НЛП: название и история — Психологос
НЛП — нейролингвистическое программирование. Одинаково правильно говорить и эн-эл-пэ, и эн-эл-пи. НЛП не следует путать с нейролингвистикой, традиционно научным изучением языка и мозга.
Нейро – определяет связь с неврологической системой, т.е. определяет путь использования наших органов чувств: зрения, слуха, осязания, вкуса и обоняния.
Лингвистическое – определяет связь между языком, используемым человеком, и его жизненным опытом. Лексические модели человека являются выражением особенности его мышления и в большей или меньшей степени отражают его внутреннюю сущность.
Программирование – составление совокупности действий, предназначенных для достижения определенного результата: изменения переживания и опыта. Каждый из нас имеет свои осознаваемые или нет личностные программы.
НЛП считает, что достигнутые нами результаты и воздействия, которые мы оказываем на себя и других людей, являются следствием нашей личностной программы
 Осознав элементы личностных программ, в какой последовательности эти элементы воспроизводятся в поведении или мышлении, мы можем управлять собственными переживаниями, состоянием и поведением.
Осознав элементы личностных программ, в какой последовательности эти элементы воспроизводятся в поведении или мышлении, мы можем управлять собственными переживаниями, состоянием и поведением.Сами создатели НЛП определяют эту дисциплину как «определённый системный метод думать о вещах» (Р. Бендлер, Дж. Гриндер, 1978).
В методологическом плане НЛП — это попытка синтезировать гуманистическое понимание психики, развитое «психологией Новой Волны» в 60 гг. XX века и знание точных механизмов работы психики человека, полученное различными исследовательскими группами на Западе в 60-90 гг. XX века.
В практическом плане НЛП — набор быстрых и эффективных методик, работающих, в основном, с бессознательным человека, помогающих достичь конкретных практических результатов. Как метод, методики НЛП активно используются в психотерапии, бизнес-консультировании, коучинге, преподавании, проведении тренингов, полит-консультировании, ораторском мастерстве, мотивации, информационном манипулировании.
История НЛП
Сутью и смыслом НЛП с момента его возникновения в семидесятых-восьмидесятых годах XX века было и остается моделирование. Именно моделирование, как подход и технология, породило множество техник НЛП, благодаря которым само направление и приобрело популярность. Все начиналось со студенческих попыток скопировать уникальные результаты высоких профессионалов, мастеров своего дела без долгосрочного обучения, прохождения сложной подготовки и, главное, без обязательного «таланта».
Сначала все сколько-нибудь интересные результаты были достигнуты простым подражанием. Особые способности в этом проявлял Ричард Бендлер.
С появлением в этом кругу Джона Гриндера дело было поставлено на более формализованную основу: он ввел понятие «кода», особого языка для описания элементов человеческого опыта.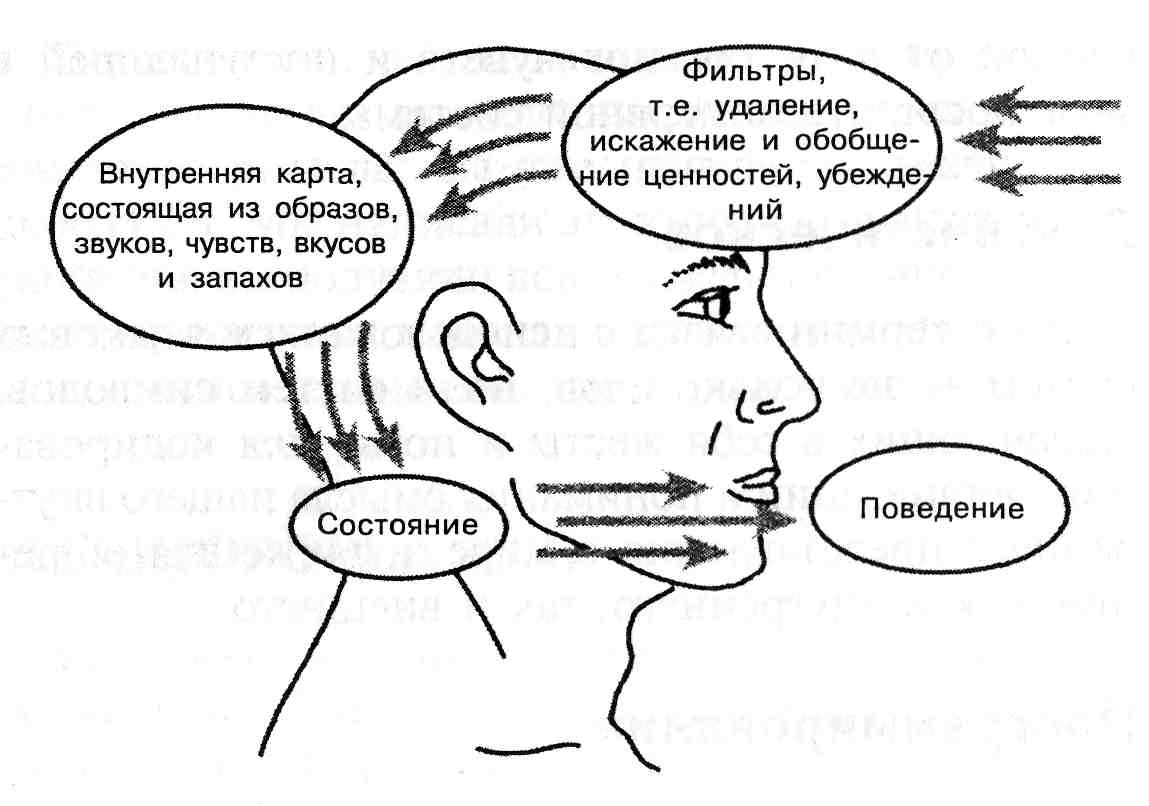
