Логика сознания. Часть 10. Задача обобщения / Хабр
В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.
Взаимодействие с окружающим миром приводит к накоплению опыта. Если в этом опыте есть какие-либо закономерности, то они могут быть выделены и впоследствии использованы. Наличие закономерностей можно интерпретировать, как присутствие чего-то общего в воспоминаниях, составляющих опыт. Соответственно, выделение таких общих сущностей принято называть обобщением.
Задача обобщения – это ключевая задача во всех дисциплинах, которые хоть как-то связаны с анализом данных.
Несмотря на то, что обобщение возникает всегда и везде сама задача обобщения, если рассматривать ее в общем виде, остается достаточно туманной. В зависимости от конкретной ситуации в которой требуется выполнить обобщение постановка задачи обобщения может меняться в очень широком диапазоне. Различные постановки задачи порождают очень разные и порой совсем непохожие друг на друга методы решения.
Многообразие подходов к обобщению создает ощущение, что процедура обобщения – это нечто собирательное и что универсальной процедуры обобщения, видимо, не существовует. Однако, мне кажется, что универсальное обобщение возможно и именно оно и свойственно нашему мозгу. В рамках описываемого в этом цикле подхода удалось придумать удивительно красивый (по крайней мере мне он кажется таким) алгоритм, который включает в себя все классические вариации задачи обобщения.
Перед тем как описывать алгоритм такого универсального обобщения попробуем разобраться с тем какие формы обобщения принято выделять и, соответственно, что и почему должен включать в себя универсальный подход.
Философско-семантический подход к обобщению понятий
Философия имеет дело с семантическими конструкциями. Проще говоря, выражает и записывает свои утверждения фразами на естественном языке. Философско-семантический подход к обобщению заключается в следующем. Имея понятия, объединенные неким видовым признаком, требуется перейти к новому понятию, которое дает более широкое, но менее конкретное толкование, свободное от видового признака.
Например, имеется понятие «наручные часы», которое описывается как: «указатель времени, закрепленный на руке с помощью ремешка или браслета». Если мы избавимся от видового признака «закрепленный на руке…», то получим обобщенное понятие «часы», как любой инструмент, определяющий время.
Если мы избавимся от видового признака «закрепленный на руке…», то получим обобщенное понятие «часы», как любой инструмент, определяющий время.
В примере с часами в самом названии наручных часов содержалась подсказка для обобщения. Достаточно было отбросить лишнее слово и получалось требуемое понятие. Но это не закономерность, а следствие семантики, построенной «от обратного», когда нам уже известен результат обобщения.
Задача чистого обобщения
В формулировке Френка Розенблатта задача чистого обобщения звучит так: «В эксперименте по «чистому обобщению» от модели мозга или персептрона требуется перейти от избирательной реакции на один стимул (допустим, квадрат, находящийся в левой части сетчатки) к подобному ему стимулу, который не активирует ни одного из тех же сенсорных окончаний (квадрат в правой части сетчатки)» (Rosenblatt, 1962).
Акцент на «чистое» обобщение подразумевает отсутствие «подсказок». Если бы нам предварительно показали квадрат во всех возможных позициях сетчатки и дали возможность все это запомнить, то узнавание кадрата стало бы тривиальным. Но по условию квадрат нам показали в одном месте, а узнать мы должны его совсем в другом. Сверточные сети решают эту задачу за счет того, что в них изначально заложены правила «перетаскивания» любой фигуры по всему пространству сетчатки. За счет знания того как «перемещать» изображение они могут взять квадрат, увиденный в одном месте и «примерить» его ко всем возможным позициям на сетчатке.
Но по условию квадрат нам показали в одном месте, а узнать мы должны его совсем в другом. Сверточные сети решают эту задачу за счет того, что в них изначально заложены правила «перетаскивания» любой фигуры по всему пространству сетчатки. За счет знания того как «перемещать» изображение они могут взять квадрат, увиденный в одном месте и «примерить» его ко всем возможным позициям на сетчатке.
Поиск паттерна в форме буквы «T» в разных позициях изображения (Fukushima K., 2013)
Ту же задачу мы в нашей модели решаем за счет создания пространства контекстов. Отличие от сверточных сетей в том, кто к кому идет — «гора к Магомеду» или «Магомед к горе». В сверточных сетях при анализе новой картинки каждый предварительно известный образ варьируется по всем возможным позициям и «примеряется» к анализируемой картинке. В контекстной модели каждый контекст трансформирует (перемешает, поворачивает, масштабирует) анализируемую картинку так как ему предписывают его правила, а затем «сдвинутая» картинка сравнивается с «неподвижными» заранее известными образами. Эта, на первый взгляд, небольшая разница дает последующее очень сильное различее в подходах и их возможностях.
Эта, на первый взгляд, небольшая разница дает последующее очень сильное различее в подходах и их возможностях.
Родственна задаче чистого обобщения задача инвариантного представления. Имея явление, предстающее перед нами в разных формах, требуется инвариантно описать эти представления с целью узнавания явления в любых его проявлениях.
Задача классификации
Есть множество объектов. Есть предварительно заданные классы. Есть обучающая выборка – набор объектов, про которые известно к каким классам они относятся. Требуется построить алгоритм, который обоснованно отнесет любые объекты из исходного множества к одному из классов. В математической статистике задачи классификации относят к задачам дискриминантного анализа.
В машинном обучении задача классификации считается задачей обучения с учителем. Есть обучающая выборка, про которую известно: какой стимул на входе приводит к какой реакции на выходе. Предполагается, что реакция не случайна, а определяется некой закономерностью.
Алгоритм решение задачи классификации зависит от характера входных данных и типов получаемых классов. О том, как решается задача классификации в нейронных сетях и как происходит обучение с учителем в нашей модели мы говорили в предыдущей части.
Задача кластеризации
Предположим у нас есть множество объектов и нам известна степень похожести их друг на друга, заданная матрицей расстояний. Требуется разбить это множество на подмножества, называемые кластерами, так, чтобы каждый кластер объединял схожие объекты, а объекты разных кластеров сильно отличались друг от друга. Вместо матрицы расстояний могут быть заданы описания этих объектов и указан способ, как искать расстояние между объектами по этим описаниям.
В машинном обучении, кластеризация попадает под обучение без учителя.
Кластеризация – очень соблазнительная процедура. Удобно разбить множество объектов на относительное небольшое количество классов и впоследствии использовать не исходные, возможно громоздкие описания, а описания через классы.
Однако, в общем случае ответ на вопрос о важности признаков лежит за пределами задачи кластеризации. Последующее обучение, называемое обучением с подкреплением, должно само, исходя из анализа того насколько удачно или нет оказалось поведение ученика, определить какие признаки важны, а какие нет. При этом «самыми удачными» признаками могут оказаться не признаки из исходных описаний, а уже обобщенные классы, взятые как признаки. Но для определения важности признаков надо, чтобы эти признаки уже присутствовали в описании на момент работы обучения с подкреплеием. То есть получается, что заранее неизвестно какие признаки могут оказаться важными, но понять это можно только уже имея эти признаки.
Другими словами, в зависимости от того какие признаки исходного описания использовать, а какие игнорировать при проведении кластеризации получаются различные системы классов. Одни из них оказываются более полезными для последующих целей, другие менее. В общем случае выходит, что хорошо бы перебрать все возможные варианты кластеризаций, чтобы понять какие из них наиболее удачны для решения конкретной задачи. Причем для решения другой задачи может оказаться удачной совсем другая система кластеризации.
Одни из них оказываются более полезными для последующих целей, другие менее. В общем случае выходит, что хорошо бы перебрать все возможные варианты кластеризаций, чтобы понять какие из них наиболее удачны для решения конкретной задачи. Причем для решения другой задачи может оказаться удачной совсем другая система кластеризации.
Даже если мы решим на что стоит сделать акцент при кластеризации все равно останется вопрос об оптимальной детализации. Дело в том, что в общем случае нет априорной информации о том на сколько классов надо поделить исходное множество объектов.
Вместо знания о количестве классов можно использовать критерий, указывающий на то насколько точно должны все объекты соответствовать созданным классам. В этом случае можно начинать кластеризацию с некого начального количества классов и добавлять новые классы если остаются объекты, для которых ни один класс не подходит достаточно хорошо. Но процедура с добавлением не снимает вопроса оптимальности детализации. При задании низкого порога соответствия объекта классу получаются большие классы, отражающие основные закономерности. При выборе высокого порога получается много классов с небольшим числом объектов. Эти классы учитывают мелкие детали, но за деревьями становится не видно леса.
При выборе высокого порога получается много классов с небольшим числом объектов. Эти классы учитывают мелкие детали, но за деревьями становится не видно леса.
Факторный анализ
Удобно центрировать описания, то есть рассчитать среднее для каждого признака и скорректировать признаки на их среднее значение. Это равносильно переносу начала координат в «центр масс». Можно посчитать корреляции между признаками. Если записать корреляционную матрицу признаков и найти ее собственные вектора, то эти вектора будут являться новым ортогональным базисом, в котором можно описать исходное множество объектов.
