Союзе были созданы значительные исследовательские группы по машинному переводу. Ранние американские системы были сосредоточены на переводе с немецкого на английский, потому что с войны нужно было переводить технические документы. Со временем, когда немецкий материал стал считаться устаревшим, пары языков в исследовательских проектах переместились с русского на английский, с русского на французский или с английского на русский и с французского на русский. Холодная война догнала исследования машинного перевода.
Ранние системы машинного перевода были явно неудачными. Хуже того, в конце концов они обрушили враждебность агентств, финансирующих исследования, на головы работников НЛП. Меморандум Уоррена Уивера от 1949 года вдохновил на множество проектов, каждый из которых открывал новые горизонты: в НЛП не было общепризнанной мудрости, не было совокупности знаний и техник, которые можно было бы применить. Первыми работниками часто были математики, которые боролись с примитивными вычислительными машинами. Некоторые первые рабочие были двуязычными, например, носители немецкого языка, эмигрировавшие в США. Их знание обоих языков в их системе предполагало, что они смогут писать программы, которые будут удовлетворительно переводить, по крайней мере, технические тексты. Вскоре выяснилось, что задача, которую они перед собой поставили, чрезвычайно трудна. Язык оказался намного сложнее, чем они предполагали. Что еще хуже, хотя они свободно говорили на своем родном языке, оказалось очень трудно закодировать их знание языка в компьютерной программе.
Очевидным местом для поиска помощи была лингвистика. Литература 1950-х годов показывает растущую осведомленность о работе в основной лингвистике, и для молодых исследователей в области лингвистики стало своего рода тенденцией присоединяться к командам машинного перевода. Хотя открытость к вкладу смежных дисциплин следует приветствовать, неясно, сильно ли она помогла машинному переводу, поскольку подходящих лингвистических теорий просто не существовало. Это изменилось в 1957 году с публикацией Syntactic Structures молодого американского лингвиста, который с тех пор доминирует в теоретической лингвистике, Ноама Хомского. Хомский произвел революцию в лингвистике, возможно, почти в одиночку. Он представил идею порождающей грамматики: описания синтаксических структур на основе правил. Хотя многие не соглашались с идеями Хомского, создавая альтернативные лингвистические формализмы или не соглашаясь с его методами обнаружения лингвистических данных, почти вся работа в области НЛП с 1957 года была отмечена его влиянием.
Это изменилось в 1957 году с публикацией Syntactic Structures молодого американского лингвиста, который с тех пор доминирует в теоретической лингвистике, Ноама Хомского. Хомский произвел революцию в лингвистике, возможно, почти в одиночку. Он представил идею порождающей грамматики: описания синтаксических структур на основе правил. Хотя многие не соглашались с идеями Хомского, создавая альтернативные лингвистические формализмы или не соглашаясь с его методами обнаружения лингвистических данных, почти вся работа в области НЛП с 1957 года была отмечена его влиянием.
Ранние исследователи машинного перевода поняли, что их системы не могут переводить входные тексты без дополнительной помощи. Учитывая скудость лингвистических теорий, особенно до 1957 года, некоторые люди предлагали предварительно редактировать тексты, чтобы отмечать трудности в тексте, например, для устранения неоднозначности слов (например, в английском языке «мяч»). Поскольку системы машинного перевода не могли обеспечить плавный вывод, «целевой» язык необходимо было отредактировать, чтобы превратить его в понятный текст.
Внедрение предварительного и постредактирования текстов, переведенных с помощью машин, привело к идее, что компьютер можно использовать в качестве инструмента для помощи человеку в задачах, которые все еще слишком сложны для выполнения компьютером самостоятельно. При вспомогательном машинном переводе компьютер действует как память, избавляя человека от необходимости знать огромное количество словарного запаса. Бар-Хиллель изучил эту область и пришел к выводу, что полностью автоматический перевод высокого качества (FAHQT) невозможен без знаний. Он просмотрел текущие на тот момент проекты и пришел к выводу, что использовавшиеся ими методы, которые, по сути, перетасовывали пары слов, по своей сути были обречены на провал, даже если их значительно расширить. Причина была проста: люди-переводчики добавляют свое понимание документа, который нужно перевести, к своим знаниям структур языков, с которыми они работают. Остаются некоторые конструкции, которые просто требуют понимания документа или того, как устроен мир, чтобы их можно было правильно перевести. В таком языке, как английский, трудно понять, что нравится говорящему в предложении:
В таком языке, как английский, трудно понять, что нравится говорящему в предложении:
«Она носила маленькие туфли и носки».
намеревался. (Носки тоже были маленькими?) Для многих целей это не имеет значения, но если бы система анализировала показания свидетелей, чтобы инициировать обыск, это могло бы иметь решающее значение.