В основе классического кода лежит мысль о том, что все действия человека можно описать на уровне «сенсорной очевидности» — в виде эмпирических фактов (цвет, скорость, размер, траектория движения, критерии выбора и проч). Именно это описывается триадой «вижу-слышу-чувствую» (иначе называется «ВАК-очевидностью» на основе так называемых трех модальностей — визуальной, аудиальной и кинестетической).
Дальнейшие попытки моделирования привели к мысли о том, что изучить и воспроизвести можно и зачастую необходимо не только телесные движения, но и мыслительные действия: как человек вспоминает и запоминает (не вообще «человек», а этот конкретный) данные, делает мысленный выбор, принимает решения, выбирает доказательства и так далее. К примеру, моделирование вкуса в подборе одежды или навыка написания текстов не получается свести к чисто двигательным навыкам. В арсенале НЛП появились наблюдения за ходом мысли человека по глазодвигательным паттернам — рисунку движения глаз в момент размышления. Затем, преимущественно благодаря работе Ричарда Бэндлера, внутренний мыслительный опыт человека был описан в категориях субмодальностей — когда «вижу», «слышу» и «чувствую» раскладываются на более мелкие составляющие. Дальнейшая работа над оттачиванием инструментов моделирования постепенно привела к возможности «раскладывать по полочкам» комплексные состояния человека (вроде вдохновения или влюбленности, озарения или интуиции), формализовать сложные системы взаимоотношений и работу бизнес-организаций.
К примеру, моделирование вкуса в подборе одежды или навыка написания текстов не получается свести к чисто двигательным навыкам. В арсенале НЛП появились наблюдения за ходом мысли человека по глазодвигательным паттернам — рисунку движения глаз в момент размышления. Затем, преимущественно благодаря работе Ричарда Бэндлера, внутренний мыслительный опыт человека был описан в категориях субмодальностей — когда «вижу», «слышу» и «чувствую» раскладываются на более мелкие составляющие. Дальнейшая работа над оттачиванием инструментов моделирования постепенно привела к возможности «раскладывать по полочкам» комплексные состояния человека (вроде вдохновения или влюбленности, озарения или интуиции), формализовать сложные системы взаимоотношений и работу бизнес-организаций.
«Новый код НЛП», «Нейрологические уровни», «Конфайнмент®-моделирование», «Мета-состояния», «Линия времени» и многие другие достижения в области НЛП так или иначе связаны с главной идеей всего направления:
ЕСЛИ КТО-ТО ЧТО-ТО МОЖЕТ ДЕЛАТЬ И ДЕЛАЕТ ЛУЧШЕ ТЕБЯ, ОН ДЕЛАЕТ ЭТО «КАК-ТО». ЭТО «КАК-ТО» МОЖЕТ БЫТЬ РАЗЛОЖЕНО НА СОСТАВЛЯЮЩИЕ. СРЕДИ СОСТАВЛЯЮЩИХ МОЖНО ВЫДЕЛИТЬ «ПАТТЕРНЫ» — ОБЯЗАТЕЛЬНЫЕ ЭЛЕМЕНТЫ, КОТОРЫЕ ОБЕСПЕЧИВАЮТ УСПЕХ. ЗАТЕМ В ДЕЙСТВИЯХ ДРУГИХ ЛЮДЕЙ МОЖНО ВОСПРОИЗВОДИТЬ ЛИШЬ ЭТИ ПАТТЕРНЫ, ЧТО И ОБЕСПЕЧИВАЕТ ПРИЕМЛЕМЫЙ РЕЗУЛЬТАТ.