В базисе из исходных признаков за счет их возможной коррелированности линейные закономерности были «размазаны» между признаками.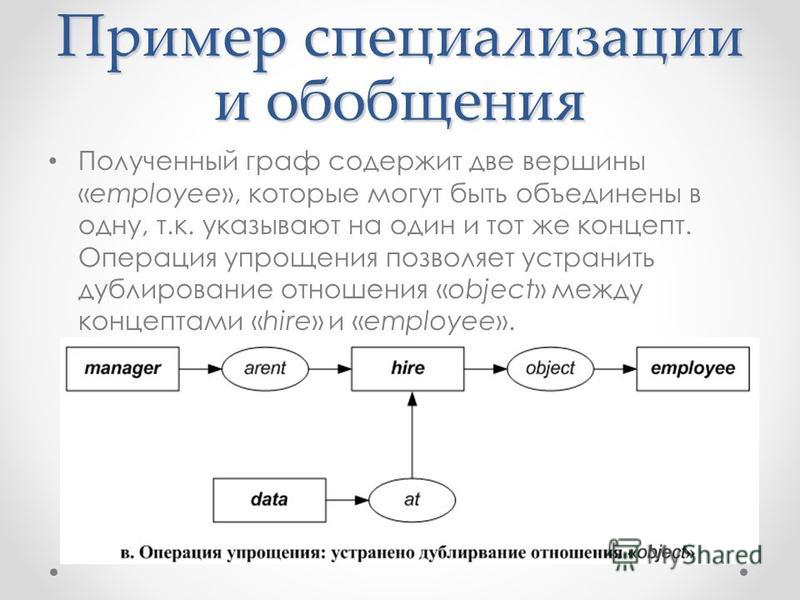 При переходе к ортогональному базису начинает четче проступать внутренняя структура закономерностей. Так как ортогональный базис определен с точностью до вращения, то можно так повернуть базис из собственных векторов, чтобы направления осей наилучшим образом соответствовали тем направлениям, вдоль которых данные имеют наибольший разброс.
При переходе к ортогональному базису начинает четче проступать внутренняя структура закономерностей. Так как ортогональный базис определен с точностью до вращения, то можно так повернуть базис из собственных векторов, чтобы направления осей наилучшим образом соответствовали тем направлениям, вдоль которых данные имеют наибольший разброс.
Собственные числа, соответствующие собственным векторам, показывают какой процент от общей дисперсии приходится на какой собственный вектор. Собственные вектора, на которые приходится наиболее существенный процент дисперсии называют главными компонентами. Часто бывает удобно перейти от описания в исходных признаках к описанию в главных компонентах.
Так как главные компоненты отражают наиболее существенные линейные закономерности, свойственные исходному множеству, то они могут называться определенным обобщением исходных данных.
Замечательное свойство факторного анализа — это то, что факторы могут не только напоминать исходные признаки, но и могут оказаться новыми ненаблюдаемыми сущностями.
Если сравнивать обобщения, которые получаются через классы и которые получаются через факторы, то условно можно сказать, что классы выделяют «области», а факторы – «направления».
Часто для отнесения объекта к классу смотрят не столько на близость объекта к центру класса, а на соответствие объекта параметрам распределения, свойственным классу (на этом, например, построен EM алгоритм). То есть если в пригороде города стоит тюрьма, то человек которого вы встретите рядом с тюрьмой скорее всего горожанин, а не заключенный, хотя расстояние до центра города значительно выше чем до центра тюрьмы. «Области» стоит понимать с учетом этого замечания.
Ниже приведена картинка, по которой можно приблизительно соотнести обобщение классами и факторами.
Графики распределения роста и веса игроков американской футбольной лиги (NFL). Сверху игроки защиты, снизу игроки нападения. Цветами выделены позиции игроков (Dr. Craig M. Booth).
Все множество игроков можно разбить на классы по их роли на поле. По параметрам «вес — рост» можно выделить глобальные факторы (не показаны) или факторы для каждого из классов.
По параметрам «вес — рост» можно выделить глобальные факторы (не показаны) или факторы для каждого из классов.
Цветные линии соответствуют первому главному фактору в каждом из классов. Этот фактор можно интерпретировать как «размер игрока». Он определяется как проекция точки игрока на эту ось. Значение проекции дает значение, которое отбрасывает «не идеальность» игрока. Если к первой оси провести вторую ортогональную, то она будет описывать второй фактор «тип телосложения», проще говоря, худой игрок или толстый.
При всей красоте и удобстве факторов есть с ними и сложности. Так же, как и с классами всегда стоит вопрос сколько и каких факторов стоит выделять и использовать. Конечно, удобно, когда несколько первых главных компонент несут почти всю информацию, но на практике такое бывает нечасто. Например, возьмем 10 000 наиболее популярных фильмов, несколько миллионов человек и проанализируем оценки, которые они поставили тем фильмам, что посмотрели. Несложно составить корреляционную матрицу для фильмов. Положительная корреляция между двумя фильмами говорит о том, что люди, которые оценивают один фильм выше среднего скорее всего выше среднего оценивают и другой.
Положительная корреляция между двумя фильмами говорит о том, что люди, которые оценивают один фильм выше среднего скорее всего выше среднего оценивают и другой.
Проведем факторный анализ корреляционной матрицы и затем вращение осей для удобной интерпретации факторов. Окажется, что существенную роль играют первые пять-шесть факторов. Они соответствуют наиболее общим закономерностям. Это, конечно, жанры фильмов: «боевик», «комедия», «мелодрама». Кроме того, выделятся факторы: «русское кино» (если люди будут из России) и «авторское кино». Последующие факторы тоже можно интерпретировать, но их вклад в объяснение дисперсии будет все меньше и меньше.
Первые пять самых существенных факторов объясняют порядка 30 процентов общей дисперсии. Это не особо много, учитывая, что дисперсия – это квадрат среднеквадратического отклонения. Соответственно, основные факторы объясняют всего 17 процентов общего разброса оценок. Если посмотреть на остальные факторы, то многие из них объясняют всего лишь десятые или сотые доли процента общей дисперсии и вроде бы несущественны.
Но каждый мелкий фактор, как правило, соответствует некой локальной закономерности. Он объединяет фильмы одного режиссера, одного сценариста или одного актера. Оказывается, что когда мы хотим что-либо понять про конкретный фильм, то основные факторы объясняют свои 30 процентов дисперсии и при этом процентов 40-50 дисперсии объясняют один-два мелких фактора, которые несущественны для общей массы, но оказываются чрезвычайно важны именно для этого фильма.
Принято говорить, что «дьявол в деталях». Это относится именно к тому, что практически нет факторов, которыми можно пренебречь. Каждая мелочь может оказаться решающей в определенной ситуации.
Формирование понятий
Результатом обобщения может являться формирование понятий с использованием которых строятся последующие описания. Есть разные мнения относительно того, что является основным принципом, по которому человек выделяет те или иные понятия. Собственно, все пункты настоящего перечисления имеют к этому непосредственное отношение.
Задача идеализации
В процессе обобщения мы получаем понятия, которые по неким признакам объединяют множество явлений, с которыми мы ранее сталкивались. Выделение того общего, что есть в этих явлениях приводит к тому, что мы можем описать свойства неких идеальных понятий, свободных от индивидуальных деталей отдельных явлений.
Именно идеальные понятия лежат в основе математики. Точка, прямая, плоскость, число, множество – это идеализации объектов из нашего повседневного опыта. Математика вводит для этих понятий формальную систему правил, которая позволяет строить утверждения, преобразовывать эти утверждения, доказывать или опровергать их истинность. Но если для самой математики базовые понятия первичны, то для человека они связаны с опытом их использования. Это позволяет математикам не использовать полный перебор при поисках доказательств, а осуществлять более целенаправленный поиск, основанный на опыте, лежащем за идеальными понятиями.
Логическая индукция
Логическая индукция подразумевает получение общего закона по множеству частных случаев.
Разделяют полную индукцию:
Множество А состоит из элементов: А1, А2, А3, …, Аn.
- А1 имеет признак В
- А2 имеет признак В
- Все элементы от А3 до Аn также имеют признак В
Следовательно, все элементы множества А имеют признак В.
И неполную индукцию:
Множество А состоит из элементов: А1, А2, А3, …, Аn.
- А1 имеет признак В
- А2 имеет признак В
- Все элементы от А3 до Аk также имеют признак B
Следовательно, вероятно, Аk+1 и остальные элементы множества А имеют признак В.
Неполная индукция имеет дело с вероятностью и может быть ошибочной (проблема индукции).
Индукция связана с обобщением в двух моментах. Во-первых, когда говорится о множестве объектов, то подразумевается, что предварительно что-то послужило основанием объединить эти объекты в единое множество. То есть нашлись какие-то механизмы, которые позволили сделать предварительное обобщение.
Во-вторых, если мы методом индукции обнаруживаем некий признак, который свойственен элементам некой группы, которая описывает определенное понятие, то мы можем использовать этот признак, как характеризующий для отнесения к этой группе.
Например, мы обнаруживаем, что существуют механические приборы с характерным циферблатом и стрелками. По внешнему сходству мы делаем обобщение и относим их к классу часы, и формируем соответствующее понятие.
Далее мы замечаем, что часы могут определять время. Это позволяет нам сделать неполную индукцию. Мы заключаем, что свойство всех часов – способность определять время.
Теперь мы можем сделать следующий шаг обобщения. Мы можем сказать, что к «часам» можно отнести вообще все, что позволяет следить за временем. Теперь часами мы можем назвать и солнце, которое отмеряет сутки и школьные звонки, отсчитывающие уроки.
Логическая индукция имеет много общего с семантическим обобщением понятий. Но семантическое обобщение делает несколько иной акцент. Семантический подход говорит о признаках, которые составляют описание понятия, и возможности отбрасывания их части для получения более общей формулировки. При этом остается открытым вопрос — откуда должны взяться такие определения понятий, которые позволят выполнить переход к обобщению «через отбрасывание». Неполная логическая индукция как раз и показывает путь формирования таких описательных признаков.
