Конгруэнтность. Психология. Люди, концепции, эксперименты
Конгруэнтность
Если идеальная самость человека согласуется с его реальным жизненным опытом, он пребывает в состоянии конгруэнтности. Если же между идеальной самостью и фактическим опытом лежит огромная пропасть, то человек неконгруэнтен.
Визуальное представление концепции конгруэнтности
Представление о себе отличается от образа идеальной самости. Наложение незначительно. Самоактуализация проблематична
Представление о себе похоже на образ идеальной самости. Наложение более значительное. Самоактуализация возможна
Абсолютная конгруэнтность встречается крайне редко. По утверждению Роджерса, чем больше представление человека о себе приближается к образу идеальной самости, к которому он стремится, тем более высокая у него будет самооценка и конгруэнтность. Поскольку люди стараются, чтобы их реальное лицо как можно лучше согласовывалось с их представлением о себе, они часто используют психические защитные механизмы, например такие как подавление или отрицание, чтобы уменьшить ощущение угрозы, обычно сопровождающее переживание нежелательных чувств и эмоций.
Кроме того, Роджерс подчеркивал важность других людей в нашей жизни; он считал, что нам необходимо знать, что окружающие воспринимают и оценивают нас позитивно, потому что каждый человек от природы стремится к тому, чтобы его уважали, ценили, любили, относились с симпатией. Отношение значимых для человека людей Роджерс делит на два типа:
1. Безусловное позитивное внимание. Человека принимают таким, каков он есть, особенно его родители, а также люди, мнение которых для него важно, например психотерапевт. В этом случае он не боится пробовать что-то новое и совершать ошибки, даже если их последствия могут оказаться весьма неприятными. Если человек способен самоактуализоваться – значит, он, как правило, был окружен безусловным позитивным вниманием.
2. Обусловленное позитивное внимание.
Человек пользуется позитивным вниманием окружающих не потому, что его любят и уважают, а потому, что он ведет себя так, как они считают правильным, – например, ребенка хвалят за хорошее поведение. Люди, которые всегда стремятся к похвале окружающих, скорее всего, в детстве были окружены обусловленным позитивным вниманием родителей, учителей и других людей.
Люди, которые всегда стремятся к похвале окружающих, скорее всего, в детстве были окружены обусловленным позитивным вниманием родителей, учителей и других людей.Данный текст является ознакомительным фрагментом.
ОБЩАЯ СТРАТЕГИЯ РЕАГИРОВАНИЯ НА КОНГРУЭНТНОСТЬ
ОБЩАЯ СТРАТЕГИЯ РЕАГИРОВАНИЯ НА КОНГРУЭНТНОСТЬ Когда коммуникация пациента инконгруэнтна, когда пациент представляет собой набор несогласующихся между собой пара-сообщений, перед психотерапевтом возникает задача экзистенциального выбора. Действия психотерапевта в
Конгруэнтность на уровне идентичности
Конгруэнтность на уровне идентичности
В этой главе нам предстоит убедиться в своей конгруэнтности как на уровне идентичности, так и на уровне убеждений, чтобы у нас не оказалось двух различных частей, занимающих одно и то же пространство.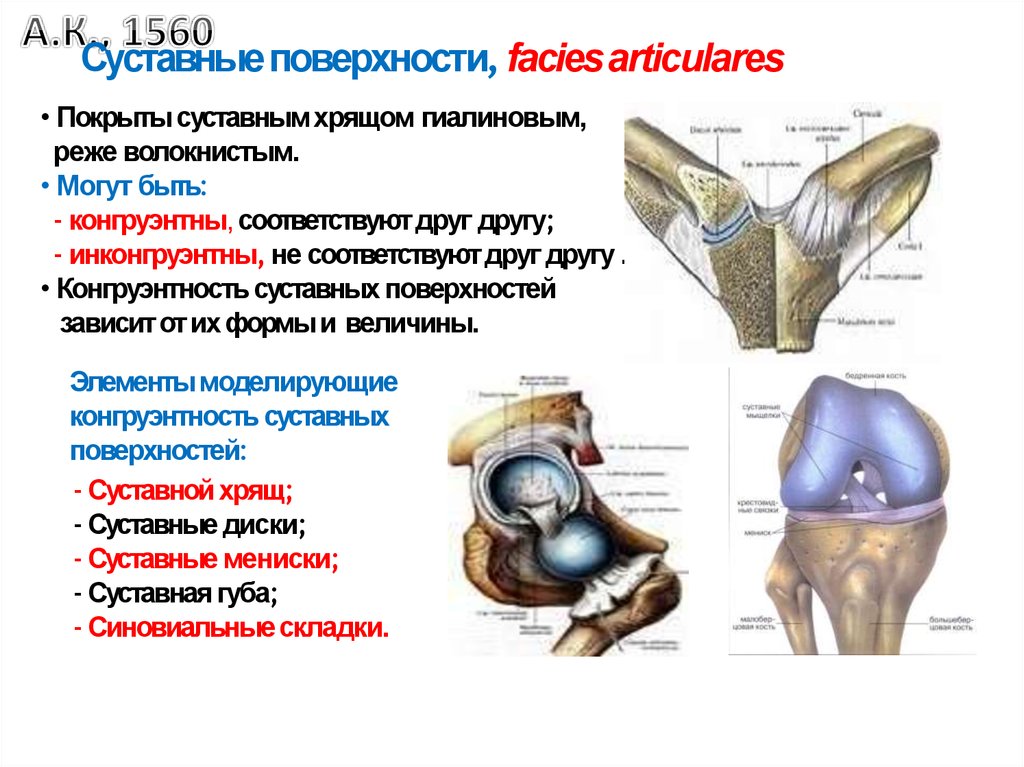 Мы часто обнаруживаем, что после
Мы часто обнаруживаем, что после
Конгруэнтность — Совпадение Слов и Жестов
Конгруэнтность — Совпадение Слов и Жестов Если бы вы были собеседником человека, показанного на рис. 4, и попросили его выразить свое мнение относительно того, что вы только что сказали, на что он бы ответил, что с вами не согласен, то его невербальные сигналы были бы
