Prelink — Gentoo Wiki
Other languages:
- English
- français
- italiano
- русский
- 日本語
- 한국어
В этом руководстве рассказывается, как использовать поддержку prelink в Portage 2.0.46 и более поздних версиях.
Contents
- 1 Введение
- 1.1 Что такое Prelink и как он может помочь?
- 1.2 Обобщение
- 2 Настройка Prelink
- 2.1 Установка программ
- 2.2 Подготовка системы
- 2.3 Конфигурация
- 3 Процесс предварительного связывания
- 3.1 Использование Prelink
- 3.2 Задание Cron для Prelink
- 3.3 Ускорение KDE после предварительного связывания
- 3.4 Удаление prelink
- 4 Известные проблемы и их решения
- 4.1 «Cannot prelink against non-PIC shared library» («Невозможно осуществить предварительное связывание с не-PIC-разделяемой библиотекой»)
- 4.2 Когда я применяю предварительное связывание к моей системе, некоторые статические двоичные файлы больше не работают
- 4.
 3 Prelink прерывается с «prelink: dso.c: 306: fdopen_dso: Assertion ‘j == k’ failed.»
3 Prelink прерывается с «prelink: dso.c: 306: fdopen_dso: Assertion ‘j == k’ failed.» - 4.4 Я использую grsecurity, и кажется, что предварительное связывание не работает.
- 4.5 Prelink падает с ошибкой «prelink: Can’t walk directory tree XXXX: Too many levels of symbolic links» («prelink: не удается обойти дерево каталогов XXXX: слишком много уровней символических ссылок»)
- 5 Заключение
 3 Prelink прерывается с «prelink: dso.c: 306: fdopen_dso: Assertion ‘j == k’ failed.»
3 Prelink прерывается с «prelink: dso.c: 306: fdopen_dso: Assertion ‘j == k’ failed.»Введение
Что такое Prelink и как он может помочь?
Большинство распространенных приложений используют разделяемые библиотеки. Эти разделяемые библиотеки должны быть загружены в память во время выполнения, при этом различные символьные ссылки должны быть вычислены. Для большинства небольших программ эта динамическая компоновка очень быстрая. Но для программ, написанных на C++ и имеющих множество зависимостей между библиотеками, динамическое связывание может занимать достаточно много времени.
В большинстве систем библиотеки не изменяются очень часто, и когда программа запускается, операции, предпринятые для связывания программы, каждый раз одинаковы.
Предварительное связывание может сократить время запуска приложений. Например, типичное время загрузки программы KDE можно сократить на целых 50%. Единственное, что необходимо сделать — повторно выполненить prelink каждый раз, когда библиотека обновляется для предварительно связанного исполняемого файла.
Предупреждение
Prelink не будет работать с Hardened Gentoo. Это связано с тем, что оба проекта пытаются изменить отображение адресного пространства разделяемых библиотек. Но prelink с опцией -R рандомизирует базовые адреса библиотеки, обеспечивая некоторую степень усиленной защиты.
Обобщение
- Предварительное связывание осуществляется с помощью программы, которая, как ни странно, называется
prelink. Она изменяет бинарный файл, чтобы ускорить его запуск. - Если зависящие от приложения библиотеки меняются после того, как вы подвергли его предварительному связыванию, вам нужно повторно связать приложение, иначе вы потеряете выгоду в скорости. Это означает, что каждый раз, когда вы обновляете через portage пакет, который обновляет библиотеки, они должны быть повторно подвергнуты процессу предварительного связывания.
- Изменение бинарного файла полностью обратимо. У
prelinkесть функция возврата к предыдущему состоянию. - Текущие версии Portage могут обрабатывать с помощью
prelinkизменения MD5sums и mtimes бинарных файлов. - Вам не нужно устанавливать
FEATURES="prelink"в вашем файле make.conf; Portage автоматически будет поддерживать prelink, если он находит бинарный файл prelink.
 Это означает, что каждый раз, когда вы обновляете через portage пакет, который обновляет библиотеки, они должны быть повторно подвергнуты процессу предварительного связывания.