Задача дискретизации
Имея дело с непрерывными величинами, часто требуется перейти к их описанию в дискретных значениях. Для каждой непрерывной величины выбор шага квантования определяется той точностью описания, которую требуется сохранить. Получившиеся в результате интервалы дробления объединяют различные значения непрерывной величины, ставя им в соответствие определенные дискретные понятия. Такую процедуру можно отнести к обобщению по тому факту, что объединение значений происходит, исходя из их попадания в интервал квантования, что говорит об их определенной общности.
Получившиеся в результате интервалы дробления объединяют различные значения непрерывной величины, ставя им в соответствие определенные дискретные понятия. Такую процедуру можно отнести к обобщению по тому факту, что объединение значений происходит, исходя из их попадания в интервал квантования, что говорит об их определенной общности.
Соотнесение понятий
Осуществляя обобщение любым из возможных способов, мы можем представить результат обобщения через систему понятий. При этом обобщенные понятия не просто образуют набор независимых друг от друга элементов, а приобретают внутреннюю структуру взаимоотношений.
Например, классы, получаемые в результате кластеризации, образуют некую пространственную структуру, в которой какие-то классы оказываются ближе друг к другу, какие-то дальше.
При использовании описания чего-либо через факторы используют набор факторных весов. Факторные веса принимают вещественные значения. Эти значения можно аппроксимировать набором дискретных понятий. При этом для этих дискретных понятий будет характерна система отношений «больше – меньше».
При этом для этих дискретных понятий будет характерна система отношений «больше – меньше».
Таким образом, нас каждый раз интересует не просто выделение обобщений, но и формирование некой системы, в которой будет понятно, как эти обобщения соотносятся со всеми остальными обобщениями.
Чем-то похожая ситуация возникает при анализе естественного языка. Слова языка имеют определенные взаимосвязи. Природа этих связей может быть различна. Можно говорить о частоте совместного проявления слов в реальных текстах. Можно говорить о похожести их смыслов. Можно строить систему отношений, основанную на переходах к более общему содержанию. Подобные построения приводят к семантическим сетям разного вида.
Пример семантической сети (Автор: Знанибус — собственная работа, CC BY-SA 3.0, commons.wikimedia.org/w/index.php?curid=11912245)
Говорят, что в правильной постановке задачи содержится три четверти верного ответа. Очень похоже, что это справедливо и для задачи обобщения. Что мы хотим видеть результатом обобщения? Устойчивые классы? Но где границы этих классов? Факторы? Какие и сколько? Закономерности? Редкие, но сильные совпадения или нечеткие, но подкрепленные большим числом примеров зависимости? Если мы накопили данные и провели обобщения, то как из множества возможных понятий выбрать те, что лучше всего подходят для описания конкретной ситуации? Что вообще есть обобщения? Как выглядит система соотнесения обобщений между собой?
Что мы хотим видеть результатом обобщения? Устойчивые классы? Но где границы этих классов? Факторы? Какие и сколько? Закономерности? Редкие, но сильные совпадения или нечеткие, но подкрепленные большим числом примеров зависимости? Если мы накопили данные и провели обобщения, то как из множества возможных понятий выбрать те, что лучше всего подходят для описания конкретной ситуации? Что вообще есть обобщения? Как выглядит система соотнесения обобщений между собой?
Далее я попробую дать и «правильную» постановку задачи, и возможный ответ, подкрепленный работающим кодом. Но это будет через статью. Пока же, в следующей части, нам предстоит познакомиться с одной очень важной биологической подсказкой, дающей, пожалуй, главный ключ к пониманию механизма обобщения.
Алексей Редозубов
Логика сознания. Часть 1. Волны в клеточном автомате
Логика сознания. Часть 2. Дендритные волны
Логика сознания. Часть 3. Голографическая память в клеточном автомате
Логика сознания.Часть 4. Секрет памяти мозга
Логика сознания. Часть 5. Смысловой подход к анализу информации
Логика сознания. Часть 6. Кора мозга как пространство вычисления смыслов
Логика сознания. Часть 7. Самоорганизация пространства контекстов
Логика сознания. Пояснение «на пальцах»
Логика сознания. Часть 8. Пространственные карты коры мозга
Логика сознания. Часть 9. Искусственные нейронные сети и миниколонки реальной коры
Логика сознания. Часть 10. Задача обобщения
Логика сознания. Часть 11. Естественное кодирование зрительной и звуковой информации
Логика сознания. Часть 12. Поиск закономерностей. Комбинаторное пространство
Логика сознания. Часть 13. Мозг, смысл и конец света
 Часть 4. Секрет памяти мозга
Часть 4. Секрет памяти мозгаМастер-класс «Асимптотически квазитеплицевы цепи Маркова и их обобщения с примерами применение в теории систем массового обслуживания с коррелированными потоками»
Cookie-файлы
Этот сайт использует файлы cookie. Собранная при помощи cookie информация не может идентифицировать вас, однако может помочь нам улучшить работу нашего сайта. Продолжая использовать сайт, вы даете согласие на обработку файлов cookie.
Продолжая использовать сайт, вы даете согласие на обработку файлов cookie.
Хорошо
Подробнее
Медиа-центр
Календарь мероприятий
Мастер-класс «Асимптотически квазитеплицевы цепи Маркова и их обобщения с примерами применение в теории систем массового обслуживания с коррелированными потоками»
Мероприятие прошло
2 декабря 2021
Место проведения
Участие online
Направление: Наука, Образование, Жизнь РУДН
Поднаправление: Математика и телекоммуникации
Формат: Мастер-класс
Организатор: Институт прикладной математики и телекоммуникаций
Тип: Факультетский
Контактное лицо
Кущазли Анна Ивановна
О мероприятии
2 декабря с 16:00 до 17:00 по московскому времени
Сформулированы достаточные условия эргодичности и неэргодичности этих цепей и рекомендации по их преобразованию к прозрачной скалярной форме, описаны численно устойчивые алгоритмы расчета их стационарного распределения. Алгоритмы основаны на замене системы уравнений Колмогорова для векторов стационарных вероятностей системой уравнений равновесия для семейства сенсорных цепей для исходной цепи с различными уровнями сенсорирования. Результаты даны для цепей с дискретным и непрерывным временем, отличающиеся формой представления. Приведены примеры применения таких систем к исследованию однолинейных и многолинейных систем с повторными вызовами и с нетерпеливыми запросами с групповыми марковскими потоками и маркированными марковскими потоками.
Алгоритмы основаны на замене системы уравнений Колмогорова для векторов стационарных вероятностей системой уравнений равновесия для семейства сенсорных цепей для исходной цепи с различными уровнями сенсорирования. Результаты даны для цепей с дискретным и непрерывным временем, отличающиеся формой представления. Приведены примеры применения таких систем к исследованию однолинейных и многолинейных систем с повторными вызовами и с нетерпеливыми запросами с групповыми марковскими потоками и маркированными марковскими потоками.
Кроме того, подробно рассмотрен класс цепей Маркова с почти верхне-хессенберговой структурой матрицы переходных вероятностей или инфинитезимального генератора и наличием дополнительного ненулевого первого блочного столбца. Цепи такого вида адекватно описывают, например, системы обслуживания с наличием катастрофических сбоев, приводящих к опустошению системы, и системы с групповым обслуживанием запросов группами неограниченного объема (например, модели систем с широковещательным обслуживанием пользователей).
Спикер
Дудина Александра Николаевича – профессор, ведущий специалист в области теории вероятностей.
Участие online
Ссылка на семинар
Предыдущее мероприятие
2 декабря
Семинар «Аксиоматический подход к функциональной биодинамике человеческого организма»
Следующие мероприятие
2 декабря
Семинар «Аксиоматический подход к функциональной биодинамике человеческого организма»
Семинар «Аксиоматический подход к функциональной биодинамике человеческого организма»
Ядро аксиоматической теории для дальнейшего преобразования в модели динамики конкретных сложных систем в здравоохранении и медицине основывается на отделении функциональной организации от материальной реализации и переводит динамические особенности физиологической функции в математические уравнения с феноменологической точки зрения.
Направление: Наука, Образование, Жизнь РУДН
Формат: Семинар
Организатор: Математический институт им. С.М. Никольского
Научный семинар «Renewable energy in Russia: prospects and challenges»
В ходе семинара докладчики рассмотрят проблему обновляемых источников энергии в России и обсудят с модератором перспективы внедрения лучших мировых практик в области возобновляемой энергии на территории РФ.
Направление: Образование, Жизнь РУДН
Формат: Семинар
Организатор: Институт экологии
Научный семинар «Механизмы синтеза ответа интеллектуальным агентом на заданный на естественном языке вопрос (Visual Question Answering)»
Рассматривается современный подход к объединению символьной и образной компонент описания внешней среды агента, за счет которого происходит поиск логичного ответа на поставленный на естественном языке вопрос. Будет представлен обзор современных механизмов VQA и примеры их использования в рамках манипуляционных робототехнических задач.
Будет представлен обзор современных механизмов VQA и примеры их использования в рамках манипуляционных робототехнических задач.