Книга 5. «Клёвость» и конгруэнтность
Книга 5. «Клёвость» и конгруэнтность Метасообщения человека всегда говорят о том, действует ли он опираясь на собственную личность, в собственной реальности или же он реагирует на социальное давление, и под его воздействием, меняет собственное поведение. МыслиКонгруэнтность и неконгруэнтность
Конгруэнтность и неконгруэнтность
Самые тяжелые последствия вызывает нарушение отношений, называемое неконгруэнтной коммуникацией. Бэндлер, Гриндер и Сатир так описывают это явление:»Как на этапе формирования так и во время цикла калибровки, передающий ведет себя
Бэндлер, Гриндер и Сатир так описывают это явление:»Как на этапе формирования так и во время цикла калибровки, передающий ведет себя
Конгруэнтность
Конгруэнтность В общем и целом Джесси понимает, что залог успеха торговли – умение обращаться с человеческим мозгом. Теперь она уверена, что продавать продукты и услуги нужно только тем людям, которым это пойдет на пользу, – потому что так велит здравый смысл, – и
322 гр., спец. СМ. Вычислительный практикум (моделирование распределений) [StatMod.Ru Wiki]
Содержание
322 гр., спец. СМ. Вычислительный практикум (моделирование распределений)
Темы прошедших занятий
Задачки и материалы к ним
Прошлогодние темы
Результаты сдачи заданий
Литература (старая)
Литература (новая)
Место и время проведения: вторник, первая пара, ауд.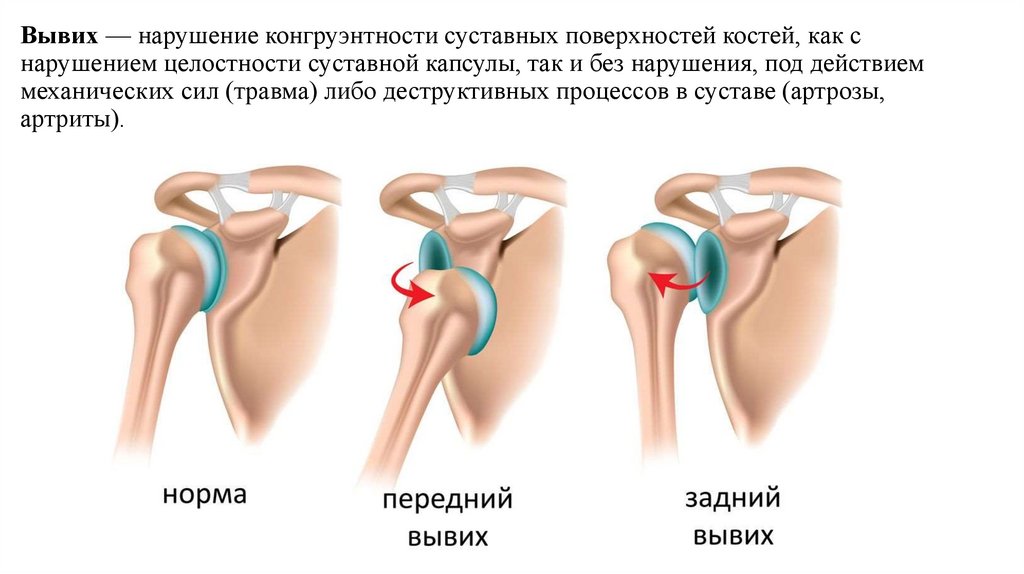 2408
2408
Преподаватель: Звонарев Никита nikitazvonarev@gmail.com
Темы прошедших занятий
12/02/19 Введение. Мультипликативный датчик, RANDU
- 19/02/19 Линейный конгруэнтный датчик. Гиперплоскости и волновое число. Взлом линейного конгруэнтного датчика.
26/02/19 Датчики Фибоначчи. Комбинированные генераторы. Jump Ahead: быстрое возведение матрицы в степень, etc.
05/03/19 Известные батареи тестов. Birthday spacings test и другие тесты. Немного про Mersenne Twister. Идеи семейства PCG.
12/03/19 ГПСЧ в C++ (пример). Моделирование в выпуклом и невыпуклом многоугольнике. Тривиальная аналитическая геометрия, алгоритмы Джарвиса, Грэхэма, «отрезания ушей».
19/03/19 ГПСЧ в R. Моделирование случайных перестановок и подвыборок.
26/03/19 Многомерное нормальное распределение. Eigendecomposition, разложение Холецкого. Равномерное распределение на сфере, в шаре, в эллипсоиде.

02/04/19 Приём задач
09/04/19 Введение в динамическое программирование (основы, динамика на подотрезках/подмножествах, расстояние Левенштейна и пр.).
16/04/19 Введение в алгоритмы на графах (способы хранения, DFS/BFS, поиск наикратчайшего пути в 0-1, Дейкстра с кучей/без кучи).
23/04/19 Пропуск
30/04/19 Приём задач
07/05/19 Приём задач
14/05/19 Приём задач
21/05/19 Приём задач
11/06/19 Зачёт

Задачки и материалы к ним
Из двух задач с одинаковым номером можно взять любую (на ваш выбор). Главное – сдать её до зачёта :).
1 а). Трёхмерные интегралы и RANDU. Взять плохой датчик и продемонстрировать, что М-К для одно- или двумерного интеграла работает, а для трёхмерного ломается. Достаточно выбрать подходящую (объяснял на паре) ограниченную функцию на $[0, 1]^k$, у которой вы можете взять интеграл аналитически.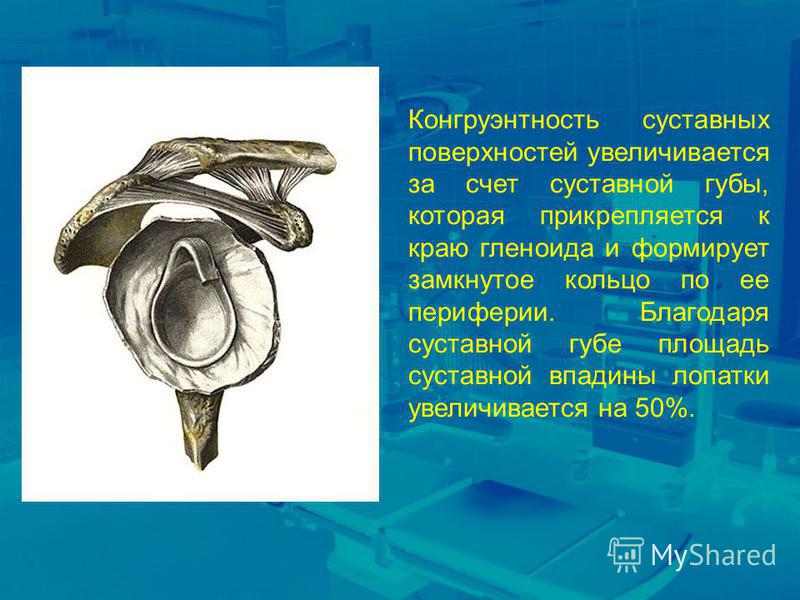 7) раз, проверить распределение перестановок с помощью распределения позиции i-го элемента и числа циклов длины k для малых и больших длин перестановок (пользуясь соотношениями, упомянутыми на паре, и критерием Хи-квадрат).