Комментарии Бар-Хиллеля оказали длительное влияние на восприятие практичности НЛП и, в частности, машинного перевода. Другим губительным фактором была перепродажа систем. Исследовательские проекты должны обеспечивать долгосрочное финансирование, чтобы исследовательские группы оставались вместе. В ситуации, когда несколько команд работают над одной и той же основной областью, крайне важно, чтобы было видно, как они добиваются хорошего прогресса. Спонсорам нравится видеть четкие практические демонстрации результатов их финансирования. Машинный перевод страдал от перепродажи до середины 19 века.60-е годы. Этому не способствовала готовность некоторых представителей прессы придавать (возможно, наивному) оптимистический блеск любому развитию событий. Для машинного перевода именно таким событием стала демонстрация Джорджтаунской системы 7 января 1955 года. Оглядываясь назад на эту систему через сорок лет, она кажется невероятно грубой системой, у которой никогда не было надежды на перевод каких-либо наиболее тщательно подобранных текстов. В то время это приветствовалось как появление практического машинного перевода.
Для машинного перевода именно таким событием стала демонстрация Джорджтаунской системы 7 января 1955 года. Оглядываясь назад на эту систему через сорок лет, она кажется невероятно грубой системой, у которой никогда не было надежды на перевод каких-либо наиболее тщательно подобранных текстов. В то время это приветствовалось как появление практического машинного перевода.
Подсчитано, что к середине 1960-х годов финансирование исследований машинного перевода в США обошлось государству в 20 миллионов долларов. Консультативный комитет по автоматической языковой обработке (ALPAC) подготовил отчет о результатах финансирования и пришел к выводу, что «машинный перевод общенаучного текста не производился и в ближайшее время не ожидается». Финансирование машинного перевода в США было прекращено, и это привело к остановке большей части связанной с ним работы в области немашинного перевода НЛП. Побочным эффектом этого стало прекращение финансирования в других странах, и НЛП вошло в своего рода бездействующую фазу.
НЛП с 1966 по 1980 год
Некоторые истории предполагают, что НЛП практически исчезло со сцены после отчета ALPAC. Это романтическая точка зрения, которая не полностью подтверждается доказательствами. Безусловно, работы по НЛП было гораздо меньше, и исследования в области машинного перевода существенно сократились еще на десять с лишним лет. Однако за пятнадцать лет после отчета ALPAC произошли некоторые важные изменения и системы, некоторые из которых все еще имеют влияние сегодня.Ключевыми событиями были:
- Сети расширенного перехода
- Сеть расширенного перехода (ATN) — это программа для поиска, способная использовать очень мощные грамматики для обработки синтаксиса. Было бы неправильно думать о нем только как об процессоре синтаксиса, потому что это больше, чем просто алгоритм поиска. Он предоставил формализм для выражения знаний о области применения. (Знания записаны в виде расширенных сетей переходов.) Наряду с этим было указано, как использовать эти сети для поиска решений проблем.
 В случае НЛП знание может заключаться в синтаксисе английских предложений, а проблемы могут заключаться в том, чтобы производить синтаксический анализ английских предложений. Область применения может быть совершенно другой, например, планирование перемещений робота на складе.
В случае НЛП знание может заключаться в синтаксисе английских предложений, а проблемы могут заключаться в том, чтобы производить синтаксический анализ английских предложений. Область применения может быть совершенно другой, например, планирование перемещений робота на складе. - Падежная грамматика
- Падежная грамматика представляет собой привлекательный отчет об аспекте семантики. Такие языки, как английский, выражают отношения между глаголами и существительными в основном с помощью предлогов-связок. Рассмотрим следующее предложение:
Джон купил билет для Мэри в кассе Симфонического зала.
Мы знаем из позиции слов Джон и билет , что Джон является агентом, инициирующим действие, и что билет является пациентом (или объектом) действия. Мы знаем, что Мария является бенефициаром действия из-за использования предлога 9.0161 вместо перед ее именем. (Каким был бы смысл предложения, если бы этот предлог был из ?) Местом действия была касса Симфонического зала, на что указывает использование предлога в .
Чарльз Филлмор заметил, что в некоторых языках нет предлогов, но они все же могут кодировать одно и то же значение. Анализ показал, что они использовали разные способы для выражения этой информации, например, использование различных окончаний слов (грамматический падеж) для обозначения роли, которую существительное играло по отношению к глаголу. (В английском языке у нас есть остаток этого метода в притяжательном падеже: «John’s book», где окончание имени John изменено, чтобы показать роль, которую оно играет в предложении.) В других языках использовался жесткий порядок слов. Филлмор предположил, что существует очень небольшое количество «глубоких падежей», которые представляют возможные отношения между глаголом и его существительными. Отдельные языки выражают эти глубокие падежи различными способами, такими как порядок слов, предлоги, словоизменение (т.е. изменение окончаний слов).
Значение предложения для НЛП заключается в том, что оно предоставило относительно легко реализуемую теорию, которая могла бы предоставить много семантической информации с небольшими усилиями по обработке.