Направление: Наука, Образование, Жизнь РУДН
Формат: Семинар
Организатор: Институт прикладной математики и телекоммуникаций
VII Международная научно-практическая конференция «Би-, поли-, транслингвизм и лингвистическое образование»
Цель конференции — производство знаний о русско-инофонном двуязычии, би-, поли-, транслингвизме, билингвальном образовании, изменении этнического и языкового сознания, русскоязычии – транслингвизме, результатах взаимодействия языков и культур, транслятологии.
Направление: Образование, Международное сотрудничество
Формат: Конференция
Организатор: Институт русского языка
Детектив ошибок
ВАЖНЫЙ: Прочитайте это письмо очень внимательно. Внизу небольшой тест который вы можете взять, если хотите. Если вы ответите на все вопросы правильно, то вы получите маленькую, неважную и вообще не очень большой приз.
Обобщения
Мы все обобщаем о вещах. То есть мы все делаем широкие комментарии
о группе людей или вещей. Мы говорим что-то вроде:
Мы говорим что-то вроде:
«Что бы они ни говорили, продавцам наплевать на люди, которым они продают. Им просто нужны ваши деньги.»
Мы говорим это, потому что встречали многих продавцов, слышали от наших друзей о многих продавцах, или сами когда-то были продавцами. Мы обобщаем каждый день, и это очень полезно. (Видите, последнее предложение было обобщение.)
Мы делаем прогнозы относительно того, что кто-то собирается сделать до того, как он делаем это, и иногда мы правы. Например: вы играете игра Clue с Дженни и Бертом. Берт, после одного из своих ходов, кладет карты с кривой улыбкой и начинает изучать потолок безразлично. Вы уже видели этот взгляд. Это значит у него есть решение, и он собирается выиграть игру.
На следующий ход он побеждает. Вы знали, что он будет, потому что вы обобщили.
Вы заметили, что он делал такие вещи в прошлых играх, когда выигрывал,
и вы обобщили, что он сделал бы то же самое на этот раз.
Когда вы изучаете примеры людей или вещей в классе, вы берешь «выборку», из которой делаешь обобщение о вещах в классе. Вы говорите: «Все продавцы (т. класс здесь «торговцы») стяжатели» или, «92,93% продавцов — стяжатели» на основе ваше обобщение.
Если вы не знаете, что делаете, берете образцы и делаете обобщения может быть рискованным делом. Когда наши образцы и обобщения не проведенные должным образом, они называются «поспешным обобщением».
О поспешных обобщениях я расскажу ниже. Прямо сейчас ты нужно знать…..
Некоторые комментарии к обобщениям, особенно о том, как сделать хорошие:
1. Обобщения должны основываться на выборках, взятых из класса не на изучении всех или каждой вещи в классе.
Если я изучу каждого политика (класс здесь «все
политиков»), что когда-либо было, и обнаружил, что каждый был
коррумпирован, а потом сказал так, я бы не стал обобщать, когда сказал
«Все политики коррумпированы». я бы констатировал что
Я знал, что это правда.
я бы констатировал что
Я знал, что это правда.
2. Обобщение может быть сильным или слабым.
Обобщения полезны, потому что с ними не нужно изучите каждую вещь в классе, прежде чем сделать вывод. Если бы мы пытались выяснить, все ли политики коррумпированы, было бы очень утомительно исследовать каждого политика, когда-либо существовавшего на планете (а в последнее время и в космосе), чтобы проверить, не взял взятку.
Итак, обобщаем. Тем не менее, вы никогда ДЕЙСТВИТЕЛЬНО не знаете, обобщение совершенно верно до тех пор, пока вы не исследуете каждый отдельный политик; всегда есть шанс, что вы позже найдете тот, кто не коррумпирован.
Следовательно, мы должны сказать, что обобщение не может быть истинным или ложным;
оно может быть только сильным или слабым. Сильное обобщение такое, которое
скорее всего правильно.
3. Любое обобщение должно быть ниспровергнуто или, по крайней мере, должно быть скорректировано одним противоположным случаем.
Если бы я изучил 3 000 000 политиков по всему миру и нашел бы что все они были коррумпированы, я могу обобщить, что все политики коррумпированы. Но если бы я нашел хоть одного политика, который не был бы коррумпирован (может быть, он жил где-то в джунглях и не показывался для переписи), я должен был бы выбросить свое обобщение или хотя бы изменить его: «Все политики кроме один из тех, кого я знаю, живет в джунглях испорчен». Или: «Все политики, которых я изучал, коррумпированы». Или еще лучше: «Большинство политиков коррумпированы».
4. Обобщение становится сильнее при нахождении большей выборки и путем нахождения более репрезентативных образцов.
Хорошее обобщение — это то, которое исследует большую выборку,
разбросаны по всем углам изучаемого класса. Я буду
покройте это более подробно далее.
Я буду
покройте это более подробно далее.
ПОСПЕШНЫЕ ОБОБЩЕНИЯ.
Самая распространенная логическая ошибка — поспешные обобщения. Ах, вот мы идем с другим обобщением!
Поспешное обобщение — это такое обобщение, при котором кто-то обобщает класс или группа скажем, «все итальянцы» на основе на маленькой и бедной выборке; возможно, просто итальянцы, которые живут по соседству.
Примеры этого можно найти повсюду (обобщение) особенно когда мы что-то покупаем. Мы склонны делать обобщения относительно бренды.
Здесь, в дебрях Иллинойса, люди склонны обобщать много о брендах. У всех фермеров есть хотя бы один пикап основной пикап для привода и несколько второстепенных «запасных» пикапы, которые со временем служат газонными украшениями.
Каждый фермер предпочтет одну марку пикапа другой.
Некоторые фермеры — фермеры Форда, а другие — фермеры Шевроле. (А
растущее меньшинство составляют фермеры Dodge.) Каждый думает, что его
лучший.
(А
растущее меньшинство составляют фермеры Dodge.) Каждый думает, что его
лучший.
А причина их верности? «Ну,» Фермер Макдональд скажет: «Когда-то у меня был Форд, и это был хлам. Теперь я только ездить на Шевроле.»
Таким образом, весь опыт фермера Макдональда с грузовиками Форда этот единственный образец. Это хорошее основание, чтобы судить обо всех грузовиках Ford? При дальнейшем нажиме фермер Макдональд признается: его несчастный Форд действительно был хламом, 15-ти летним хламом, купленным б/у, и все фармером Последующие Chevies McDonald’s покупались новыми и продавались раньше.
Значит, его выборка грузовиков Ford может быть нерепрезентативной.
У фермера Брауна, живущего дальше по дороге, есть похожая история: «Я только
купить грузовики Форд. Когда-то у меня был Шевроле, и это был хлам».
Конечно, ветхий Chevy фермера Брауна знавал и лучшие времена. до того, как он в первый раз принес его домой.
до того, как он в первый раз принес его домой.
Может быть, грузовики Форда — барахло. Может быть, грузовики Chevy — это барахло. Но пока Фермер Макдональд и фермер Браун могут быть правы, называя свои собственные грузовики «мусор», им нужно увидеть гораздо больше грузовиков, прежде чем они могут точно сказать, что один бренд лучше другого. Их обобщение поспешно.
НЕКОТОРЫЕ СПОСОБЫ ДЕЛАТЬ ПОСЛЕДНИЕ ОБОБЩЕНИЯ:
1. Слишком маленькая выборка.
Поспешные обобщения обычно не принимают достаточно большого образец. Если наша выборка недостаточно велика, мы рискуем найти выборка, которая не является репрезентативной для класса, который мы изучаем.
Все мы знаем, что если подбросить монету, она упадет наполовину.
время орел, а половина времени решка. Однако это не
означает, что если мы подбросим его четыре раза, то дважды увидим орел и решку
дважды. Даже если мы подбросим его дюжину раз, мы можем не увидеть равного
количество орлов и решек. Чтобы на самом деле увидеть головы и
решки ровно, надо еще много-много раз подбрасывать
скажем, сто или тысячу или больше и даже тогда мы можем
быть от нескольких.
Даже если мы подбросим его дюжину раз, мы можем не увидеть равного
количество орлов и решек. Чтобы на самом деле увидеть головы и
решки ровно, надо еще много-много раз подбрасывать
скажем, сто или тысячу или больше и даже тогда мы можем
быть от нескольких.
Очевидно, фермеру Макдональду и фермеру Брауну не хватило образцы для их обобщения. Грузовики они купили просто может быть, это были швабры, выпускаемые со всех заводов, или изношенные подержанные автомобили.
2. Выборка не репрезентативна.
Обобщая, иногда выборка достаточно велика, но это не представитель всего класса. Делая обобщения, люди очень часто будут изучать только образцы под рукой, или легкие чтобы добраться до. Часто это не дает хорошей картины весь изучаемый класс, что позволит сделать результирующее обобщение однобокий.
Например: Если бы я хотел узнать о пищевых привычках итальянцев,
мне было бы очень легко изучать итальянцев, живущих в моем
город. Однако в мире много итальянцев: тех, кто живет
в Америке и придерживаются или не придерживаются своих региональных тарифов;
те, кто все еще живет в Италии; те, кто состоит или не состоит в мафии;
те, кто на диете….
Однако в мире много итальянцев: тех, кто живет
в Америке и придерживаются или не придерживаются своих региональных тарифов;
те, кто все еще живет в Италии; те, кто состоит или не состоит в мафии;
те, кто на диете….
Итальянцы в моем городе не могут есть то же, что и те, кто жить в другом месте. Мое исследование позволило сделать вывод, что большинство итальянцев есть спагетти, хотя на самом деле это делают только жители моего города. И возможно даже не все. Или, может быть, везде они едят пиццу и равиоли. Может быть, я изучал итальянцев только тогда, когда они ужинали и узнали, что тогда они ели спагетти но остальные время, когда они ели поп-тарталетки.