Это означает, что каждый раз, когда вы обновляете через portage пакет, который обновляет библиотеки, они должны быть повторно подвергнуты процессу предварительного связывания.Настройка Prelink
Установка программ
Сначала вам нужно установить утилиту prelink. Процесс emerge автоматически проверяет, может ли ваша система безопасно использовать предварительное связывание.
root #emerge --ask prelink
Ряд людей получают ошибки в при установке prelink из-за неудавшихся тестов. Тесты были введены из соображений безопасности, поведение prelink не предсказуемо, если вы отключите их. Ошибки emerge обычно зависят только от основных пакетов; Binutils, gcc и glibc. Попробуйте повторно пересобрать эти пакеты в этом случае.
Тесты были введены из соображений безопасности, поведение prelink не предсказуемо, если вы отключите их. Ошибки emerge обычно зависят только от основных пакетов; Binutils, gcc и glibc. Попробуйте повторно пересобрать эти пакеты в этом случае.
Заметка
Совет: если вы получаете ошибку, попробуйте собрать и протестировать
prelink самостоятельно (./configure; make; make check). При сбое, вы можете просмотреть файлы *.log в каталоге testsuite. Они могут предоставить вам полезные подсказки.Если у вас есть набор шагов, которые приводят к такой же ошибке emerge на другой системе, пожалуйста проверьте Bugzilla и создайте отчет об ошибке, если о ней еще не сообщалось.
Подготовка системы
Также убедитесь, что вы «не» установили -fPIC в «CFLAGS/CXXFLAGS». Если вы это сделали, вам нужно будет полностью пересобрать всю систему без него.
Конфигурация
Запуск env-update создаст файл /etc/prelink. conf, который сообщает prelink, какие файлы должны быть предварительно связаны.
conf, который сообщает prelink, какие файлы должны быть предварительно связаны.
root #env-update
К сожалению, вы не можете предварительно связать файлы, которые были скомпилированы старыми версиями binutils. Большинство таких приложений поставляются только в виде предварительно скомпилированных бинарных пакетов, которые установлены в /opt. Создание следующего файла укажет prelink не пытаться связать их.
Файл /etc/env.d/60prelink
PRELINK_PATH_MASK="/opt"
Заметка
Вы можете добавить больше или меньше каталогов в виде разделенного двоеточиями списка.
Процесс предварительного связывания
Использование Prelink
Я использую следующую команду для связывания всех двоичных файлов в каталогах, заданных /etc/prelink.conf.
root #prelink -amR
Предупреждение
Было замечено, что если вы располагаете маленьким количеством свободного места на диске и вы подвергаете предварительному связыванию всю свою систему, существует вероятность того, что ваши двоичные файлы могут быть усечены.
file или readelf, чтобы проверить состояние двоичного файла. Кроме того, заранее проверьте количество свободного места на жестком диске с помощью df -h.| Разъяснение параметров: | |
|---|---|
| -a | «All»: Предварительное связывание для всех бинарных файлов |
| -m | Сохранить пространство виртуальной памяти. Это необходимо, если у вас много библиотек, которые должны быть предварительно связаны. |
| -R | Random — Рандомизировать порядок адресов, это повышает безопасность при ошибках переполнения буфера. |
Заметка
Дополнительные опции и подробности смотрите в man prelink.
Задание Cron для Prelink
Установитеsys-devel/prelink-20060213, а затем установите задание cron в /etc/cron.daily/prelink. Чтобы включить его, отредактируйте файл конфигурации /etc/conf.d/prelink. Он будет запускать prelink ежедневно в фоновом режиме, спасая вас от необходимости запуска команды вручную.
Чтобы включить его, отредактируйте файл конфигурации /etc/conf.d/prelink. Он будет запускать prelink ежедневно в фоновом режиме, спасая вас от необходимости запуска команды вручную.Ускорение KDE после предварительного связывания
Время загрузки KDE может быть значительно уменьшено после предварительного связывания. Если вы сообщите KDE, что он был предварительно связан, это отключит загрузку kdeinit (поскольку он больше не требуется), что еще больше ускорит KDE.
Установите KDE_IS_PRELINKED=1 в /etc/env.d/*kdepaths*, чтобы сообщить KDE о предварительном связывании.