Это также способствовало решению одной из неразрешимых проблем машинного перевода: переводу предлогов. - Семантические представления
- В семантической обработке произошло несколько значительных изменений. Шанк и его сотрудники ввели понятие концептуальной зависимости, метод выражения языка в терминах семантических примитивов. Были написаны системы, которые не включали синтаксическую обработку. Работа Quillian над памятью представила идею семантической сети, которая использовалась в различных формах для представления знаний во многих системах. Уильям Вудс использовал идею процедурной семантики в качестве промежуточного представления между системой обработки языка и системой базы данных.
 В случае НЛП знание может заключаться в синтаксисе английских предложений, а проблемы могут заключаться в том, чтобы производить синтаксический анализ английских предложений. Область применения может быть совершенно другой, например, планирование перемещений робота на складе.
В случае НЛП знание может заключаться в синтаксисе английских предложений, а проблемы могут заключаться в том, чтобы производить синтаксический анализ английских предложений. Область применения может быть совершенно другой, например, планирование перемещений робота на складе.
 Это также способствовало решению одной из неразрешимых проблем машинного перевода: переводу предлогов.
Это также способствовало решению одной из неразрешимых проблем машинного перевода: переводу предлогов.Ключевыми системами были:
- ШРДЛУ
- Система SHRDLU Терри Винограда имитировала робота, который манипулирует блоками на столешнице. Он мог обрабатывать такие инструкции, как «Поднимите красную пирамиду», и отвечать на такие вопросы, как «Что содержит синяя коробка?». Важность SHRDLU заключается в том, что он показывает, что синтаксис, семантика и рассуждения о мире могут быть объединены для создания системы, понимающей естественный язык. Это была очень ограниченная система: она могла обрабатывать лишь весьма ограниченный набор предложений. Что еще более важно, он мог понимать только язык, относящийся к ничтожно малой части всего мира: миру блоков. Его сила проистекала из его очень ограниченной области, и любая попытка увеличить масштаб системы привела бы к все более и более менее эффективным системам.
- ЛУННЫЙ
- LUNAR была системой интерфейса базы данных, которая использовала ATN и процедурную семантику Вудса. Он получил свое название от используемой базы данных, которая состояла из информации об образцах лунных пород. Система была неофициально продемонстрирована на Второй ежегодной лунной научной конференции в 1971 году. Ее производительность была весьма впечатляющей: ей удалось безошибочно обработать 78% запросов, а после исправления словарных ошибок эта цифра возросла до 90%. Эта цифра вводит в заблуждение, поскольку система не подвергалась интенсивному использованию. Ученый, который использовал бы его для извлечения информации для повседневной работы, вскоре обнаружил бы, что хочет делать запросы, выходящие за рамки лингвистических возможностей системы.
- СПАСАТЕЛЬ/ЛЕСТНИЦА
- LIFER/ЛЕСТНИЦА — одна из самых впечатляющих систем НЛП. Он был разработан как интерфейс на естественном языке для базы данных с информацией о кораблях ВМС США. В нем использовалась семантическая грамматика (то есть использовались такие ярлыки, как «КОрабль» и «АТРИБУТ», а не синтаксические ярлыки, такие как существительное и глагол ). Это означает, что он был тесно связан с доменом, для которого он был спроектирован аналогично SHRDLU. Тем не менее, разработчики системы использовали семантическую грамматику в своих интересах, встраивая различные удобные для пользователя функции в грамматику. К ним относятся возможность определять новые словарные статьи, определять парафразы (например, чтобы сделать возможными сокращения) и обрабатывать неполный ввод.
 Важность SHRDLU заключается в том, что он показывает, что синтаксис, семантика и рассуждения о мире могут быть объединены для создания системы, понимающей естественный язык. Это была очень ограниченная система: она могла обрабатывать лишь весьма ограниченный набор предложений. Что еще более важно, он мог понимать только язык, относящийся к ничтожно малой части всего мира: миру блоков. Его сила проистекала из его очень ограниченной области, и любая попытка увеличить масштаб системы привела бы к все более и более менее эффективным системам.
Важность SHRDLU заключается в том, что он показывает, что синтаксис, семантика и рассуждения о мире могут быть объединены для создания системы, понимающей естественный язык. Это была очень ограниченная система: она могла обрабатывать лишь весьма ограниченный набор предложений. Что еще более важно, он мог понимать только язык, относящийся к ничтожно малой части всего мира: миру блоков. Его сила проистекала из его очень ограниченной области, и любая попытка увеличить масштаб системы привела бы к все более и более менее эффективным системам. Эта цифра вводит в заблуждение, поскольку система не подвергалась интенсивному использованию. Ученый, который использовал бы его для извлечения информации для повседневной работы, вскоре обнаружил бы, что хочет делать запросы, выходящие за рамки лингвистических возможностей системы.
Эта цифра вводит в заблуждение, поскольку система не подвергалась интенсивному использованию. Ученый, который использовал бы его для извлечения информации для повседневной работы, вскоре обнаружил бы, что хочет делать запросы, выходящие за рамки лингвистических возможностей системы.