7) раз, проверить распределение перестановок с помощью распределения позиции i-го элемента и числа циклов длины k для малых и больших длин перестановок (пользуясь соотношениями, упомянутыми на паре, и критерием Хи-квадрат).
Замечание: проверку распределения проще сделать в R, сгенерировав готовый файл со статистиками.
5 а) Реализовать моделирование многомерного нормального распределения с невырожденной и вырожденной (несколько примеров) ковариационной матрицей, без использования готовой функций (для моделирования в R разрешён только rnorm()). Продемонстрировать проекции на различные плоскости на рисунке.
5 б) Реализовать равномерное распределение в d-мерном шаре и на сфере (несколько примеров). Продемонстрировать проекции на различные плоскости на рисунке.
По желанию можно попробовать продемонстрировать результаты с помощью пакета rgl.
Прошлогодние темы
13/02/18 Введение. Мультипликативный датчик (начало), RANDU
20/02/18 Линейный конгруэнтный датчик.
Гиперплоскости и волновое число. Датчики Фибоначчи.27/02/18 Комбинированные генераторы. Jump Ahead: быстрое возведение матрицы в степень, etc.
06/03/18 Известные батареи тестов. Birthday spacings test и другие тесты. Немного про Mersenne Twister. Идеи семейства PCG.
13/03/18 Моделирование в выпуклом и невыпуклом многоугольнике. Тривиальная аналитическая геометрия, алгоритмы Джарвиса, Грэхэма, «отрезания ушей».
20/03/18 ГПСЧ в Cpp. Моделирование случайных перестановок и подвыборок.
27/03/18 ГПСЧ в R. Многомерное нормальное распределение. Eigendecomposition, разложение Холецкого. Равномерное распределение на сфере, в шаре, в эллипсоиде.
03/04/18 сдача заданий
10/04/18 Введение в Python 3 и сдача заданий
17/04/18 Продолжение Python 3 и сдача заданий
24/04/18 сдача заданий
01/05/18 День труда (выходной)
08/05/18 сдача заданий
15/05/18 сдача заданий
22/05/18 зачёт неофициальный
 Гиперплоскости и волновое число. Датчики Фибоначчи.
Гиперплоскости и волновое число. Датчики Фибоначчи.Результаты сдачи заданий
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 1) Горшечникова Влада | + | + | + | + | + |
| 2) Магдич Лиза | + | + | + | + | + |
| 3) Абильдаев Темирлан | + | + | + | + | + |
| 4) Капаца Дейвид | + | + | + | + | + |
| 5) Полшков Виталий | + | + | + | + | + |
Литература (старая)
Fishman G.
S. Monte-Carlo. Concepts, Algorithms and Applications Про методы Монте-Карло, моделирование случайных величин, генераторы. Отличное введение.Schneier B. Applied Cryptography Если кто-то интересуется криптографическим аспектом моделирования случайных чисел, то надо начать с этой книги.
Knuth D. The Art of Computer Programming, volume II, chapter 3 (Random numbers) Про генераторы, фундаментально
McCallum Q.E., Weston S. Parallel R. Data Analysis in the Distributed World Параллельное программирование на R
Akritas A.G. Elements of Computer Algebra With Applications Об алгоритмах компьютерной алгебры (проверка на простоту, разложение на множители, характериситческие многочлены и прочее). Сама книга достаточно редкая, но ее русский перевод (Основы компьютерной алгебры с приложениями, 1994) найти очень легко.
Shoup V. A Computational Introduction to Number Theory and Algebra Более современная книга по вычислительной алгебре
Василенко, О.
Н. Теоретико-числовые алгоритмы в криптографии
 S. Monte-Carlo. Concepts, Algorithms and Applications Про методы Монте-Карло, моделирование случайных величин, генераторы. Отличное введение.
S. Monte-Carlo. Concepts, Algorithms and Applications Про методы Монте-Карло, моделирование случайных величин, генераторы. Отличное введение. Н. Теоретико-числовые алгоритмы в криптографии
Н. Теоретико-числовые алгоритмы в криптографииЛитература (новая)
Melissa E. O’Neill. PCG: A Family of Simple Fast Space-Efficient Statistically Good Algorithms for Random Number Generation
Richard Arratia and Simon Tavare. The Cycle Structure of Random Permutations The Annals of Probability. Vol. 20, No. 3 (Jul., 1992), pp. 1567-1591
На ту же тему. Статья в блоге Теренса Тао The number of cycles in a random permutation
study/spring2019/sm_sim_pract.txt · Последнее изменение: 2019/06/05 23:42 — nikita
НаверхПростая английская Википедия, бесплатная энциклопедия
Из Простая английская Википедия, бесплатная энциклопедия
Пример соответствия. Два треугольника слева равны, а третий подобен им. Последний треугольник не подобен и не конгруэнтен ни одному из других. Обратите внимание, что конгруэнтность позволяет изменять некоторые свойства, такие как положение и ориентация, но оставляет неизменными другие, такие как расстояние и углы. Неизменяемые свойства называются инвариантами.
Неизменяемые свойства называются инвариантами.
В геометрии две фигуры или объекта равны F {\ displaystyle F} и F ‘{\ displaystyle F’} (записывается как F ≅ F ‘{\ displaystyle F \ cong F’}) [1] , если они имеют одинаковую форму и размер или если один из них имеет ту же форму и размер, что и зеркальное отражение другого. [2]
Более формально два множества точек называются конгруэнтными тогда и только тогда, когда одно может быть преобразовано в другое с помощью изометрии. [3] Для изометрии используются жестких движений .
Это означает, что две геометрические фигуры конгруэнтны, если один объект можно переместить, повернуть или отразить — но не изменить размер — так, чтобы он точно совпадал с другим объектом. [4] Если одну из фигур можно переместить или повернуть так, чтобы она встала точно на место другой, то эти две фигуры конгруэнтны. Если один из объектов должен изменить свой размер, то два объекта не конгруэнтны: их просто называют подобными.
Например, две различные плоские фигуры на листе бумаги конгруэнтны, если мы можем вырезать их, а затем полностью сопоставить (здесь разрешено переворачивать бумагу).