Удаление prelink
Если вы передумаете использовать предварительное связывание, прежде чем удалять prelink, сначала нужно удалить prelink cronjob из /etc/cron.daily и /etc/conf.d/prelink. Затем вам придется удалить предварительное связывание из всех двоичных файлов:
root #prelink -au
Наконец, удалите сам пакет prelink:
root #emerge -c prelink
Известные проблемы и их решения
«Cannot prelink against non-PIC shared library» («Невозможно осуществить предварительное связывание с не-PIC-разделяемой библиотекой»)
Причина этой проблемы связана с плохо скомпилированными разделяемыми библиотеками, которые были скомпилированы без gcc опции -fPIC для всех их объектных файлов.
Библиотеки, которые не были исправлены или не могут быть исправлены:
- Библиотеки в wine пакете, включая winex. Предварительное связывание в любом случае не ускорит выполнение исполняемых файлов MS Windows.
- Библиотека в media-video/mjpegtools, /usr/lib/liblavfile-1.6.so.0.
- Библиотеки Nvidia OpenGl, /usr/lib/opengl/nvidia/lib/libGL.so.*. Из соображенияй производительности они были скомпилированы без поддержки PIC.
Если ваша проблемная библиотека не указана в списке, пожалуйста, сообщите об этом, желательно в виде patch’а добавив -fPIC в соответствующие CFLAGS.
Когда я применяю предварительное связывание к моей системе, некоторые статические двоичные файлы больше не работают
Когда дело касается glibc, нет такого понятия, как 100% статический двоичный файл. Если вы статически компилируете двоичный файл с помощью glibc, он все равно может зависеть от других системных файлов. Ниже приводится объяснение Дика Хауэлла (Dick Howell),
«Полагаю, идея состоит в том, что все должно находиться в загруженном файле, поэтому ничего не зависит от локальных библиотек целевой системы. К сожалению, в случае с Linux, и я думаю, с чем бы то ни было, что использует GLIBC, это не совсем так. Возьмем к примеру «libnss» (переключатель службы имен, некоторые люди называют его cbcntvjq сетевой системой безопасности), которая предоставляет функции для доступа к различным базам данных для аутентификации, сетевой информации и других вещей. Предполагается, что прикладные программы не зависят от отдельно настроенного реального сетевого окружения машины. Хорошая идея, но изменения в GLIBC могут привести к проблемам при ее загрузке. И вы не можете статически связать «libnss», поскольку она настроена для каждой машины отдельно. Проблема возникает, я думаю, в основном из-за статического связывания других GLIBC библиотек, в частности «libpthread», «libm» и «libc», из которых происходят несовместимые вызовы функций «libnss».»
К сожалению, в случае с Linux, и я думаю, с чем бы то ни было, что использует GLIBC, это не совсем так. Возьмем к примеру «libnss» (переключатель службы имен, некоторые люди называют его cbcntvjq сетевой системой безопасности), которая предоставляет функции для доступа к различным базам данных для аутентификации, сетевой информации и других вещей. Предполагается, что прикладные программы не зависят от отдельно настроенного реального сетевого окружения машины. Хорошая идея, но изменения в GLIBC могут привести к проблемам при ее загрузке. И вы не можете статически связать «libnss», поскольку она настроена для каждой машины отдельно. Проблема возникает, я думаю, в основном из-за статического связывания других GLIBC библиотек, в частности «libpthread», «libm» и «libc», из которых происходят несовместимые вызовы функций «libnss».»
Prelink прерывается с «prelink: dso.c: 306: fdopen_dso: Assertion ‘j == k’ failed.»
Это известная проблема, любезно диагностированная здесь. Prelink не может справиться с UPX-сжатыми исполняемыми файлами. Начиная с prelink-20021213, нет способа это исправить, кроме как скрыть исполняемые файлы во время предварительного связывания. Смотрите раздел выше для простого способа сделать это.
Начиная с prelink-20021213, нет способа это исправить, кроме как скрыть исполняемые файлы во время предварительного связывания. Смотрите раздел выше для простого способа сделать это.
Я использую grsecurity, и кажется, что предварительное связывание не работает.
Чтобы предварительно связать систему с grsecurity с использованием рандомизированной базы mmap(), необходимо включить параметр «randomized mmap() base» OFF для /lib/ld-2.3.*.so. Это можно сделать с помощью утилиты chpax, но это необходимо сделать, когда файл не используется (например, загрузиться с компакт-диска для восстановления).