ЭТО «КАК-ТО» МОЖЕТ БЫТЬ РАЗЛОЖЕНО НА СОСТАВЛЯЮЩИЕ. СРЕДИ СОСТАВЛЯЮЩИХ МОЖНО ВЫДЕЛИТЬ «ПАТТЕРНЫ» — ОБЯЗАТЕЛЬНЫЕ ЭЛЕМЕНТЫ, КОТОРЫЕ ОБЕСПЕЧИВАЮТ УСПЕХ. ЗАТЕМ В ДЕЙСТВИЯХ ДРУГИХ ЛЮДЕЙ МОЖНО ВОСПРОИЗВОДИТЬ ЛИШЬ ЭТИ ПАТТЕРНЫ, ЧТО И ОБЕСПЕЧИВАЕТ ПРИЕМЛЕМЫЙ РЕЗУЛЬТАТ.
Именно это и делает возможным быстрое обучение — быструю передачу навыков и опыта от одних людей другим. Что и составляет суть и смысл НЛП.
Где можно пройти обучение НЛП в Москве? В тренинг-центре Синтон:
- Курс НЛП-интенсив
- Курс НЛП — регулярный
Краткая история NLP — Natural Language Processing / Хабр
История использования систем обработки естественного языка насчитывает всего 50 лет, но изо дня в день мы используем различные модели NLP. В различных поисковых запросах, переводчиках и чат‑ботах. NLP возникло как слияние искусственного интеллекта и лингвистики. Лингвистика — это наука, изучающая языки, их семантику — смысловые единицы слов, фонетику — изучение звукового состава слов, синтаксис — номинативные и коммуникативные единицы языка.
Ноам Хомский был ученым‑лингвистом, который произвел революцию в области лингвистики и изменил наше понимание синтаксиса. Он создал систему грамматического описания, известную как генеративная или генеративная грамматика (соответствующее течение лингвистической мысли часто называют генеративизмом — NLG). Ее основы были сформулированы Хомским в середине 1950-х годов. Работа Хомски стала началом рационалистического направления в компьютерной лингвистике. Отправной точкой рационализма являются компьютерные модели, не зависящие от языка. Модели лучше всего принимаются, когда они максимально просты. Здесь можно провести параллель с идеей Соссюра об отделении языка от реального мира.
Аврам Ноам Хомский — американский публичный интеллектуал: лингвист, философ, когнитолог, историк, социальный критик и политический активист. Иногда его называют «отцом современной лингвистики», Хомский также является крупной фигурой в аналитической философии и одним из основателей области когнитивной науки.
Этот подход с самого начала не дал хороших результатов, но по мере продолжения работы в этом направлении результаты стали несколько лучше, чем у систем, исповедующих подход «снизу вверх». Теория универсальной грамматики Хомского предоставила схему, не зависящую от индивидуальных особенностей конкретного языка. Синтаксис лучше всего соответствовал моделям независимых языков, в которых учитывались только языки.
Первые исследователи машинного перевода поняли, что машина не сможет перевести входной текст без дополнительной помощи. Учитывая скудость лингвистических теорий, особенно до 1957 года, некоторые предлагали предварительно редактировать тексты таким образом, чтобы отмечать в них трудности, например, для устранения омонимии. А поскольку системы машинного перевода не могли выдать правильный результат, текст на языке перевода приходилось редактировать, чтобы сделать его понятным.
Системы обработки естественного языка расширяют наши знания о человеческом языке. Некоторые из исследуемых задач NLP включают автоматическое резюмирование (автоматическое резюмирование создает понятное резюме набора текстов и предоставляет краткую или подробную информацию о тексте известного типа), совместное реферирование (совместное реферирование относится к предложению или большему набору текста, в котором определены все слова, относящиеся к одному и тому же объекту), анализ дискурса (анализ дискурса относится к задаче определения структуры дискурса связанного текста, т. е. Машинный перевод).