Конгруэнтные многоугольники — это многоугольники, которые, если сложить правильный многоугольник пополам, являются конгруэнтными многоугольниками. [ нужно объяснить ]
- Все квадраты с одинаковой длиной сторон конгруэнтны.
- Все равносторонние треугольники, имеющие одинаковую длину сторон, конгруэнтны.
- Два угла и сторона между ними равны у двух треугольников (конгруэнтность ASA)
- Два угла и сторона не между ними одинаковы в обоих треугольниках (конгруэнтность AAS)
- Все три стороны обоих треугольников одинаковы (конгруэнтность SSS)
- Две стороны и угол между ними делают два треугольника конгруэнтными (конгруэнтность SAS)
Как получить новые конгруэнтные формы[изменить | изменить источник]
Ниже приведены несколько правил, позволяющих сделать новые формы конгруэнтными исходным:
- Если мы сдвинем геометрическую форму в плоскости, то получим форму, конгруэнтную исходной.
- Если мы будем вращать, а не сдвигать, то мы также получим форму, конгруэнтную исходной.
- Даже если мы возьмем зеркальное отражение исходной формы, мы все равно получим конгруэнтную форму.
- Если мы объединим три действия одно за другим, мы все равно получим конгруэнтные формы.
- Конгруэнтных фигур больше нет. В частности, если форма конгруэнтна исходной, то ее можно достичь с помощью трех действий, описанных выше.

Соотношение, состоящее в том, что форма конгруэнтна другой форме , имеет три известных свойства:
- Если мы оставим первоначальную форму на ее исходном месте, то она конгруэнтна самой себе. Это свойство называется рефлексивностью .
- Например, если приведенный выше сдвиг не является правильным сдвигом, а только сдвигом, совершающим движение нулевой длины. Или, аналогично, если указанное выше вращение не является правильным вращением, а только вращением на нулевой угол.

- Если форма конгруэнтна другой форме, то эта другая форма также конгруэнтна исходной. Это поведение, это свойство называется симметрией .
- Например, если мы сдвинем назад, или повернем назад, или зеркально обратим новую форму к исходной, то исходная форма конгруэнтна новой.
- Если форма C конгруэнтна форме B , а форма B конгруэнтна исходной форме A , то форма C также конгруэнтна исходной форме A . Это свойство называется транзитивностью .
- Например, если применить сначала сдвиг, а затем поворот, то получившаяся новая форма по-прежнему будет конгруэнтна исходной.
Три известных свойства, рефлексивность , симметрия
и транзитивность , вместе составляют понятие эквивалентности . Следовательно, свойство конгруэнтность является одним из видов отношения эквивалентности между формами плоскости.
- Равенство (математика)
- Подобие (геометрия)
- ↑ «Сборник математических символов». Математическое хранилище . 01.03.2020. Проверено 21 сентября 2020 г. .
- ↑ Клэпхэм, К.; Николсон, Дж. (2009). «Оксфордский краткий математический словарь, конгруэнтные фигуры» (PDF) . Эддисон-Уэсли. п. 167. Проверено 1 сентября 2013 г.
{{цитировать в Интернете}}: CS1 maint: URL-статус (ссылка) - ↑ Вайсштейн, Эрик В. «Геометрическая конгруэнтность». mathworld.wolfram.com . Проверено 21 сентября 2020 г. .
- ↑ «Конгруэнтность».
Улучшение устранения неоднозначности именованных сущностей с помощью связанности сущностей в Википедии | Уилл Ситон
Предложение о «конгруэнтности именованных объектов»
Авторы: Уилл Ситон, Йоханнес Колберг, Руочен Чжао, Хардик Гупта
В этой статье описывается исследование, проведенное для курса Capstone Research Гарвардского университета в Институте прикладных вычислительных наук. Мы благодарим Криса Таннера и Уилла Клейбо за их руководство и Габриэля Алтая из Kensho Technologies за его партнерство и поддержку.
Мы благодарим Криса Таннера и Уилла Клейбо за их руководство и Габриэля Алтая из Kensho Technologies за его партнерство и поддержку.
Устранение неоднозначности именованных объектов (NED) — это исследовательская область обработки естественного языка (NLP), направленная на связывание ссылки в единице текста с соответствующей сущность в какой-либо базе знаний, например узел в графе знаний. Точная NED имеет решающее значение для современных технологических компаний, чтобы обрабатывать и связывать документы, отчеты, пресс-релизы и другие письменные материалы со значимой контекстной информацией с записями в базах знаний, чтобы улучшить понимание объекта для исследовательских и коммерческих целей.
В то время как традиционные подходы НЛП к проблеме были сосредоточены на ранних стадиях таких конвейеров данных, таких как распознавание именованных объектов, нормализация строк и контекстные окна, недавние исследования начали сосредотачиваться на сравнении самих именованных объектов в контекстуальном окне, таком как одиночное окно. предложение — для лучшего предсказания ссылок. Определение силы связи между именованными сущностями в контекстном окне включает в себя расчет того, что мы называем конгруэнтностью именованных сущностей, или контекстуальной и семантической связанности именованных сущностей. В сотрудничестве с Kensho Technologies мы разрабатываем несколько методологий для включения конгруэнтности в NED с использованием данных Викимедиа с открытым исходным кодом и демонстрируем их потенциал для повышения производительности в задачах устранения неоднозначности сущностей.
предложение — для лучшего предсказания ссылок. Определение силы связи между именованными сущностями в контекстном окне включает в себя расчет того, что мы называем конгруэнтностью именованных сущностей, или контекстуальной и семантической связанности именованных сущностей. В сотрудничестве с Kensho Technologies мы разрабатываем несколько методологий для включения конгруэнтности в NED с использованием данных Викимедиа с открытым исходным кодом и демонстрируем их потенциал для повышения производительности в задачах устранения неоднозначности сущностей.
Kensho — ведущая компания в области искусственного интеллекта и машинного обучения, входящая в состав S&P Global с момента приобретения в 2018 году в ходе крупнейшего на сегодняшний день приобретения в области ИИ в истории. Одним из их основных предложений является Kensho Link, продукт, который позволяет быстро получать данные компании и точно связываться с идентификаторами компаний S&P Global. Это позволяет компаниям быстро создавать уникальную и мощную базу знаний, объединяя свои собственные данные с данными исследований S&P мирового класса. Их опыт и длительное сотрудничество с Институтом прикладных вычислительных наук Гарвардского университета помогли сформировать этот исследовательский вопрос.