Грузовики фермера Макдональда и фермера Брауна также не были репрезентативными.
из «средних» грузовиков в своем роде. Есть много видов
грузовых автомобилей в разной степени износа. Их грузовики были старыми и
сломан. Им нужно было бы увидеть несколько примеров, которых не было.
Их грузовики были старыми и
сломан. Им нужно было бы увидеть несколько примеров, которых не было.
Викторина Время
Итак, теперь, когда вы знаете все об обобщениях, пришло время для как вы уже догадались викторины. Ответьте на это письмо с ваши ответы, напечатанные чуть ниже каждого вопроса.
Если вы правильно ответите на ВСЕ, то я вышлю вам бесплатно Кофейная кружка Logic Loop (двухмерная). Я предупрежу вас: подумайте хорошенько по каждому вопросу; они могут быть хитрыми.
В следующих примерах ответьте на следующие вопросы: 1. Является ли пример обобщение? 2. Если да, то насколько велика выборка, которая взятый? 3. По вашему мнению, это поспешные обобщения? И если Итак, почему?
ВОПРОС 1. Все сантехники молодцы. Я знаю сантехника, который может вычислить Пи до 289,954-я цифра.
ВОПРОС 2. Все сантехники богаты.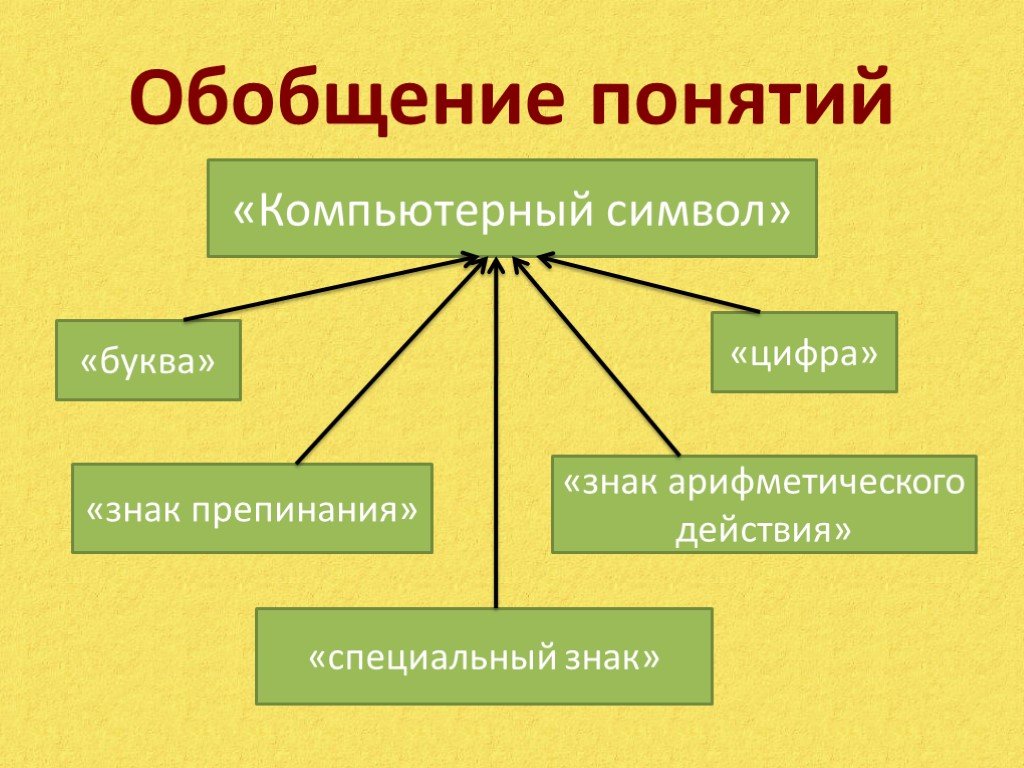 Я только что вышел на международный
съезд сантехников и изучил там 3000 сантехников. Все они
составлял более 100 000 долларов в год.
Я только что вышел на международный
съезд сантехников и изучил там 3000 сантехников. Все они
составлял более 100 000 долларов в год.
ВОПРОС 3. Моя мама хорошо учит людей. Всякий раз, когда она объясняет что-то мне, я это прекрасно понимаю.
ВОПРОС 4. Некоторые сантехники гениальны. Я сантехник, и я знаю, что я блестящий.
ВОПРОС 5. Все произведения Чарльза Диккенса скучны. я прочитал все его романы, и все они усыпляют меня.
ВОПРОС 6. Есть части Аляски, которые имеют большую высоту. Гора Мак-Кинли имеет высоту 20 320 футов.
ВОПРОС 7. Блохи есть у всех собак. Я только что закончил изучать каждый единственная собака во вселенной, и у всех у них были блохи.
ВОПРОС 8. В бочке 100 000 драже. После встряхивания
тщательно поднимайте ствол (следя за тем, чтобы ни один из них не раздавился),
вы извлекаете 5000 драже. 500 из них черные. Поэтому,
10% драже в бочке черные.
500 из них черные. Поэтому,
10% драже в бочке черные.
ВОПРОС 9. Коммерческие авиалинии очень безопасны. Сколько основных авиакатастрофы вы слышите каждый год? Может два или три. Сравните это с тем, сколько рейсов совершается каждый год. Или сравните количество авиакатастроф с количеством автокатастроф!
ВОПРОС 10. Предпосылка: В прошлом я надевал эту соломенную шляпу несколько раз неделю во время прополки огорода, и я начал чихать.
Предпосылка: Я носил эту соломенную шляпу, когда шел к костру, и Я начал чихать.
Предпосылка: Вчера я носил эту соломенную шляпу на улице и начал чихать.
Вывод: у меня аллергия на эту соломенную шляпу.
БОНУС (если вы ответите на этот бонусный вопрос, вы можете пропустить один из
другие вопросы и все равно получите кофейную кружку Logic Loop):
Пример поспешного обобщения найдите сами. Смотрящий
в газете или вечерних новостях может дать результаты. Смотреть
для мест, где люди делают широкие заявления и смотрят, чтобы увидеть
насколько хорошо они поддерживают их.
Смотрящий
в газете или вечерних новостях может дать результаты. Смотреть
для мест, где люди делают широкие заявления и смотрят, чтобы увидеть
насколько хорошо они поддерживают их.
Ханс Блудорн
ПОЛУЧЕННЫЕ ПИСЬМА
Дата: вторник, 20 ноября 2001 г., 21:04:31 -0800 (тихоокеанское время) 0003
Здравствуйте,
Вот это заблуждение, но я не знаю его названия. Это было на повторный показ «Розанны».
Некоторые женщины говорят об абортах:
«Некоторые говорят, что это убийство.»
«Некоторые говорят, что это не так.»
«Да, и некоторые говорят, что у тебя есть выбор.»
Я против абортов. Но несмотря на это, есть очень интересное заблуждение (или заблуждения), использованное здесь.
* Лицо, заявившее, что последняя линия установлена (в силу быть последним говорящим) быть Голосом Мудрости.
* Несмотря на то, что последнее утверждение претендует на то, чтобы быть «выше»
другие, т. е. более объективные, он просто повторяет один из
предыдущие мнения.
е. более объективные, он просто повторяет один из
предыдущие мнения.
Это одно заблуждение или несколько? Как это называется?
Большое спасибо,
Тед Шумейкер
ОТВЕТ:
Тед Шумейкер,
Абортологи уже давно пытаются нас заставить скажите «за выбор» вместо «за аборт». Это искусная техника манипулирования сознанием, которую иногда называют пропагандой. которые пытаются заставить нас думать о чем-то другом, кроме того, что они на самом деле верю. Про-какой выбор? Возможность выбрать свой вкус мороженого? Абортисты знают, что слово «аборт» ассоциируется со смертью, и поэтому они стараются использовать ее как можно меньше.
Ваша цитата — хороший пример пропагандистского сценария, устроено так, чтобы точка зрения писателей просвечивала без ты это знаешь.
Ханс Блудорн
Copyright 13 декабря 2001 г. , все права защищены. 74697 просмотров
, все права защищены. 74697 просмотров
Стереотипы/Обобщения — IDRInstitute
Стереотипы/Обобщения
Культурное обобщение – это утверждение о группе людей. Например, сказать, что американцы США склонны быть более индивидуалистичными по сравнению со многими другими культурными группами, является точным обобщением об этой группе. Культурное обобщение может стать стереотипом, если оно окончательно применяется к отдельным членам группы. Например, было бы стереотипом предполагать, что конкретный человек должен быть индивидуалистом в силу того, что он американец США.
Термин «стереотип» относится к металлическому шаблону, используемому для печати повторяющихся копий чего-либо. В контексте межкультурной коммуникации культурный стереотип представляет собой жесткое описание группы (все люди группы X такие) или, иначе говоря, это жесткое применение обобщения к каждому человеку в группе. (вы являетесь членом X, поэтому вы должны соответствовать общим качествам X). Стереотипов можно до некоторой степени избежать, используя культурные обобщения только как предварительные гипотезы о том, как может вести себя отдельный член группы.
Стереотипов можно до некоторой степени избежать, используя культурные обобщения только как предварительные гипотезы о том, как может вести себя отдельный член группы.