е. Машинный перевод).
Как мы уже говорили выше, NLP можно разделить на две части, на NLU — Natural Language Understanding. И NLG — генерация естественного языка. В контексте нашей проблемы нас интересует первая — Natural Language Understanding. Наша задача — научить машину понимать текст и делать выводы из того материала, который мы ей предложили. NLU позволяет машинам понимать и анализировать естественный язык, извлекать концепции, сущности, эмоции, ключевые слова и т. д. Он используется в приложениях по обслуживанию клиентов для понимания проблем, о которых клиенты сообщают устно или письменно. Лингвистика — это наука, изучающая значение языка, языковой контекст и различные формы языка.
Понимание естественного языка — это задача лингвистики, которая включает такие компоненты, как фонология, морфология, синтаксис и семантика. Это все компоненты любого предложения на любом языке, изучение которых является важной задачей для общего понимания того, как строится обработка естественного языка.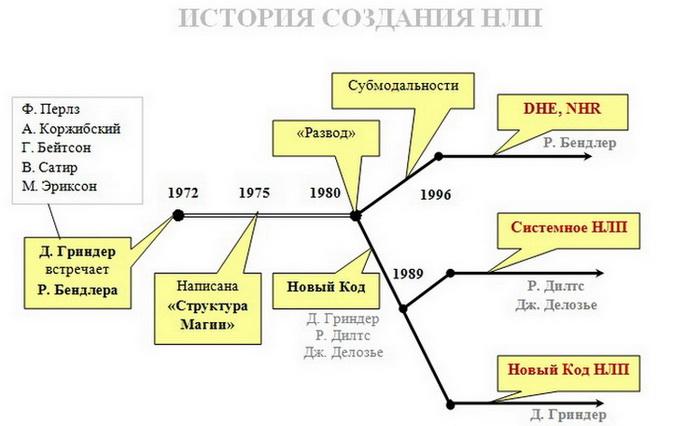
Первым применением обработки естественного языка был машинный перевод. Целью было создание машины, способной переводить человеческую речь или текст. Первые шаги в этой области были сделаны Джорджтаунским университетом и компанией IBM Companying 1954. Программа смогла перевести 60 русских предложений на английский язык. Как позже сообщила компания IBM: «Эта программа включала логические алгоритмы, которые принимали грамматические и семантические „решения“, имитирующие работу двуязычного человека». Этот прорыв дал представление о том, как будут развиваться будущие технологии и возможности обработки данных.
7 января 1954 года IBM продемонстрировали экспериментальную программу, которая позволяла компьютеру IBM 701 переводить с русского на английский. В 1959 году устройство Mark 1 Translating Device, разработанное для ВВС США, произвело первый автоматизированный перевод с русского на английский язык. Mark 1 был продемонстрирован публике в павильоне IBM на Всемирной выставке в Нью-Йорке в 1964 году.
В конце 1960-х годов Терри Виноград из Массачусетского технологического института разрабатывает SHRDLU — программу обработки естественного языка. Она была способна отвечать на вопросы и учитывать новые факты о своем мире. SHRDLU могла сочетать сложный синтаксический анализ с достаточно общей дедуктивной системой, работая в «мире» с видимыми аналогами восприятия и действия. Машина могла отвечать на простые вопросы, и казалось, что если потратить достаточно усилий на передачу смысла и ограничить себя некоторой областью, SHRDLU сможет достичь естественной коммуникации. Но и этот ранний подход имел свои подводные камни, которые не позволяли развивать его дальше, машина по‑прежнему плохо понимала текст, и ей довольно редко удавалось понять, какой текст мог составить SHRDLU.
Пользователь дает запрос программе, какое действие ей нужно предпринять.Затем, в 1969 году, Роджер Шанк разработал концептуальную систему зависимостей, которую он описал как: «стратифицированная лингвистическая система, позволяющая предоставить вычислительную теорию моделируемой производительности». Это была концепция создания лексем, которые позволяли извлекать из текста больше смысла. Эти лексемы могли содержать различные объекты реального мира. Комбинация токенов в различных аспектах призвана учесть всю совокупность языковой деятельности человека на концептуальном уровне. Если пользователь говорит, что с конструкцией все в порядке, она добавляется в память, в противном случае конструкция ищется в списке метафор или прерывается. Таким образом, система использует запись того, что она слышала раньше, для анализа того, что она слышит сейчас.