Это позволяет компаниям быстро создавать уникальную и мощную базу знаний, объединяя свои собственные данные с данными исследований S&P мирового класса. Их опыт и длительное сотрудничество с Институтом прикладных вычислительных наук Гарвардского университета помогли сформировать этот исследовательский вопрос.
Чтобы лучше понять цель устранения неоднозначности именованных объектов, полезно поместить его в качестве последнего шага в более длинном конвейере НЛП, который начинается с распознавания именованных объектов. Распознавание именованных объектов идентифицирует в единице текста слово или слова, которые представляют объект или объект, например имена, организации, местоположения или другие имена собственные.
Выделенные слова являются примером сущностей, идентифицированных с помощью распознавания именованных сущностей. После идентификации именованного объекта его необходимо сопоставить с соответствующим узлом в базе знаний, чтобы дополнить эту базу знаний документацией из первоисточника и улучшить понимание узла. Самый простой способ связать именованный объект — это прямое сопоставление строк. Если именованный объект « Гарвардский университет », весьма вероятно, что он ссылается на узел « Гарвардский университет ». Но язык редко бывает таким ясным, и именованные сущности можно распознать в таких строках, как «9».0165 университет » или « Багровый ». Эффективный конвейер NED также надлежащим образом свяжет эти именованные объекты с узлом « Гарвардский университет ».
Самый простой способ связать именованный объект — это прямое сопоставление строк. Если именованный объект « Гарвардский университет », весьма вероятно, что он ссылается на узел « Гарвардский университет ». Но язык редко бывает таким ясным, и именованные сущности можно распознать в таких строках, как «9».0165 университет » или « Багровый ». Эффективный конвейер NED также надлежащим образом свяжет эти именованные объекты с узлом « Гарвардский университет ».
Давайте продолжим попытки сопоставить « университет » с правильным узлом базы знаний. После распознавания того, что это именованный объект, мы можем создать 90 165 пул 90 166 из 90 165 узлов-кандидатов 90 166 в базе знаний, к которой может относиться эта фраза. Каждый узел-кандидат должен иметь показатель достоверности, связанный с предполагаемой вероятностью его правильности. Мы устраняем неоднозначность значения «университета», делая один выбор из этого пула кандидатов в качестве нашего прогноза узла.
Базовая версия устранения неоднозначности включала бы простой выбор кандидата с наибольшей априорной вероятностью независимо для каждого именованного объекта в единице текста. Наша команда решила показать, что модели могут лучше устранять неоднозначность, включив «соответствие » или контекстную связь между кандидатами на именованные объекты в одном предложении и обновив наши предыдущие оценки, прежде чем делать окончательный прогноз. Мы тестируем методы вычисления конгруэнтности, которые включают сходство текста, сходство сущностей и близость графа знаний — все это разные меры родства.
Связанность кандидатов должна повышать правильный ответ с низкой априорной вероятностью, чтобы он стал предсказанием. AIDA CoNLL-YAGO Наш тестовый набор данных представляет собой аннотированный вручную набор данных AIDA CoNLL-YAGO (ACY), предоставленный Институтом информатики им. Макса Планка. Он был создан для статьи института EMNLP 2011 года «Надежное устранение неоднозначности именованных объектов в тексте» и содержит распознаваемые именованные объекты и ручные назначения страниц Википедии. Использование этого набора данных означает, что для нас выполняется распознавание именованных объектов, и мы можем сосредоточиться на последующей задаче устранения неоднозначности. Наша цель — правильно предсказать аннотированную страницу Википедии, на которую ссылается каждый именованный объект в наборе данных ACY.
Макса Планка. Он был создан для статьи института EMNLP 2011 года «Надежное устранение неоднозначности именованных объектов в тексте» и содержит распознаваемые именованные объекты и ручные назначения страниц Википедии. Использование этого набора данных означает, что для нас выполняется распознавание именованных объектов, и мы можем сосредоточиться на последующей задаче устранения неоднозначности. Наша цель — правильно предсказать аннотированную страницу Википедии, на которую ссылается каждый именованный объект в наборе данных ACY.
В феврале 2020 года Kensho публично выпустила усовершенствованную версию базы знаний Wikimedia с открытым исходным кодом, структурированную специально для задач НЛП. Набор данных состоит из трех отдельных слоев: необработанный английский текст страницы Википедии, текст Википедии с гиперссылками на другие страницы и граф реляционных знаний страниц и их формальных отношений друг с другом. Как будет показано позже, мы используем эти гиперссылки для понимания связей между текстом и страницей, а граф знаний — для изучения взаимосвязи именованных сущностей.
Как будет показано позже, мы используем эти гиперссылки для понимания связей между текстом и страницей, а граф знаний — для изучения взаимосвязи именованных сущностей.
Чтобы сравнить сходство именованных сущностей, мы используем пакет Wikipedia2Vec, разработанный и поддерживаемый Studio Ousia. Этот пакет предоставляет векторные вложения, обученные на базе данных Википедии, для сущностей слов и , представляющих целые страницы Википедии. Векторные вложения — это числовые представления слов и/или страниц, которые позволяют проводить прямое сравнение родства на основе их расстояний в скрытом семантическом пространстве вложений с использованием, например, простых парных метрик, таких как косинусное или евклидово расстояние. Хотя встраивание может быть дорогостоящим в вычислительном отношении, методы трансферного обучения позволяют исследователям НЛП, таким как мы, загружать и развертывать высокоинформативные предварительно обученные вложения для новых случаев использования.
Studio Ousia реализует обычную модель пропуска грамм, такую как word2vec, для изучения вложений слов. Для встраивания сущностей совместно оптимизируются три подмодели, как описано в Yamada et al. (2016) и обобщены на изображении ниже.
Введение в Wikipedia2Vec.Совместное использование всех трех подмоделей означает, что вложения сущностей инкапсулируют как текстовый контекст для именованной сущности, так и графическую связанность с ее графом знаний. Таким образом, сравнение встраивания сущностей становится более простым способом рассмотрения реляционного сходства, избегая при этом высокой вычислительной сложности, с которой мы и другие исследователи столкнулись при прямой обработке больших графов знаний, особенно таких больших, как Википедия.
Эти встраивания доступны с размерами 100, 300 и 500, и влияние глубины измерения на производительность исследуется на различных этапах нашей разработки.
Во-первых, мы структурируем набор данных AIDA CoNLL-YAGO, чтобы включить информацию об определенном нами окне контекста, включая уникальный id_предложения для каждого предложения и список именованных сущностей в одном предложении.