Prelink падает с ошибкой «prelink: Can’t walk directory tree XXXX: Too many levels of symbolic links» («prelink: не удается обойти дерево каталогов XXXX: слишком много уровней символических ссылок»)
Ваши символьные ссылки вложены слишком глубоко. Это происходит, когда символьная ссылка указывает на себя. Например, наиболее распространенным является /usr/lib/lib -> lib. Чтобы это исправить, вы можете найти символьную ссылку вручную или использовать утилиту, предоставленную пакетом
Чтобы это исправить, вы можете найти символьную ссылку вручную или использовать утилиту, предоставленную пакетом symlinks:
root #emerge symlinks
root #symlinks -drv /
Более подробную информацию можно найти в Bugzilla и в этом сообщении на Форуме.
Заключение
Предварительное связывание может значительно ускорить время запуска для ряда крупных приложений. Его поддержка встроена в Portage. Также предварительное связывание безопасно, так как вы всегда сможете его отменить для любого двоичного файла при возникновении проблем. Просто помните, что при обновлении glibc или других библиотек, с которыми вы произвели предварительное связывание, вам нужно повторно запустить prelink! Короче, удачи!
This page is based on a document formerly found on our main website gentoo.org.
The following people contributed to the original document: Stefan Jones, John P. Davis, Jorge Paulo, Erwin, nightmorph
Davis, Jorge Paulo, Erwin, nightmorph
They are listed here because wiki history does not allow for any external attribution. If you edit the wiki article, please do not add yourself here; your contributions are recorded on each article’s associated history page.
Оценка классификатора (точность, полнота, F-мера)
21 July 2012 information retrieval classification
Продолжая тему реализации автоматической классификации необходимо обсудить следующий очень важный вопрос. Как оценивать качество алгоритма? Допустим, вы хотите внести изменения в алгоритм. Откуда вы знаете что эти изменения сделают алгоритм лучше? Конечно же надо проверять алгоритм на реальных данных.
Тестовая выборка
Основой проверки является тестовая выборка в которой проставлено соответствие между документами и их классами. В зависимости от ваших конкретных условий получение подобной выборки может быть затруднено, так как зачастую ее составляют люди. Но иногда ее можно получить без большого объема ручной работы, если проявить изобретательность. Каких-то конеретных рецептов, к сожалению, не существует.
Каких-то конеретных рецептов, к сожалению, не существует.
Когда у вас появилась тестовая выборка достаточно натравить классификатор на документы и соотнести его решение с заведомо известным правильным решением. Но для того чтобы принимать решение хуже или лучше справляется с работой новая версия алгоритма нам необходима численная метрика его качества.
Численная оценка качества алгоритма
Accuracy
В простейшем случае такой метрикой может быть доля документов по которым классификатор принял правильное решение.
где, – количество документов по которым классификатор принял правильное решение, а – размер обучающей выборки. Очевидное решение, на котором для начала можно остановиться.
Тем не менее, у этой метрики есть одна особенность которую необходимо учитывать. Она присваивает всем документам одинаковый вес, что может быть не корректно в случае если распределение документов в обучающей выборке сильно смещено в сторону какого-то одного или нескольких классов. В этом случае у классификатора есть больше информации по этим классам и соответственно в рамках этих классов он будет принимать более адекватные решения. На практике это приводит к тому, что вы имеете accuracy, скажем, 80%, но при этом в рамках какого-то конкретного класса классификатор работает из рук вон плохо не определяя правильно даже треть документов.
В этом случае у классификатора есть больше информации по этим классам и соответственно в рамках этих классов он будет принимать более адекватные решения. На практике это приводит к тому, что вы имеете accuracy, скажем, 80%, но при этом в рамках какого-то конкретного класса классификатор работает из рук вон плохо не определяя правильно даже треть документов.
Один выход из этой ситуации заключается в том чтобы обучать классификатор на специально подготовленном, сбалансированном корпусе документов. Минус этого решения в том что вы отбираете у классификатора информацию об отностельной частоте документов. Эта информация при прочих равных может оказаться очень кстати для принятия правильного решения.
Другой выход заключается в изменении подхода к формальной оценке качества.
Точность и полнота
Точность (precision) и полнота (recall) являются метриками которые используются при оценке большей части алгоритмов извлечения информации. Иногда они используются сами по себе, иногда в качестве базиса для производных метрик, таких как F-мера или R-Precision. Суть точности и полноты очень проста.
Суть точности и полноты очень проста.