Это была концепция создания лексем, которые позволяли извлекать из текста больше смысла. Эти лексемы могли содержать различные объекты реального мира. Комбинация токенов в различных аспектах призвана учесть всю совокупность языковой деятельности человека на концептуальном уровне. Если пользователь говорит, что с конструкцией все в порядке, она добавляется в память, в противном случае конструкция ищется в списке метафор или прерывается. Таким образом, система использует запись того, что она слышала раньше, для анализа того, что она слышит сейчас.
В своей работе Роджер ухватился за идею о том, что прежде чем компьютеры начнут понимать естественный язык, они должны научиться принимать решения о том, что именно им говорят. Синтаксический анализатор Роджера был ориентирован на семантику языка; он смог научить компьютер различать важные концептуальные отношения.
Роджер Карл Шанк — американский теоретик искусственного интеллекта, когнитивный психолог, ученый в области обучения, реформатор образования и предпринимательЗатем, в 1970-х годах, Уильям Вудс разработал свою систему распознавания и обработки текста, он представил дополненную сеть перехода (ATN). На основе которой в дальнейшем была разработана программа LAS, позволяющая создавать классы слов языка и понимать правила формирования предложений. ATN позволяла не только формировать новые предложения, но и понимать естественный язык. Программа создавала связи между структурой предложения и структурой поверхности, формировала классы слов.
На основе которой в дальнейшем была разработана программа LAS, позволяющая создавать классы слов языка и понимать правила формирования предложений. ATN позволяла не только формировать новые предложения, но и понимать естественный язык. Программа создавала связи между структурой предложения и структурой поверхности, формировала классы слов.
Программа обещала быть такой же адаптивной, как и человек. Изучая новый материал, человек знакомился с новой лексикой, новыми синтаксическими конструкциями, чтобы поделиться своими мыслями в той среде, которую он изучал. LAS была написана на мичиганском языке LISP, она позволяла получать на вход несколько строк, которые она описывала как сцены, закодированные в виде ассоциативных сетей. Таким же образом программа могла подчиняться командам понимать, писать, учиться. Ядром всей системы была грамматика дополненной переходной сети ATN.
Пример дерева зависимостей: «Что такое синтаксический анализатор?».До появления алгоритмов машинного обучения в 1980-х годах вся обработка естественного языка сводилась к рукописным и неавтоматизированным правилам. Тем не менее, еще до этого времени появились первые идеи о создании машин, которые могли бы работать подобно человеческому мозгу, через нейронные связи. Это стало прообразом искусственного интеллекта, построенного на нейронных сетях в будущем.
Тем не менее, еще до этого времени появились первые идеи о создании машин, которые могли бы работать подобно человеческому мозгу, через нейронные связи. Это стало прообразом искусственного интеллекта, построенного на нейронных сетях в будущем.
С начала 21 века и по сей день развитие машинного обучения начало набирать обороты, пережив две зимы ИИ, машинное обучение снова вошло в моду, в том числе благодаря Big Data и глубокому обучению. Новые методы и подходы к обработке слов создаются и сегодня, что делает изучение NLP актуальным и сегодня.
НЛП — обзор
| Обзор | введение | история | |
История Область обработки естественного языка началась в 1940-х годах, после того, как Всемирная
Вторая война. В это время люди осознали важность перевода
с одного языка на другой и надеялся создать машину, которая
может сделать этот вид перевода автоматически. Около
В то же время в истории, с 1957 по 1970 годы, исследователи разделились на
два подразделения НЛП: символическое и стохастическое. После
В 1970 году исследователи разделились еще дальше, охватив новые области НЛП.
по мере того, как становилось доступно больше технологий и знаний. Одна новая область
были парадигмы, основанные на логике, языки, ориентированные на правила кодирования
и язык в математической логике. Эта область исследований НЛП позже
участвовал в разработке языка программирования Пролог.
Понимание естественного языка было еще одной областью НЛП, которая была
особенно под влиянием SHRDLU, профессора Терри Винограда
докторская диссертация.