Во-вторых, мы создаем пулы кандидатов для каждого именованного объекта, которые предоставляют пять наиболее вероятных страниц Википедии и связанную с ними априорную вероятность каждой страницы-кандидата. Мы тестируем два метода генерации пула кандидатов: A) сходство text<>entity vector и B) статистика анкорных ссылок.
В-третьих, мы вычисляем конгруэнтность именованных объектов, обновляем априорные вероятности изолированных кандидатов с помощью этой метрики родства и делаем прогноз устранения неоднозначности для каждого именованного объекта. Мы тестируем три метода конгруэнтного устранения неоднозначности: A) центральность комбинации, B) сходство сущности <> вектора сущности и C) близость графа знаний.
Обзор исследовательского конвейера Для именованного объекта в текстовой единице мы создаем список возможных кандидатов на страницы Википедии (сущности), на которые может ссылаться именованный объект. Мы ранжируем этих кандидатов по рассчитанной априорной вероятности того, что они будут правильным выбором.
Мы ранжируем этих кандидатов по рассчитанной априорной вероятности того, что они будут правильным выбором.
Этот метод идентифицирует ссылки-кандидаты, вычисляя сходство между внедренным представлением текстовой строки именованного объекта и объектом страницы Википедии. Мы используем API Wikipedia2Vec для выполнения этих расчетов сходства с помощью его функции most_similar_by_vector .
Пример запроса API Wikipedia2Vec. Функция требует поиска текстовой строки в словаре Wikipedia2Vec, чтобы вернуть представление слова (в его классовой или векторной форме) перед запросом с этим. Это ограничение создает две проблемы. Во-первых, слово в нашем тестовом наборе данных, особенно редкое имя, может оказаться «вне словарного запаса» и не появиться в обученном корпусе слов Wikipedia2Vec. В этом случае он не сможет вернуть результат. Во-вторых, для обработки именованных объектов, состоящих из нескольких слов, мы должны взять среднее значение векторного представления каждого составного слова (как в приведенном выше примере) и выполнить поиск с помощью этого производного вектора.
В результате этих двух проблем этот метод оказался неудачным при сравнении вектора текста именованного объекта с векторами объектов из Википедии. Используя 100d встраивания, мы создали пулы кандидатов, содержащие правильный ответ только в 34,9% случаев. Если мы возьмем наиболее похожего кандидата в этом пуле в качестве прогноза, мы достигли точности прогноза всего 18,82%.
Увеличение сложности вектора не помогло. И 300-, и 500-мерные вложения не смогли дать нам более 50% покрытия правильного ответа. Покрытие в этом контексте означает, что пул кандидатов содержит правильную сущность, даже если это не было нашим окончательным прогнозом.
Представление именованного объекта в виде встраивания слов было недостаточно информативным для обеспечения точного соответствия нашим предварительно обученным вложениям сущностей.
Статистика по якорным ссылкам Этот второй метод использует присущую Википедии структуру данных, чтобы понять, как люди могут ссылаться на страницу. «Якорная ссылка» — это текстовая строка на странице Википедии, которая ведет гиперссылкой на другую страницу Википедии.
«Якорная ссылка» — это текстовая строка на странице Википедии, которая ведет гиперссылкой на другую страницу Википедии.
Набор данных Викимедиа, полученный от Kensho, структурирует эти якорные ссылки, чтобы их было легко найти. Мы также нормализуем якорные ссылки, чтобы лучше изолировать различные способы ссылки на одну и ту же страницу и обеспечить лучшее сравнение с текстовой строкой именованного объекта. Для каждой пары якорной ссылки на страницу Википедии мы рассчитываем частоту появления этого якорного текста, ссылающегося на сопоставленную страницу, и общую популярность связанной страницы среди зрителей. Эти статистические данные позволяют нам объявить определенные парные ссылки более вероятными, чем другие, переводя количество раз, когда «университет» ссылается на страницу Википедии для «Гарвардского университета», в процент от количества раз, когда «университет» ссылается на любую страницу. . Эта доля представляет собой априорную вероятность того, что анкорный текст « университет » ссылается на сущность « Гарвардский университет ».
Оба определения априорной вероятности — частота, с которой строка ссылается на страницу, или популярность просмотров этой страницы — приводят к высоким показателям охвата; частота ссылок достигает охвата 90%, а популярность страницы достигает 86%. Принимая наиболее вероятного кандидата в пуле в качестве нашего прогноза, частота ссылок и популярность страницы достигают точности прогноза 72,03% и 61,87%.
Мы продолжаем использовать только пулы кандидатов, сгенерированные статистикой ссылок привязки для частоты ссылок. Затем мы применяем различные методы конгруэнтности, чтобы улучшить предсказание устранения неоднозначности при выборе лучшего кандидата для каждого именованного объекта. Мы экспериментировали как с косвенным, так и с прямым включением априорных вероятностей.
Правильный ответ в первых двух рейтингах более чем в 90% случаев. Косвенное включение априорных значений включает в себя эквивалентное рассмотрение кандидатов после того, как они преодолели порог для попадания в первую N. Прямое включение априорных значений включает математическое объединение вероятностей кандидатов с конгруэнтностью набора кандидатов для дисконтирования или обновления окончательной вероятности. Во всех случаях прямое включение априорных ссылок превзошло косвенное включение, учитывая большой перекос верхнего ранга, обеспечиваемый статистикой якорных ссылок. Как видно на изображении, правильный ответ находится в верхней позиции 9раз из 10, со средней априорной вероятностью 88%.
Прямое включение априорных значений включает математическое объединение вероятностей кандидатов с конгруэнтностью набора кандидатов для дисконтирования или обновления окончательной вероятности. Во всех случаях прямое включение априорных ссылок превзошло косвенное включение, учитывая большой перекос верхнего ранга, обеспечиваемый статистикой якорных ссылок. Как видно на изображении, правильный ответ находится в верхней позиции 9раз из 10, со средней априорной вероятностью 88%.
Наш первый метод включал идентификацию каждой уникальной комбинации кандидатов в именованных сущностях предложения и вычисление репрезентативного «вектора центроида» вложений в эту комбинацию. Затем мы определяем расстояние между каждым кандидатом комбинации и центроидом этой комбинации и выбираем комбинацию с наименьшим средним расстоянием в качестве нашего прогноза.
Этот метод работал плохо при использовании косинусного сходства в качестве показателя попарного расстояния, но улучшался при использовании евклидова расстояния. Несмотря на это улучшение, общая точность прогнозирования по-прежнему снизилась на два процентных пункта до 70%. Возможное объяснение заключается в том, что векторное пространство настолько многомерно, что косинусные углы имеют бесконечно малые вариации, или что общее среднее значение снижает влияние высоконадежных пар, которые обеспечивают самый сильный сигнал для точных прогнозов.