Точность системы в пределах класса – это доля документов действительно принадлежащих данному классу относительно всех документов которые система отнесла к этому классу. Полнота системы – это доля найденных классфикатором документов принадлежащих классу относительно всех документов этого класса в тестовой выборке.
Эти значения легко рассчитать на основании таблицы контингентности, которая составляется для каждого класса отдельно.
В таблице содержится информация сколько раз система приняла верное и сколько раз неверное решение по документам заданного класса. А именно:
- — истино-положительное решение;
- — истино-отрицательное решение;
- — ложно-положительное решение;
- — ложно-отрицательное решение.
Тогда, точность и полнота определяются следующим образом:
Рассмотрим пример. Допустим, у вас есть тестовая выборка в которой 10 сообщений, из них 4 – спам. Обработав все сообщения классификатор пометил 2 сообщения как спам, причем одно действительно является спамом, а второе было помечено в тестовой выборке как нормальное.
 Мы имеем одно истино-положительное решение, три ложно-отрицательных и одно ложно-положительное. Тогда для класса “спам” точность классификатора составляет (50% положительных решений правильные), а полнота (классификатор нашел 25% всех спам-сообщений).
Мы имеем одно истино-положительное решение, три ложно-отрицательных и одно ложно-положительное. Тогда для класса “спам” точность классификатора составляет (50% положительных решений правильные), а полнота (классификатор нашел 25% всех спам-сообщений).Confusion Matrix
На практике значения точности и полноты гораздо более удобней рассчитывать с использованием матрицы неточностей (confusion matrix). В случае если количество классов относительно невелико (не более 100-150 классов), этот подход позволяет довольно наглядно представить результаты работы классификатора.
Матрица неточностей – это матрица размера N на N, где N — это количество классов. Столбцы этой матрицы резервируются за экспертными решениями, а строки за решениями классификатора. Когда мы классифицируем документ из тестовой выборки мы инкрементируем число стоящее на пересечении строки класса который вернул классификатор и столбца класса к которому действительно относится документ.
Матрица неточностей (26 классов, результирующая точность – 0. 8, результирующая полнота – 0.91)
8, результирующая полнота – 0.91)
Как видно из примера, большинство документов классификатор определяет верно. Диагональные элементы матрицы явно выражены. Тем не менее в рамках некоторых классов (3, 5, 8, 22) классификатор показывает низкую точность.
Имея такую матрицу точность и полнота для каждого класса рассчитывается очень просто. Точность равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота – отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
F-мера
Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в production (у кого больше тот и круче). Именно такой метрикой является F-мера1.
В этом случае нам будет проще принимать решение о том какую реализацию запускать в production (у кого больше тот и круче). Именно такой метрикой является F-мера1.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма.
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют F1).
Сбалансированная F-мера
F-мера с приоритетом точности ()
F-мера с приоритетом полноты ()
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея в своем распоряжении подобный механизм оценки вам будет гораздо проще принять решение о том являются ли изменения в алгоритме в лучшую сторону или нет.
Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея в своем распоряжении подобный механизм оценки вам будет гораздо проще принять решение о том являются ли изменения в алгоритме в лучшую сторону или нет.
Ссылки по теме
- Evaluation methods in text categorization
- Micro and macro average of precision
- Информационный поиск: Оценка эффективности — Wikipedia
- Precision and Recall — Wikipedia
- Classifier performance evaluation
иногда встречаются названия: F-score или мера Ван Ризбергена. ↩
TweetFollow
Please enable JavaScript to view the comments powered by Disqus.
Обобщение — ГИС Вики | Энциклопедия ГИС
Обобщение понятия является расширением понятия до менее конкретных критериев, другими словами, это абстракция данных в меньшем масштабе [1] . Обобщение есть акт упрощения. Это основополагающий элемент логики и человеческого мышления. Обобщение постулирует существование домена или набора элементов, а также одной или нескольких общих характеристик, общих для этих элементов. Как таковая, она является существенной основой любого действительного дедуктивного вывода. Процесс проверки необходим, чтобы определить, верно ли обобщение для любой данной ситуации.
Обобщение есть акт упрощения. Это основополагающий элемент логики и человеческого мышления. Обобщение постулирует существование домена или набора элементов, а также одной или нескольких общих характеристик, общих для этих элементов. Как таковая, она является существенной основой любого действительного дедуктивного вывода. Процесс проверки необходим, чтобы определить, верно ли обобщение для любой данной ситуации.