компьютер явно способен разрешать отношения между объектами и понять некоторые неясности. Четвертая область НЛП, появившаяся возникшее после 1970 года — это моделирование дискурса. В этой области изучается обмены между людьми и компьютерами, разработка таких идей как необходимость изменить «ты» в вопросе говорящего на «мне» в ответе компьютера. От
С 1983 по 1993 год исследователи стали более сплоченными в сосредоточении внимания на эмпиризме.
и вероятностные модели. Исследователям удалось проверить некоторые
аргументы Хомского и других 1950-х и 60-х годов, открывая
что многие аргументы, которые были убедительны в тексте, не были подтверждены эмпирически
точный. Таким образом, к 1993 г. вероятностно-статистические методы
обработки естественного языка были наиболее распространенными типами
моделей. | ||
 Тем не менее, задача
было явно не так просто, как люди сначала себе представляли. К 1958, некоторые
исследователи выявили важные проблемы в развитии
НЛП. Одним из таких исследователей был Ноам Хомский, обнаруживший
беспокоит то, что модели языка распознают предложения, которые
бессмыслица, но грамматически правильная, столь же неуместная, как и предложения
это было ерундой и не грамматически правильно. Хомский нашел
Проблематично, что предложение «Бесцветные зеленые идеи спят
яростно» был классифицирован как маловероятный в той же степени
что «неистово спят идеи зеленые бесцветные»; любой спикер
английского языка может распознать первое как грамматически правильное и
последнее как неверное, и Хомский чувствовал, что того же следует ожидать
моделей машин.
Тем не менее, задача
было явно не так просто, как люди сначала себе представляли. К 1958, некоторые
исследователи выявили важные проблемы в развитии
НЛП. Одним из таких исследователей был Ноам Хомский, обнаруживший
беспокоит то, что модели языка распознают предложения, которые
бессмыслица, но грамматически правильная, столь же неуместная, как и предложения
это было ерундой и не грамматически правильно. Хомский нашел
Проблематично, что предложение «Бесцветные зеленые идеи спят
яростно» был классифицирован как маловероятный в той же степени
что «неистово спят идеи зеленые бесцветные»; любой спикер
английского языка может распознать первое как грамматически правильное и
последнее как неверное, и Хомский чувствовал, что того же следует ожидать
моделей машин.

 В последнее десятилетие НЛП также стало более целенаправленным.
на извлечение и генерацию информации из-за огромных объемов
информации, разбросанной по Интернету. Кроме того, личная
компьютеры теперь повсюду, и, следовательно, приложения потребительского уровня
НЛП гораздо более распространены и являются стимулом для дальнейших исследований.
В последнее десятилетие НЛП также стало более целенаправленным.
на извлечение и генерацию информации из-за огромных объемов
информации, разбросанной по Интернету. Кроме того, личная
компьютеры теперь повсюду, и, следовательно, приложения потребительского уровня
НЛП гораздо более распространены и являются стимулом для дальнейших исследований. Краткая история обработки естественного языка (НЛП)
В начале 1900-х годов швейцарский профессор лингвистики по имени Фердинанд де Соссюр умер, почти лишив мир Концепция «Язык как наука». С 1906 по 1911 год профессор Соссюр предложил три курса в Женевском университете, где разработал подход, описывающий языки как «системы». В языке звук представляет понятие – понятие, значение которого меняется при изменении контекста.
Он утверждал, что значение создается внутри языка, в
отношения и различия между его частями. Соссюр предположил, что «смысл»
созданные в рамках языковых отношений и контрастов. Общая языковая система
делает возможным общение. Соссюр рассматривал общество как систему «общих»
социальные нормы, создающие условия для разумного, «расширенного» мышления,
результатом решений и действий отдельных лиц. (Тот же вид может быть
применительно к современным компьютерным языкам).
Общая языковая система
делает возможным общение. Соссюр рассматривал общество как систему «общих»
социальные нормы, создающие условия для разумного, «расширенного» мышления,
результатом решений и действий отдельных лиц. (Тот же вид может быть
применительно к современным компьютерным языкам).
Соссюр умер в 1913 году, но двое его коллег, Альберт Сешехай и Шарль Балли, признали важность его концепций. (Представьте себе этих двоих, через несколько дней после смерти Соссюра, в кабинете Балли, пьющих кофе и размышляющих, как не потерять его открытия навсегда). Эти двое предприняли необычные шаги, собрав «его заметки для рукописи» и заметки его учеников с курсов. Из них они написали Cours de Linguistique Générale , опубликованную в 1916 году. Книга заложила основу того, что стало называться структуралистским подходом, начиная с лингвистики, а затем расширив его на другие области, включая компьютеры.