Несмотря на это улучшение, общая точность прогнозирования по-прежнему снизилась на два процентных пункта до 70%. Возможное объяснение заключается в том, что векторное пространство настолько многомерно, что косинусные углы имеют бесконечно малые вариации, или что общее среднее значение снижает влияние высоконадежных пар, которые обеспечивают самый сильный сигнал для точных прогнозов.
Наш второй метод включал итеративную идентификацию наиболее похожих сущностей с использованием схожести векторов сущностей <>, которая включает близость графа в исходной подгонке векторов вложений, как описано ранее, для расчета метрики конгруэнтности. Мы рекурсивно вычисляем конгруэнтность всех попарных кандидатов для всех именованных сущностей в одном предложении, дисконтируем метрику конгруэнтности на среднюю априорную вероятность этой пары и итеративно предсказываем следующего наиболее конгруэнтного кандидата для каждой именованной сущности. В частности, мы сначала идентифицируем наиболее конгруэнтную пару, а затем, предполагая, что эта пара истинна, вычисляем наиболее конгруэнтного кандидата среди уже предсказанных кандидатов до тех пор, пока не будет выбран один лучший кандидат для всех именованных сущностей.
В частности, мы сначала идентифицируем наиболее конгруэнтную пару, а затем, предполагая, что эта пара истинна, вычисляем наиболее конгруэнтного кандидата среди уже предсказанных кандидатов до тех пор, пока не будет выбран один лучший кандидат для всех именованных сущностей.
Этот метод сравнения с использованием вложений 100d повышает точность предсказания устранения неоднозначности именованного объекта в диапазоне 2,4–3,7% в зависимости от количества именованных объектов в предложении.
Наш метод генерации пула кандидатов помещает правильный ответ в список возможностей примерно в 90% случаев. Это становится нашей максимально возможной прогностической точностью на последующем этапе, потому что независимо от того, насколько хорош наш метод конгруэнтности, если правильный ответ отсутствует в пуле кандидатов, его никогда нельзя будет выбрать. Чтобы достичь идеальной точности, нам нужно улучшить как покрытие, так и конгруэнтное предсказание.
Чтобы достичь идеальной точности, нам нужно улучшить как покрытие, так и конгруэнтное предсказание.
Мы видим максимальную точность предсказания при 100-мерных векторных вложениях 75,795%. Увеличение размерности увеличивает производительность, но только до предела. При векторном встраивании 300d максимальная производительность составила 76,304%, а при векторном встраивании 500d — 76,291%.
Мы экспериментировали с неитеративным подходом, при котором мы не ограничивали третий именованный объект прогнозированием ранее идентифицированной наиболее конгруэнтной пары, а вместо этого позволяли ему потенциально сочетаться с четвертым или более высоким именованным объектом. Это снизило максимальную производительность примерно на 2%, предполагая, что прогностический сигнал от пары с наивысшим конгруэнтным значением важно использовать при оценке всего предложения.
Наконец, мы экспериментировали с пулами кандидатов разного размера.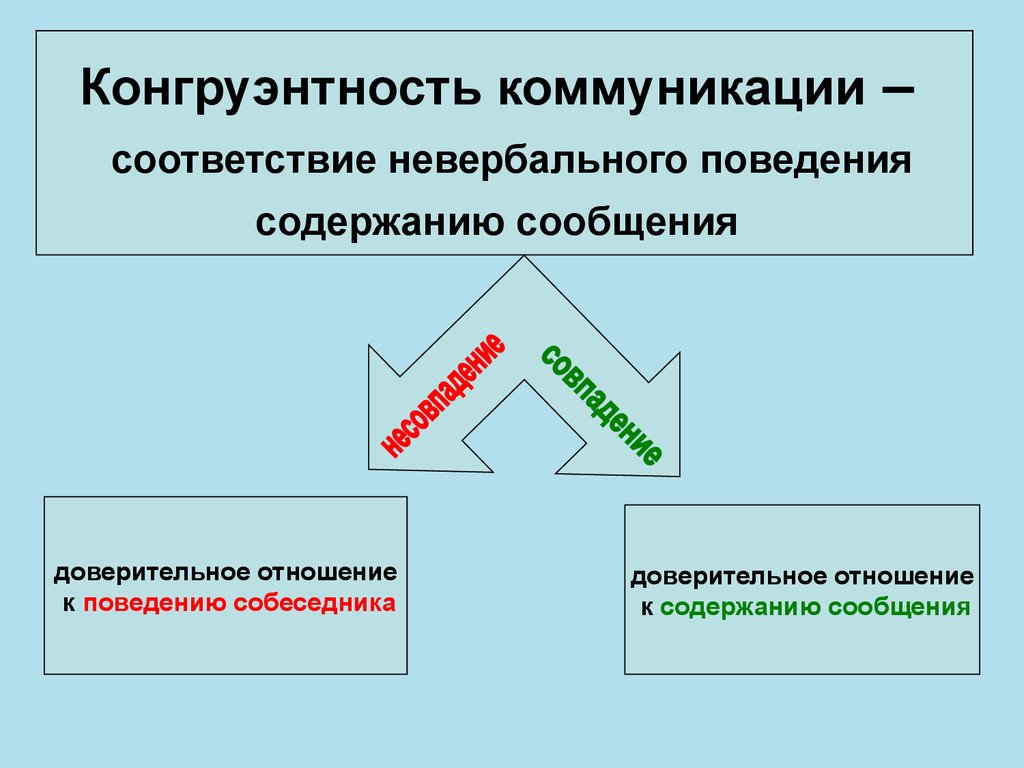 Предоставление от 5 до 10 кандидатов для расчета конгруэнтности оказалось наиболее эффективным. Меньше этого снижало максимальную производительность на 1–2%. Более того (включая сохранение всех кандидатов) снизили максимальную производительность на 3%, но значительно увеличили время вычислений.
Предоставление от 5 до 10 кандидатов для расчета конгруэнтности оказалось наиболее эффективным. Меньше этого снижало максимальную производительность на 1–2%. Более того (включая сохранение всех кандидатов) снизили максимальную производительность на 3%, но значительно увеличили время вычислений.