Успех автоматизированного обобщения зависит от перевода человеческих знаний о методах ручного обобщения в явные правила и логику, чтобы их можно было закодировать на компьютерном языке [2] . В учебниках очень мало руководств по ручному обобщению, и они обычно расплывчаты и неполны. Понятие обобщения имеет широкое применение во многих смежных дисциплинах, иногда имея особое значение, зависящее от контекста. Обобщая, вы можете консолидировать данные и отображать наиболее важную информацию.
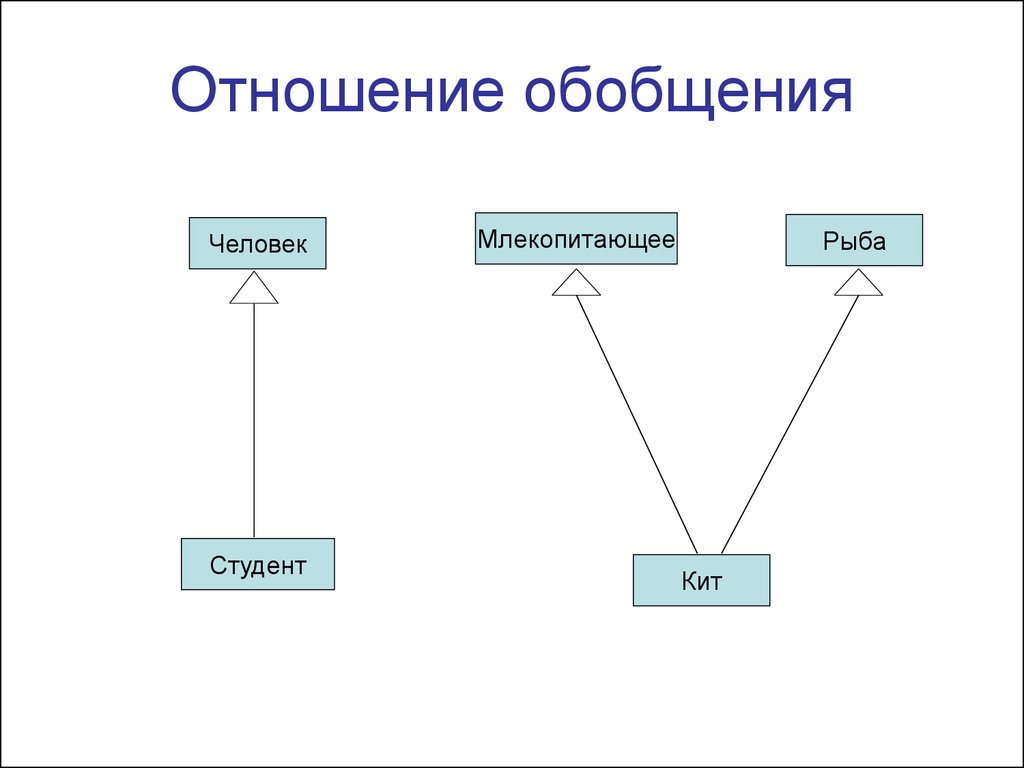
Для любых двух связанных понятий, A и B ; А считается обобщением понятия В тогда и только тогда, когда:
- каждый экземпляр концепции B также является экземпляром концепции A; и
- существуют экземпляры понятия A, которые не являются экземплярами понятия B.

Обобщение Дерево
Например, Растение является обобщением Дерево потому что каждое дерево является растением, а есть растения которые не являются деревьями (цветы, например).
ГИС-данные в нашем современном мире очень подробны, и нам нужно обобщать, чтобы лучше понять наши ГИС-данные. Данные ГИС почти всегда слишком подробны для нашей карты. Например, если мы хотим сделать карту штата Юта, мы не собираемся помещать на карту все дороги в Юте.