В 1950 году Алан Тьюринг написал статью, описывающую тест для «думающей» машины. Он заявил, что если машина может участвовать в разговоре с помощью телетайпа и настолько полностью имитировать человека, что нет заметных отличий, то машину можно считать способной мыслить. Вскоре после этого, в 1952 году, модель Ходжкина-Хаксли показала, как мозг использует нейроны для формирования электрической сети. Эти события помогли вдохновить на идею искусственного интеллекта (ИИ), обработки естественного языка (НЛП) и эволюции компьютеров.
Он заявил, что если машина может участвовать в разговоре с помощью телетайпа и настолько полностью имитировать человека, что нет заметных отличий, то машину можно считать способной мыслить. Вскоре после этого, в 1952 году, модель Ходжкина-Хаксли показала, как мозг использует нейроны для формирования электрической сети. Эти события помогли вдохновить на идею искусственного интеллекта (ИИ), обработки естественного языка (НЛП) и эволюции компьютеров.
Обработка естественного языка
Обработка естественного языка (NLP) — это аспект искусственного интеллекта, который помогает компьютерам понимать, интерпретировать и использовать человеческие языки. НЛП позволяет компьютерам общаться с людьми, используя человеческий язык. Обработка естественного языка также предоставляет компьютерам возможность читать текст, слышать речь и интерпретировать ее. НЛП основано на нескольких дисциплинах, включая компьютерную лингвистику и информатику, поскольку оно пытается сократить разрыв между человеческим и компьютерным общением.
Вообще говоря, НЛП разбивает язык на более короткие, более простые части, называемые токенами (слова, точки и т. д.), и пытается понять взаимосвязь этих токенов. В этом процессе часто используются функции НЛП более высокого уровня, такие как:
- Категоризация контента: A лингвистическое резюме документа, которое включает предупреждения о содержании, дублирование обнаружение, поиск и индексирование.
- Открытие темы и моделирование: Capture темы и значения текстовых коллекций, а также применяет расширенные аналитика к тексту.
- Контекстное извлечение: Автоматически извлекает структурированные данные из текстовых источников.
- Анализ настроений: Идентифицирует общее настроение или субъективные мнения, хранящиеся в больших объемах текста. Полезно для анализа мнений.
- Преобразование текста в речь и речи в текст: Преобразует голосовые команды в текст и наоборот.

- Обобщение документов: Автоматически создает синопсис, сокращая большие объемы текста.
- Машинный перевод: Автоматически переводит текст или речь с одного языка на другой.

НЛП начинается и заканчивается
Ноам Хомский опубликовал свою книгу Синтаксические структуры в 1957 году. быть изменен. С этой целью Хомский создал стиль грамматики под названием «Грамматика фазовой структуры», который методично переводил предложения естественного языка в формат, пригодный для использования компьютерами. (Общая цель состояла в том, чтобы создать компьютер, способный имитировать человеческий мозг с точки зрения мышления и общения, или ИИ.)
В 1958 году Джон Маккарти выпустил язык программирования LISP (протокол разделения локаторов/идентификаторов), используемый до сих пор. В 1964 году был разработан ELIZA, «машинописный» процесс комментариев и ответов, предназначенный для имитации психиатра, использующего методы рефлексии. (Он делал это, переставляя предложения и следуя относительно простым грамматическим правилам, но со стороны компьютера не было понимания.) Также в 1964 году Национальный исследовательский совет США (NRC) создал Консультативный комитет по автоматической обработке языка, или сокращенно ALPAC. . Этому комитету было поручено оценить ход исследований в области обработки естественного языка.
(Он делал это, переставляя предложения и следуя относительно простым грамматическим правилам, но со стороны компьютера не было понимания.) Также в 1964 году Национальный исследовательский совет США (NRC) создал Консультативный комитет по автоматической обработке языка, или сокращенно ALPAC. . Этому комитету было поручено оценить ход исследований в области обработки естественного языка.
В 1966 году NRC и ALPAC инициировали первую остановку ИИ и НЛП, путем прекращения финансирования исследований в области обработки естественного языка и машинного перевод. После двенадцати лет исследований и 20 миллионов долларов машина переводы все еще были дороже, чем ручные человеческие переводы, и по-прежнему не существовало компьютеров, которые хотя бы приблизились к тому, чтобы вести основной разговор. В 1966 году искусственный интеллект и обработка естественного языка (НЛП) многие (хотя и не все) считали исследования тупиковыми.