Мы не можем и не должны избегать культурных обобщений. Обобщения являются неотъемлемой частью человеческого восприятия. Каждый описываемый объект восприятия был отнесен к категории, которая связывает его с другими предположительно подобными объектами и противопоставляет его другим предположительно отличным объектам. Например, лошади могут быть отнесены к категории домашних рабочих животных, подобных быкам и верблюдам, но отличным от домашних животных, таких как кошки и попугаи. Лошади также могут (или в качестве альтернативы) относиться к категории пищевых животных (наряду с коровами и козами) в отличие от категории конкурирующих животных, таких как петухи и собаки. Но не может быть лошади или любого другого объекта восприятия без определенного набора ассоциаций.
Идея «культуры» сама по себе является категоризацией людей. На самом деле невозможно вообще сослаться на группу, не делая обобщения о том, какие качества разделяют члены группы. Но, как и лошадей, людей можно отнести к разным культурным категориям в зависимости от того, какие критерии используются для сравнения их с другими группами. Кроме того, отдельные члены различаются по степени, в которой они разделяют общие характеристики группы. Отрицать эту изменчивость — предполагать, что каждый человек является статичным представителем одной группы — суть стереотипизации.
На самом деле невозможно вообще сослаться на группу, не делая обобщения о том, какие качества разделяют члены группы. Но, как и лошадей, людей можно отнести к разным культурным категориям в зависимости от того, какие критерии используются для сравнения их с другими группами. Кроме того, отдельные члены различаются по степени, в которой они разделяют общие характеристики группы. Отрицать эту изменчивость — предполагать, что каждый человек является статичным представителем одной группы — суть стереотипизации.
Можно делать точные обобщения о преобладающих качествах группы, не создавая стереотипов об отдельных членах группы. Точные обобщения основаны на измерении выбранного набора культурных критериев (например, «стили» или «ценности») на большом количестве или случайной выборке людей. Этот процесс либо создает группы на основе схожих шаблонов критериев, либо описывает шаблоны, существующие внутри группы, на основе других критериев, таких как национальные границы. Если обобщение опирается на слишком маленькую выборку, оно может описывать какое-то необычное качество, которое не представлено широко в группе в целом. Вот почему не стоит обобщать знакомство с несколькими членами существующей группы; они, вероятно, не являются представителями группы. Основание обобщения исключительно на личном опыте, вероятно, будет неточным, но неточность не является основой стереотипов. Когда обобщения — точные или неточные — жестко применяются к отдельным людям, они становятся стереотипами.
Вот почему не стоит обобщать знакомство с несколькими членами существующей группы; они, вероятно, не являются представителями группы. Основание обобщения исключительно на личном опыте, вероятно, будет неточным, но неточность не является основой стереотипов. Когда обобщения — точные или неточные — жестко применяются к отдельным людям, они становятся стереотипами.
Уровень анализа для обобщений
Для того чтобы сделать культурные обобщения, полезные для анализа взаимодействия, важно определить, какой уровень анализа мы используем при наблюдении за человеческим поведением. Культура в том смысле, в каком она используется в межкультурной работе, относится к групповому уровню анализа, где речь идет о преобладании определенных качеств, таких как ценности или стили, в определенных группах, таких как национальные общества, этнические группы, геополитические регионы, и т. д. (см. раздел о межкультурной коммуникации) К
отличие, индивидуальный уровень анализа относится к индивидуальным характеристикам и личности.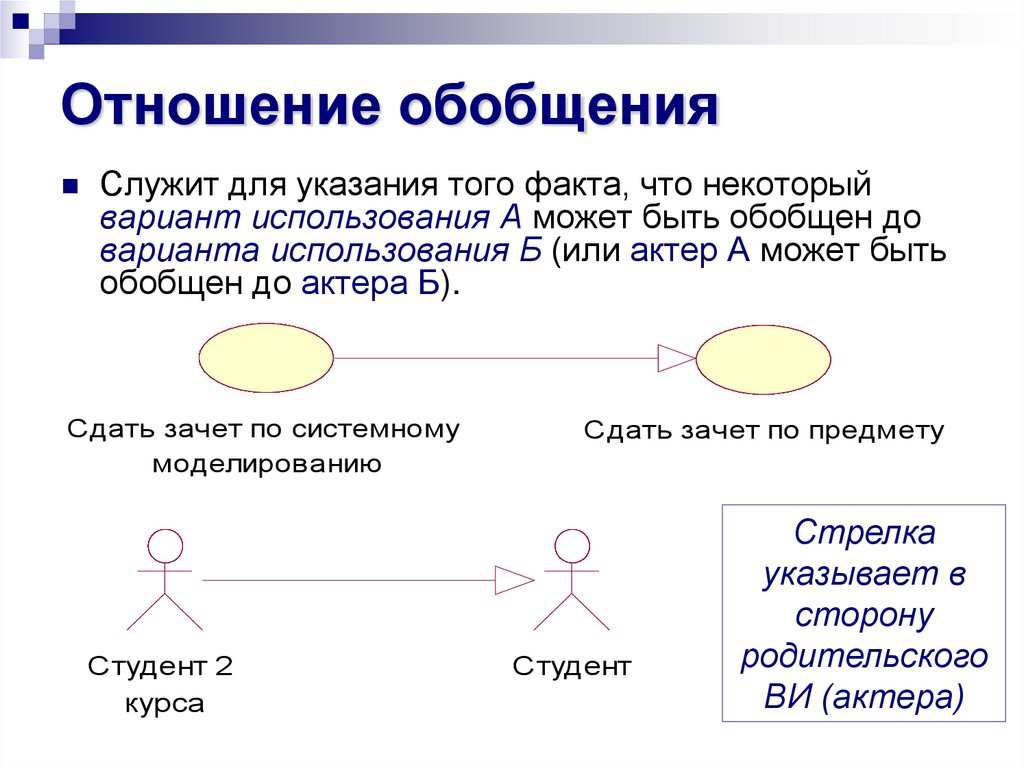 Обычно предполагается, что генетически обусловленные черты личности и личностные характеристики, такие как интеллект, более или менее одинаково распределяются в различных культурных контекстах. Следуя этому предположению, мы не можем сказать, что в одной культуре такая черта личности, как экстраверсия, больше, чем в другой, и точно так же мы определенно не можем сказать, что одна культурная группа менее интеллектуальна, чем другая. Другими словами, мы не можем делать культурные обобщения относительно индивидуальных характеристик; сделать это представляет собой «путаницу уровня анализа».
Обычно предполагается, что генетически обусловленные черты личности и личностные характеристики, такие как интеллект, более или менее одинаково распределяются в различных культурных контекстах. Следуя этому предположению, мы не можем сказать, что в одной культуре такая черта личности, как экстраверсия, больше, чем в другой, и точно так же мы определенно не можем сказать, что одна культурная группа менее интеллектуальна, чем другая. Другими словами, мы не можем делать культурные обобщения относительно индивидуальных характеристик; сделать это представляет собой «путаницу уровня анализа».
В межкультурной работе важно не путать эти два уровня анализа. Если, например,
мы пытаемся проанализировать конфликт между двумя людьми, индивидуальный уровень анализа приведет нас к рассмотрению различий в личности (например, экстраверсия/интроверсия), интеллекте, стиле обучения, стиле руководства и других характеристиках, которые рассматриваются как индивидуальные вариации. Однако мы могли бы также анализировать конфликт на групповом уровне анализа, ища различия в культурном мировоззрении, таком как стиль общения, невербальное выражение или культурные ценности (например, индивидуализм/коллективизм). Вполне может быть, что конфликт можно адекватно объяснить ссылкой только на личностные различия — «столкновение личностей». Но во многих ситуациях, особенно кросс-культурных, конфликты мировоззрений могут быть столь же или более важными для объяснения конфликта. Поскольку большая часть популярных и даже академических представлений о коммуникации излагается в психологических терминах (на индивидуальном уровне анализа), требуются сознательные усилия, чтобы сохранять фокус на проблемах мировоззрения на групповом уровне анализа.
Вполне может быть, что конфликт можно адекватно объяснить ссылкой только на личностные различия — «столкновение личностей». Но во многих ситуациях, особенно кросс-культурных, конфликты мировоззрений могут быть столь же или более важными для объяснения конфликта. Поскольку большая часть популярных и даже академических представлений о коммуникации излагается в психологических терминах (на индивидуальном уровне анализа), требуются сознательные усилия, чтобы сохранять фокус на проблемах мировоззрения на групповом уровне анализа.
На институциональном уровне анализа основное внимание уделяется человеческому поведению с точки зрения институтов, таких как политические, экономические или религиозные системы. События можно анализировать на этом уровне, понимая, как институты направляют человеческое поведение в определенные модели взаимодействия. Например, к конфликту, упомянутому ранее, можно было бы с пользой подойти, проанализировав статус и властные отношения участников или поняв их возможную различную привязанность к конкурирующим организациям. Некоторые формы культурных исследований сочетают институциональный и индивидуальный уровни анализа, стремясь определить положение людей в социальных организациях с точки зрения власти, привилегий и угнетения. Затем широкий спектр поведения (например, доминирующие/недоминирующие групповые отношения) объясняется с точки зрения ролей (и, следовательно, относительной власти), которые люди имеют в обществе.
Некоторые формы культурных исследований сочетают институциональный и индивидуальный уровни анализа, стремясь определить положение людей в социальных организациях с точки зрения власти, привилегий и угнетения. Затем широкий спектр поведения (например, доминирующие/недоминирующие групповые отношения) объясняется с точки зрения ролей (и, следовательно, относительной власти), которые люди имеют в обществе.