Наш третий метод заключался в том, чтобы найти наших кандидатов в графе знаний, полученном из Kensho, и вычислить кратчайшее расстояние пути между всеми кандидатами, прежде чем выбрать ближайший в качестве наших прогнозов. Этот метод был самым сложным в вычислительном отношении. Граф знаний Википедии имеет 141 миллион отношений и 50 миллионов узлов, и его невозможно было полностью загрузить в выбранный нами пакет графов NetworkX.
Чтобы обойти это, мы разработали метод, который мы назвали «Расстояние по дендриту». Этот подход создает во время выполнения гораздо меньший граф путем поиска всех кандидатов именованных сущностей в одном предложении, возврата соединений первой степени и использования этого расширенного пула в качестве всего нашего графа. Это гарантирует, по крайней мере, обеспечение кратчайшего пути между ближайшими кандидатами, поскольку, если пара кандидатов не пересекается через их связи первой степени, у них не будет более короткого пути через их связи второй степени. Поскольку наш простой подход заключался только в поиске ближайшего, мы решили, что этого достаточно.
Это гарантирует, по крайней мере, обеспечение кратчайшего пути между ближайшими кандидатами, поскольку, если пара кандидатов не пересекается через их связи первой степени, у них не будет более короткого пути через их связи второй степени. Поскольку наш простой подход заключался только в поиске ближайшего, мы решили, что этого достаточно.
Сложный характер этого подхода означал, что возврат прогноза для одного именованного объекта занимал от 18 до 25 секунд. Для небольшой выборки из 200 именованных сущностей мы увидели прогностическую точность 60,163%. Это ниже, чем при использовании только статистики по якорным ссылкам, но мы считаем, что существует значительная возможность улучшить наш подход для достижения более быстрых вычислений, более информативных показателей расстояния и прямого включения нашей предыдущей достоверности путем математического объединения ее с кратчайшим путем.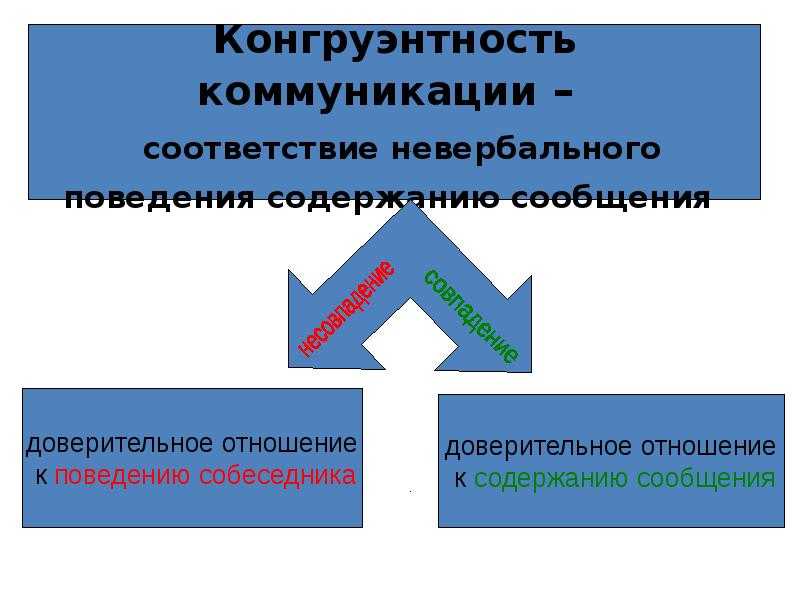
Наконец, мы попытались изолировать информационную мощность графа знаний, вычислив сходство векторов с использованием предварительно обученных вложений из пакета GraphVite, которые были разработаны с использованием только графа знаний Википедии по сравнению с тремя подмоделями Wikipedia2Vec. Использование этих вложений только графа знаний для небольшой выборки из 100 дало показатель точности 74,528%, что является улучшением по сравнению с одной только статистикой ссылок, но не соответствует максимальной производительности, демонстрируемой более информативными вложениями из Wikipedia2Vec.
Резюме результатов исследований по методам Будущие исследования Наша работа показала, что существует потенциал в использовании конгруэнтности именованных объектов, но чтобы выйти за рамки Википедии, необходимо разработать более общий метод обучения информативным встраиваниям, подобным тем, которые предоставляет Wikipedia2Vec. . Следует провести исследование прироста производительности, обеспечиваемого этими вложениями сущностей, обученными на базах знаний разного размера. Поскольку Википедия является крупнейшей общедоступной базой знаний в мире, будут ли вложения сущностей одинаково хорошо работать при устранении неоднозначности, если обучаться таким же образом, но на гораздо меньшей частной базе знаний?
Поскольку Википедия является крупнейшей общедоступной базой знаний в мире, будут ли вложения сущностей одинаково хорошо работать при устранении неоднозначности, если обучаться таким же образом, но на гораздо меньшей частной базе знаний?
Существуют значительные возможности для улучшения вычислительной производительности графовых вычислений с использованием специализированных технологий, таких как Neo4J. Наш подход «Расстояние дендритов» может служить полезной основой для усовершенствования конструкции конвейера, но следует приложить больше усилий для оптимизации.
Наконец, охват, обеспечиваемый статистикой якорных ссылок, может быть улучшен, чтобы поднять потолок выше текущего уровня ~90%. Потенциальные пути включают лучшую нормализацию текста, включение в базу данных большего количества разговорных гиперссылок, чем Википедия, и обеспечение многоязычных якорных ссылок в источнике для необычных неанглийских имен.
В этом исследовании мы показываем, что включение концепции Конгруэнтности именованных объектов или взаимосвязи между именованными объектами в одном и том же контекстном окне может повысить точность прогнозирования в задаче НЛП по устранению неоднозначности именованных объектов.
Используя 300d предварительно обученных вложений сущностей Wikipedia2Vec, наш метод конгруэнтности итеративного сходства встраивания сущности <> сущности дал значимый абсолютный выигрыш в 4,2% для достижения общей точности прогнозирования 76,3% в тестовом наборе данных AIDA CoNLL-YAGO.
Мы предложили структуру, состоящую из двух частей: 1) Генерация пула кандидатов и 2) Конгруэнтное устранение неоднозначности, в рамках которой будущие исследователи могут нацеливаться на конкретные идеи для улучшения. Мы предоставили два разных метода для создания пулов кандидатов и три метода для вычисления конгруэнтности и связанных с ними результатов производительности.
Используя Сущность<>Сходство вектора сущности в качестве меры соответствия, мы продемонстрировали, что включение априорной вероятности с конгруэнтностью может привести к значительному повышению точности прогнозирования по сравнению с хорошо структурированной базой знаний, такой как Википедия.