Важно помнить, что после того, как произошло обобщение, детали теряются. При работе с пространственными данными в ГИС эти упрощенные данные теперь менее точны в пространственном отношении. Эту потерю деталей следует учитывать при выполнении таких измерений, как длина, периметр или площадь, поскольку эти измерения теперь будут содержать некоторую погрешность. [3] Хотя обобщение в некотором смысле ограничивает, его следует рассматривать как положительный аспект ГИС. Ни один ГИС-проект не будет включать в себя все детали какой-либо конкретной области, поэтому обобщение неизбежно. Обобщение необходимо в той или иной степени на всех картах (или любом другом ГИС-проекте), чтобы оно было понятным и чтобы его тема выделялась. [4]
Ни один ГИС-проект не будет включать в себя все детали какой-либо конкретной области, поэтому обобщение неизбежно. Обобщение необходимо в той или иной степени на всех картах (или любом другом ГИС-проекте), чтобы оно было понятным и чтобы его тема выделялась. [4]
Содержание
- 1 Гипероним и Гипоним
- 2 Обобщение в картографии
- 3 ГИС и автоматизированное обобщение
- 3.1 Базы данных
- 4 Каталожные номера
- 5 См. также
Гипероним и гипоним
Гипероним — это термин, обобщающий класс или группу элементов с одинаковым рангом, или слово, под которое более конкретные слова подпадают категорически. Например, дерево является гипернимом для персика и дуба, , а корабль является гипернимом для крейсера 9.0014 и отпариватель . И наоборот, гипоним — это термин, который находится в отношениях типа с гипернимом. Гипоним — это слово, которое является более конкретным, чем общий термин, связанный с ним. Гипонимы, такие как клен и дуб , являются подкатегориями гипернима дерева , в то время как крейсер и пароход являются типами гипернима корабля . Гипероним выше гипонима, а гипоним ниже гипернима. Этот вид обобщение против специализации (или конкретизация ) отражаются в зеркале противопоставления гиперонимической и гипонимной пары слов. Понимание того, как использовать и применять гиперонимы и гипонимы, может очень помочь в обобщении картографии.
Гипоним — это слово, которое является более конкретным, чем общий термин, связанный с ним. Гипонимы, такие как клен и дуб , являются подкатегориями гипернима дерева , в то время как крейсер и пароход являются типами гипернима корабля . Гипероним выше гипонима, а гипоним ниже гипернима. Этот вид обобщение против специализации (или конкретизация ) отражаются в зеркале противопоставления гиперонимической и гипонимной пары слов. Понимание того, как использовать и применять гиперонимы и гипонимы, может очень помочь в обобщении картографии.
Обобщение в картографии
Основная статья: Картографическое обобщение
Обобщение всегда играло важную роль в картографии. Карты не могут передать каждую деталь реального мира, поэтому картографы должны решить, какая информация необходима для передачи их сообщения. Затем они обобщают содержимое своей карты, чтобы создать продукт, который передает желаемую геопространственную информацию в рамках их представления о мире. Каждая карта была в какой-то степени обобщена, и правильно обобщенные карты — это те, которые подчеркивают наиболее важные элементы карты, но при этом представляют мир наиболее точным и узнаваемым способом.
Каждая карта была в какой-то степени обобщена, и правильно обобщенные карты — это те, которые подчеркивают наиболее важные элементы карты, но при этом представляют мир наиболее точным и узнаваемым способом.
Картографы используют карты, чтобы рассказать историю, и они должны знать свою аудиторию, как человек, который рассказывает историю своему другу. Эта история нуждается в контексте и деталях, чтобы иметь смысл, но не слишком много деталей, чтобы слушатель не запутался. Обобщение используется в картах, чтобы избавиться от ненужных деталей и не запутать зрителя.
Различные методы или операции были разработаны для удаления, улучшения и подавления картографических визуальных деталей. Эти операции включают операции с содержимым, операции с геометрией и операции с символами. Подробное объяснение каждого типа операций см. в разделе об операциях генерализации при картографической генерализации.