Возвращение НЛП
Потребовалось почти четырнадцать лет (до 1980 г. ), чтобы исследования процессов естественного языка и искусственного интеллекта оправились от обманутых ожиданий, порожденных экстремистскими энтузиастами. В некотором смысле остановка ИИ положила начало новой фазе свежих идей, когда отказались от более ранних концепций машинного перевода, а новые идеи способствовали новым исследованиям, включая экспертные системы. Смешение лингвистики и статистики, которое было популярно в ранних исследованиях НЛП, было заменено темой чистой статистики. 1980-е годы инициировали фундаментальную переориентацию, когда простые приближения заменили глубокий анализ, а процесс оценки стал более строгим.
), чтобы исследования процессов естественного языка и искусственного интеллекта оправились от обманутых ожиданий, порожденных экстремистскими энтузиастами. В некотором смысле остановка ИИ положила начало новой фазе свежих идей, когда отказались от более ранних концепций машинного перевода, а новые идеи способствовали новым исследованиям, включая экспертные системы. Смешение лингвистики и статистики, которое было популярно в ранних исследованиях НЛП, было заменено темой чистой статистики. 1980-е годы инициировали фундаментальную переориентацию, когда простые приближения заменили глубокий анализ, а процесс оценки стал более строгим.
До 1980-х годов в большинстве систем НЛП использовались сложные,
«рукописные» правила. Но в конце 1980-х произошла революция в НЛП.
Это было результатом как неуклонного роста вычислительной мощности, так и
переход на алгоритмы машинного обучения. В то время как некоторые из ранних машинного обучения
алгоритмы (хорошим примером являются деревья решений) создали системы, подобные
Рукописные правила старой школы, исследования все больше сосредотачиваются на статистических
модели. Эти статистические модели способны создавать мягкие вероятностные
решения. На протяжении 1980-х годов компания IBM отвечала за разработку
несколько успешных, сложных статистических моделей.
Эти статистические модели способны создавать мягкие вероятностные
решения. На протяжении 1980-х годов компания IBM отвечала за разработку
несколько успешных, сложных статистических моделей.
В 1990-х популярность статистических моделей для анализа процессов естественного языка резко возросла. Чисто статистические методы НЛП стали чрезвычайно ценными, учитывая огромный поток онлайн-текста. N-граммы стали полезными, распознавая и отслеживая группы лингвистических данных в числовом виде. В 1997 году были представлены модели рекуррентных нейронных сетей (RNN) LSTM, которые в 2007 году нашли свою нишу для обработки голоса и текста. В настоящее время модели нейронных сетей считаются передовым направлением исследований и разработок в понимании НЛП генерации текста и речи.
После 2000 года
В 2001 году Йошио Бенжио и его команда предложили первую нейронную «языковую» модель, используя нейронную сеть с прямой связью. Нейронная сеть с прямой связью описывает искусственную нейронную сеть, которая не использует связи для формирования цикла. В этом типе сети данные перемещаются только в одном направлении, от входных узлов через любые скрытые узлы, а затем к выходным узлам. Нейронная сеть с прямой связью не имеет циклов или петель и сильно отличается от рекуррентных нейронных сетей.
В этом типе сети данные перемещаются только в одном направлении, от входных узлов через любые скрытые узлы, а затем к выходным узлам. Нейронная сеть с прямой связью не имеет циклов или петель и сильно отличается от рекуррентных нейронных сетей.
В 2011 году Siri от Apple стала известна как один из первых в мире успешных помощников НЛП/ИИ, которым пользуются обычные потребители. В Siri модуль автоматического распознавания речи переводит слова владельца в цифровые концепции. Затем система голосового управления сопоставляет эти понятия с предопределенными командами, инициируя определенные действия. Например, если Siri спросит: «Вы хотите услышать свой баланс?» он поймет ответ «Да» или «Нет» и будет действовать соответственно.
Благодаря методам машинного обучения манера речи владельца не обязательно должна точно совпадать с предопределенными выражениями. Звуки просто должны быть достаточно близкими, чтобы система НЛП могла правильно перевести смысл. Используя цикл обратной связи, механизмы НЛП могут значительно повысить точность своих переводов и увеличить словарный запас системы.