Не отрицая важности властных отношений, институциональный уровень анализа тем не менее может быть концептуально опасной основой для культурных обобщений. Такие институты, как политические и экономические структуры, архитектура, литература и т. д., являются артефактами культуры; то есть они являются продуктами групп людей, которые координируют между собой смысл и действия. Однажды созданные институты становятся «объективными» в том смысле, что они существуют как относительно стабильные объекты в нашей среде. Когда мы определяем поведение в терминах объективных институтов, само поведение объективируется, а ролевые отношения между людьми в институциональных терминах статичны. Объясняя человеческое взаимодействие исключительно в институциональных терминах, мы рискуем сказать, что, кем бы мы ни были лично и кем бы мы ни были в культурном отношении, наше поведение существенно определяется нашим положением в обществе. Это высший стереотип, использующий социальную роль в качестве эссенциального ярлыка.
Объясняя человеческое взаимодействие исключительно в институциональных терминах, мы рискуем сказать, что, кем бы мы ни были лично и кем бы мы ни были в культурном отношении, наше поведение существенно определяется нашим положением в обществе. Это высший стереотип, использующий социальную роль в качестве эссенциального ярлыка.
Ключом к использованию культурных обобщений без стереотипизации является использование их на групповом уровне анализа, стремление понять индивидуальное поведение как в некоторой степени проявление культурного мировоззрения, а взаимодействие между людьми как в некоторой степени столкновение и согласование этих мировоззрений. Мы также можем анализировать личностные и властные измерения взаимодействия, но путать эти уровни анализа с культурным уровнем значит рисковать, что культурные обобщения будут подавляться индивидуальными или социальными стереотипами.
Область действия Условия для обобщения культуры
Уровень специфичности культурного обобщения зависит от области действия обобщаемой группы.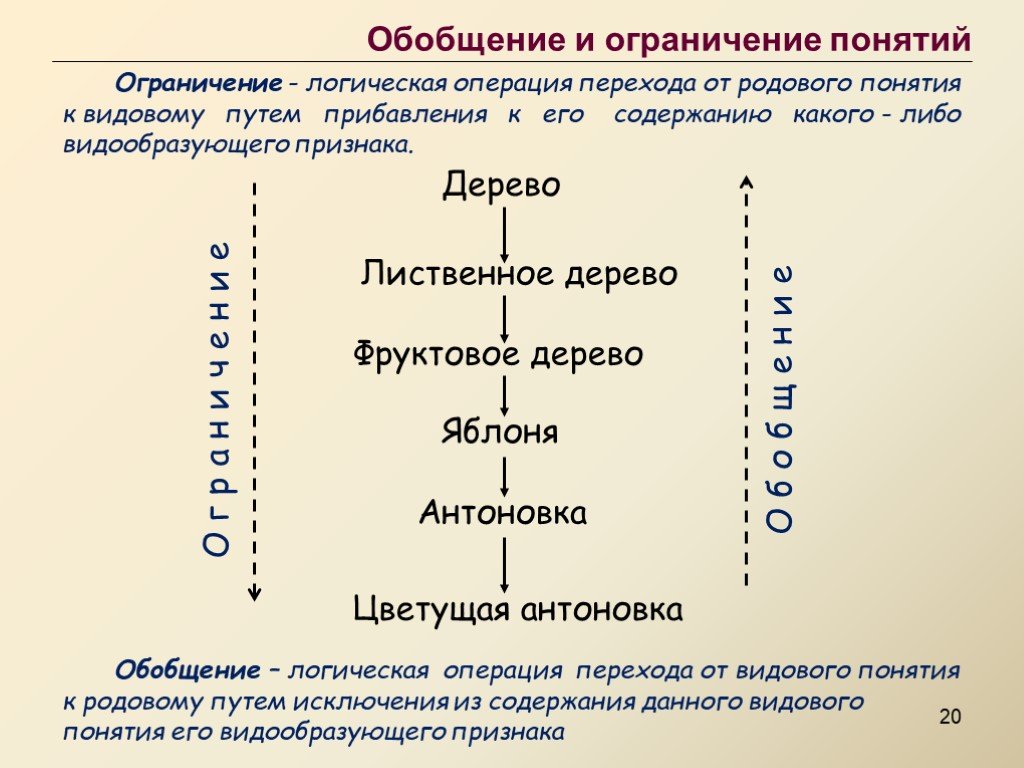 Используя определение культуры как «согласование смысла и действия между людьми, взаимодействующими в пределах границы», рамки культурной группы определяются ее границей. Типичная граница следует за национальной границей, поэтому мы можем говорить об «итальянской» культуре или «американской культуре». Американская культура. Однако охват большинства национальных групп уже достаточно широк, и поэтому точные обобщения, которые можно сделать, также относительно широки (абстрактны). Например, можно сделать точный вывод, что итальянцы более ориентированы на отношения, чем американцы, которые больше ориентированы на задачи, хотя это верное утверждение включает в себя огромные различия в обеих группах. Если мы хотим сделать более конкретное обобщение, такое как «люди культуры X, как правило, более гостеприимны, чем люди культуры Y», то нам нужно обратиться к более конкретной группе. Например, южные итальянцы, как правило, более гостеприимны, чем северные итальянцы, а афроамериканцы более гостеприимны, чем американцы европейского происхождения.
Используя определение культуры как «согласование смысла и действия между людьми, взаимодействующими в пределах границы», рамки культурной группы определяются ее границей. Типичная граница следует за национальной границей, поэтому мы можем говорить об «итальянской» культуре или «американской культуре». Американская культура. Однако охват большинства национальных групп уже достаточно широк, и поэтому точные обобщения, которые можно сделать, также относительно широки (абстрактны). Например, можно сделать точный вывод, что итальянцы более ориентированы на отношения, чем американцы, которые больше ориентированы на задачи, хотя это верное утверждение включает в себя огромные различия в обеих группах. Если мы хотим сделать более конкретное обобщение, такое как «люди культуры X, как правило, более гостеприимны, чем люди культуры Y», то нам нужно обратиться к более конкретной группе. Например, южные итальянцы, как правило, более гостеприимны, чем северные итальянцы, а афроамериканцы более гостеприимны, чем американцы европейского происхождения.
В крайних случаях обобщения становятся очень расплывчатыми или очень резкими. В чрезвычайно широком масштабе мы могли бы сравнивать «Запад» с «Востоком», но мы можем делать лишь довольно расплывчатые обобщения относительно этого контраста. Например, можно сделать вывод, что азиаты более чувствительны к контексту, чем европейцы или американцы. Но вариация в обеих группах настолько велика, что такое утверждение не очень полезно для конкретных случаев общения. В очень узком масштабе мы могли бы сравнить культуру одного отдела компании с культурой другого; например, отделы могут различаться в своих предпочтениях по электронной почте или по телефону. Но вне взаимодействия между этими конкретными группами такое узкое обобщение не очень полезно. Самые полезные обобщения — это те, которые расположены на среднем уровне абстракции, не настолько широкие, чтобы быть лишь смутно верными, и не настолько узкие, чтобы быть только тривиально верными. Хорошие культурные обобщения среднего уровня порождают культурные контрасты, которые имеют отношение к межкультурной коммуникации и переносятся на различные другие культурные контрасты.
Например, мы можем точно обобщить, что жители Северной Америки используют более линейный (низкоконтекстный) стиль общения, чем жители Южной Америки, которые используют более круговой (высококонтекстный) стиль. Этот контраст имеет непосредственное отношение к межкультурной коммуникации, поскольку он может предсказать возможную взаимную негативную оценку: североамериканец может найти южноамериканца рассеянным и тратящим время, в то время как южноамериканец может найти североамериканца упрощенным и высокомерным. Простого акта внесения этой разницы в стиле общения в восприятие может быть достаточно, чтобы смягчить негативную оценку и, возможно, предоставить некоторые основания для взаимной адаптации. Это обобщение среднего уровня касается двух довольно широких региональных культур, но оно разумно применимо к национальным и этническим вариациям внутри регионов. И, что наиболее важно, это обобщение можно перенести на другие культурные контрасты, такие как более прямолинейные голландцы и более круглые итальянцы, или более линейные американцы европейского происхождения и более круглые афроамериканцы.
Общие рамки культуры
Общие рамки культуры создаются с целью создания полезных культурных обобщений. В отличие от информации, относящейся к конкретной культуре, общекультурные рамки не претендуют на исчерпывающее описание культур, как это могла бы сделать антропологическая этнография. Вместо этого фрейм создается для того, чтобы направлять восприятие к различиям и контрастам, полезным для взаимодействия и достаточно общим для применения в широком диапазоне культурных контекстов. (См. раздел «Конструктивизм» для обсуждения того, как и почему создаются эти фреймы). Фрейм определяет домен и континуум: домен определяет фокус, такой как невербальное поведение, а континуум представляет собой вариацию определенного поведения в домене, например зрительный контакт. Затем делаются обобщения о том, как поведение распределяется среди населения разных культурных групп. Ниже приведены некоторые примеры того, как можно использовать общекультурные фреймы для создания полезных обобщений о культурных различиях, не создавая при этом стереотипов.