ГИС и автоматизированное обобщение
С появлением ГИС в прошлом веке и автоматическим ростом спроса на создание карт автоматическое обобщение стало важным вопросом для национальных картографических агентств (NMA) и других поставщиков данных. Таким образом, автоматизированное обобщение описывает автоматизированное извлечение данных (становящихся затем информацией) относительно цели и масштаба. Разные исследователи изобретали концептуальные модели для автоматизированного обобщения:
Таким образом, автоматизированное обобщение описывает автоматизированное извлечение данных (становящихся затем информацией) относительно цели и масштаба. Разные исследователи изобретали концептуальные модели для автоматизированного обобщения:
- Грюнрайх модель
- Модель Brassel & Weibel
- Модель McMaster & Shea
Помимо этих установленных моделей, были установлены различные взгляды на автоматизированное обобщение. Двумя такими представлениями являются представление, ориентированное на представление, и представление, ориентированное на процесс. Первое представление фокусируется на представлении данных в разных масштабах, что связано с областью баз данных с несколькими представлениями (MRDB). Топографические карты и навигационные карты часто ориентированы на представление. Последняя точка зрения фокусируется на процессе обобщения. Это делается путем получения подробной базы данных и уменьшения ее сложности в зависимости от размера масштаба. [5]
Базы данных
В контексте создания баз данных разного масштаба существуют две распространенные стратегии: подход «лестница» и подход «звезда».
- Лестничный подход
Лестничный подход представляет собой пошаговое обобщение, в котором каждый полученный набор данных основан на другой базе данных следующего большего масштаба. Например, если целью было прореживание деталей карты масштаба 1:250 000, картограф сначала начал бы с масштаба 1:24 000 и обобщил детали. Затем она перейдет к масштабу 1:50 000, выполняя те же операции. Это постепенное увеличение будет продолжаться до тех пор, пока картограф не удовлетворится внешним видом в конечном масштабе 1: 250 000.
- Звездный подход
Звездный подход описывает производные данные во всех масштабах на основе единой (крупномасштабной) базы данных. Картограф имеет в виду ту же цель, что и в подходе с лестницей, но вместо постепенного увеличения картограф будет использовать 1:24 000 и сразу перейти к 1:250 000 или 1:100 000 и выполнить там обобщающие операции. [6]
Ссылки
- ↑ Харди, П., Ли, Д., Обобщение на основе ГИС и множественное представление пространственных данных Труды, ISGI 2005, Международный симпозиум по обобщению информации
- ↑ Харди, П. , Ли, Д., Обобщение на основе ГИС и множественное представление пространственных данных Труды, ISGI 2005, Международный симпозиум по обобщению информации
- ↑ Демпси, Кейтлин. «Обобщение в ГИС». GIS Lounge, 30 ноября 2014 г. Интернет. https://www.gislounge.com/generalization-gis/
- ↑ Джудит А. Тайнер, Принципы дизайна карты (Нью-Йорк: Гилфорд Пресс, 2010), 82.
- ↑ Вейбель, Р. и Даттон, Г. «Обобщение пространственных данных и работа с множественными представлениями». http://www.geos.ed.ac.uk/~gisteac/gis_book_abridged/files/ch20.pdf.
- ↑ Росс, Кевин. «Лестница против звезды: сравнение двух подходов для обобщения данных гидрологических линий потока в нескольких масштабах».
 , Ли, Д., Обобщение на основе ГИС и множественное представление пространственных данных Труды, ISGI 2005, Международный симпозиум по обобщению информации
, Ли, Д., Обобщение на основе ГИС и множественное представление пространственных данных Труды, ISGI 2005, Международный симпозиум по обобщению информации- Рот Р.Э., Страйкер М., Брюэр К.А. (2003). «Типология ScaleMaster: литературный фонд», Университет Пенсильвании .
См. также
- Абстракция
- При прочих равных условиях
- Универсальный
- Общий предшественник
- наследование (объектно-ориентированное программирование),
- Неверное обобщение
- Поспешное обобщение
- С соответствующими изменениями
- -имя
- Диаграмма классов
- Алгоритм Рамера-Дугласа-Пекера
- Специализация, обратный процесс
Обобщение стимула | Психология Вики
в: Обобщение (обучение), Обучение
Посмотреть исходный код Оценка |
Биопсихология |
Сравнительный |
Познавательный |
Развивающие |
Язык |
Индивидуальные различия |
Личность |
Философия |
Социальные |
Методы |
Статистика |
Клинический |
Образовательные |
промышленный |
Профессиональные товары |
Мировая психология |
Когнитивная психология: Внимание · Принятие решения · Обучение · Суждение · Память · Мотивация · Восприятие · Рассуждение · Думая — Когнитивные процессы Познание — Контур Индекс
Обобщение стимула или первичное обобщение — это склонность стимулов, сходных с исходным стимулом в парадигме обучения, вызывать реакцию, близкую к реакции, усвоенной в исходных условиях.