Использование языка. Областью здесь являются не языковые системы, а способ использования языка в ритуальных способах координации социальных отношений. Континуа обычно включает приветствие, прощание и другие ритуалы, такие как споры, переговоры, комплименты или критика. Например, ритуалов устного приветствия можно противопоставить по продолжительности (от короткого к длинному), общему содержанию (от безличного к личному) и стилю (от шутливого к серьезному). Чтобы противопоставить культуру европейско-американских мужчин культуре европейско-американских женщин: мужчины E-A склонны озвучивать короткие приветствия мимоходом, подчеркивая безличный общий опыт, такой как просмотр спортивных передач, а иногда и дразня. Женщины E-A более склонны к более длительным приветствиям, подчеркивая личный опыт отношений и, возможно, включая комплименты внешнему виду друг друга.
Потенциальное недопонимание, возникающее из-за вышеупомянутого контраста в ритуале приветствия, может выглядеть следующим образом: женщина может воспринимать мужчину как резкого и недружелюбного, а может быть, даже враждебного в его использовании «приманки». Мужчина, напротив, может воспринять неожиданные откровения и комплименты от женщины как необычайно интимные и даже кокетливые. Эти представления, вероятно, будут неточными, потому что они вытекают из неправильного уровня анализа. Поскольку ритуалы приветствия не были идентифицированы как культурные образцы, их ошибочно принимают за признаки личных качеств. Действия, предпринятые на основе этих заблуждений, вероятно, усугубят ситуацию. Например, мужчина может чувствовать себя вправе флиртовать с женщиной в ответ. В контексте своего восприятия мужчины женщина может найти его сексуальное внимание особенно неприятным или даже пугающим.
Мужчина, напротив, может воспринять неожиданные откровения и комплименты от женщины как необычайно интимные и даже кокетливые. Эти представления, вероятно, будут неточными, потому что они вытекают из неправильного уровня анализа. Поскольку ритуалы приветствия не были идентифицированы как культурные образцы, их ошибочно принимают за признаки личных качеств. Действия, предпринятые на основе этих заблуждений, вероятно, усугубят ситуацию. Например, мужчина может чувствовать себя вправе флиртовать с женщиной в ответ. В контексте своего восприятия мужчины женщина может найти его сексуальное внимание особенно неприятным или даже пугающим.
Невербальное поведение. Невербальное поведение не поддается культурному объяснению даже в большей степени, чем ритуальное использование языка. Это можно проиллюстрировать с помощью рамки зрительного контакта, которая включает континуумы для 90 165 длины зрительного контакта 90 166 (от короткого к длинному) и для использования глаз в 90 165 разговорном обороте, принимающем 90 166 (от сильного к слабому). В культурном контрасте между американцами США и людьми из некоторых стран Северной Европы, таких как Голландия или Германия, американцы, как правило, устанавливают зрительный контакт средней продолжительности, прежде чем отвести взгляд, и они используют более длинный прямой взгляд в качестве сигнала для смены говорящего. Немцы и голландцы, как правило, устанавливают более продолжительный и прямой зрительный контакт, а переход в очередь чаще всего начинается с отвода взгляда.
В культурном контрасте между американцами США и людьми из некоторых стран Северной Европы, таких как Голландия или Германия, американцы, как правило, устанавливают зрительный контакт средней продолжительности, прежде чем отвести взгляд, и они используют более длинный прямой взгляд в качестве сигнала для смены говорящего. Немцы и голландцы, как правило, устанавливают более продолжительный и прямой зрительный контакт, а переход в очередь чаще всего начинается с отвода взгляда.
Из-за этой разницы в невербальном поведении может возникнуть несколько возможных недоразумений. Многие американцы интерпретируют сильный зрительный контакт как признак сексуальной или физической агрессии, в зависимости от ситуации. Немцы, с другой стороны, склонны интерпретировать более слабый зрительный контакт как признак отсутствия интереса или внимания. Эти неверные толкования, вероятно, будут усугубляться тем, что немцы усиливают зрительный контакт, пытаясь привлечь внимание, в то время как американцы могут ослабить зрительный контакт , чтобы уменьшить воспринимаемую угрозу. Все может стать еще хуже, поскольку бегающие американские глаза посылают немцам бессознательные сигналы о том, что всегда их очередь говорить, в то время как пристальный взгляд немцев посылает то же самое сообщение американцам. Следовательно, оба участника межкультурного взаимодействия могут уйти убежденными, что другой пытается доминировать в разговоре.
Все может стать еще хуже, поскольку бегающие американские глаза посылают немцам бессознательные сигналы о том, что всегда их очередь говорить, в то время как пристальный взгляд немцев посылает то же самое сообщение американцам. Следовательно, оба участника межкультурного взаимодействия могут уйти убежденными, что другой пытается доминировать в разговоре.
Стиль общения. Существует несколько форм этого фрейма, многие из которых основаны на различии Эдварда Т. Холла между стилями с высоким контекстом и с низким контекстом . Высококонтекстная сторона континуума – это то место, где большое значение выводится из окружающей ситуации, а не из того, что говорится явно. Популяции, которые в основном распределены на высококонтекстной стороне, могут иметь различные модели использования языка (например, они могут быть очень разговорчивыми или в основном молчаливыми), но они разделяют зависимость от «чтения между строк», чтобы передать реальный смысл. Напротив, люди с низким уровнем контекста больше полагаются на явные утверждения для передачи смысла. Такие люди также могут быть либо разговорчивыми, либо относительно молчаливыми, но обычно они обращают внимание на то, что на самом деле сказано, на предмет истинного смысла. В этом континууме люди с европейскими корнями, как правило, имеют низкий контекст по сравнению с высококонтекстным стилем, используемым многими людьми африканских, латиноамериканских и азиатских корней.
Напротив, люди с низким уровнем контекста больше полагаются на явные утверждения для передачи смысла. Такие люди также могут быть либо разговорчивыми, либо относительно молчаливыми, но обычно они обращают внимание на то, что на самом деле сказано, на предмет истинного смысла. В этом континууме люди с европейскими корнями, как правило, имеют низкий контекст по сравнению с высококонтекстным стилем, используемым многими людьми африканских, латиноамериканских и азиатских корней.
Непонимание в континууме высокого/низкого контекста довольно распространено. Американцы европейского происхождения могут ждать, пока азиаты явно попросят что-то, прежде чем они предложат это, оставляя азиатов удивляться (молча) американской бесчувственности и тупости. С другой стороны, некоторые выходцы из Азии могут создать путаницу в отношениях, придавая непреднамеренный смысл поведению американцев европейского происхождения. Столкнувшись с путаницей, американцы европейского происхождения, вероятно, станут более прямыми и откровенными, что может привести к тому, что люди, использующие стиль более высокого контекста, станут более косвенными и осмотрительными, создавая тем самым спираль все более некомпетентных обменов мнениями.
Когнитивный стиль. Эта область этого фрейма — модели мышления, или то, как люди обрабатывают восприятие. Базовый континуум простирается от 90 165 конкретных 90 166, где люди используют больше описаний и физических метафор для фиксации своего восприятия, до 90 165 абстрактных, 90 166, где люди с большей вероятностью используют теорию и объяснение для организации восприятия. В этом континууме люди во многих азиатских культурах склонны быть конкретными, подчеркивая точное описание и непосредственный опыт событий. Напротив, люди многих североевропейских культур склонны к абстракции, подчеркивая последовательное объяснение и исторический контекст событий. Американцы США, как правило, придерживаются среднего уровня в этом континууме, делая упор на ориентированные на действия процедуры, которые не являются ни особенно точными, ни особенно последовательными.
Учитывая их положение в континууме, американцы, как правило, нетерпеливы как к теории , так и к отношениям, предпочитая сосредоточиться на задачах. В США американцы европейского происхождения более терпимы к абстракции по сравнению с американцами африканского или азиатского происхождения, которые с большей вероятностью уделяют внимание реляционным аспектам выполнения задач.
В США американцы европейского происхождения более терпимы к абстракции по сравнению с американцами африканского или азиатского происхождения, которые с большей вероятностью уделяют внимание реляционным аспектам выполнения задач.
Культурные ценности . Это один из самых известных межкультурных фреймов. Его областью является то, как люди приписывают добро способам существования в мире. Например, многие жители Запада считают, что людям полезно действовать как личности, делая акцент на уверенности в себе, независимом принятии решений и личных достижениях. Многие азиаты придают большее значение семье или другой группе, подчеркивая ответственность перед другими, контекстуальное принятие решений и коллективные достижения. В дополнение к этому континууму из индивидуализм/коллективизм , другие типичные ценностные континуумы включают ориентацию во времени (извлечение уроков из прошлого для планирования будущего), деятельность (позволять вещам происходить, чтобы делать их возможными), социальные роли (подчеркивание разницы в статусе для подчеркивания равенство ролей) и терпимость к неоднозначности (от низкого уровня избегания неопределенности до высокого избегания неопределенности).
Обычное столкновение ценностей между американцами США и представителями многих других культур происходит в ценностном континууме социальных ролей. Американцам, как правило, не нравится открытое признание различий в роли и статусе, хотя такие различия, очевидно, существуют. Многие азиаты, африканцы, южноамериканцы и европейцы (то есть все остальные за пределами Северной Америки, в том числе лица неевропейского происхождения с США) чувствуют себя более комфортно, признавая различия в статусе, на что указывает их более частое использование титулы.
См. также
Межкультурная коммуникация, конструктивизм, антирасистское образование, класс (социоэкономический), колоризм, угроза стереотипов, расизм
Дополнительная литература
издание) Основные понятия межкультурного Коммуникация: парадигмы, принципы, и практика . Бостон: Межкультурная пресса, 2013
Гудыкунст, В. и Тинг-Туми, С. Культура и межличностное общение.