Рассказ о семье на английском языке с переводом на русский
Семья — это ячейка общества, призванная поддерживать родственные связи и быть в мире и согласии. Написать рассказ о семье на английском языке часто задают в школах учащимся, поэтому пример рассказа о семье с переводом всегда актуален.
Словарик на тему семья
Прежде всего, семья в переводе на английский язык, звучит как family.
- to introduce — представляться.
- let me introduce myself — разрешите представиться
- elder brother — старший брат
- younger sister — младшая сестра
- a plant — фабрика, завод
- to become — стать
- an engineer — инженер
- a driver — водитель
- go shopping — ходить за покупками
Ниже приводится рассказ на английском языке — About family.
Рассказ на английском языке про семью
About family
I have a big family. First of all let me introduce myself. My name is Regina. I’m twelve years old. I’m at 6-th grade.
First of all let me introduce myself. My name is Regina. I’m twelve years old. I’m at 6-th grade.
There are three kids in our family include me. My elder brother name is Ildar, my younger sister Svetlana. Ildar is twenty-five. He is an engineer in a plant. He graduate University in 21 years. Svetlana is 10 years. She is in 4-th grade. She want to become a doctor. Also we have a pet. It is cat. His name is Timon. It is my favourite cat.
My parents are not so old. My father is fifty-one, he is a driver. My Mum is fifty, she works in a library.
Also I have grandmother an grandfather. They are both teachers. My grandparents are already retired. They like gardening and spend all their time growing potatoes, tomatoes and so on.
Every week we go to the swimming pool.
I like to play with my cat. Sometimes I play in different games with my sister Svetlana. Ildar helps me to do home work.
Every week we also go shopping and buy fruits, tasty food and, of course, а toy for me.
I love my family!
Рассказ на английском языке about family
О семье
У меня большая семья. Прежде всего, позвольте мне представиться самой. Меня зовут Регина. Мне 12 лет. Я учусь в 6-ом классе.
В моей семье трое детей, включая меня. Моего старшего брата зовут Ильдар, мою младшую сестру зовут Светлана. Ильдару 25 лет. Он инженер на заводе. Он закончил университет в 21 год. Светлане 10 лет. Она в 4-ом классе. Она хочет стать доктором. Также у нас есть домашнее животное. Это кот. Его зовут Тимон. Это мой любимый кот.
Мои родители не так стары. Моему папе 51 год, он шофер. Моей маме 50, она работает в библиотеке.
Также у меня есть бабушка и дедушка. Они оба учителя. Они уже на пенсии. Они любят садоводство и проводят все свое время, выращивая картошку, помидоры и другие овощи.
Каждую неделю мы ходим в бассейн.
Я люблю играть с моим котом. Иногда я играю в разные игры с моей сестрой Светланой. Ильдар помогает мне делать домашнуюю работу.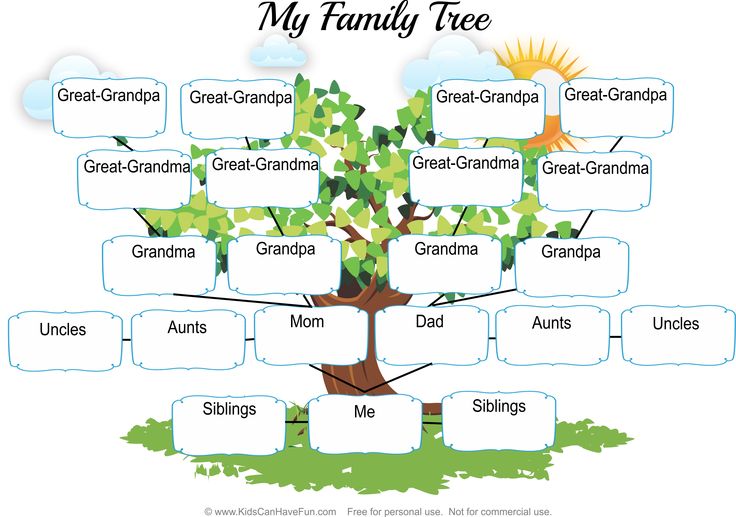
Каждую неделю мы также ходим за покупками и покупаем фрукты, вкусную еду и, конечно же, игрушку для меня.
Я люблю свою семью!
Рассказ на английском языке про семью
MY FAMILY OR ABOUT MY FAMILY
My name is Alexander. Well, I am 13 and live in a happy family made up of my mum, dad and my younger brother, Oleg, who is eight. My Dad Vladimir is an electrician and works at a plant. He fixes electric motors for factories. The job is ok I think but my dad always tells me to study better, so, I can get a different occupation when I am bigger. My mum, Natalie, works in a supermarket which is a useful job because she gets discounts on food and brings home tasty sweets and chocolate, occasionally new computer games which Oleg and I have never played before.
Oleg, my brother, is quite fun to have around. He is very smart and likes drawing much which is good but lately he has been a bit of a pain wanting to play my games on dad’s laptop. This leads to arguments sometimes and mum keeps telling me to share more with Oleg. I like going to meet my friends in the park after school. We practice with our skateboards doing tricks. However, every day I must pick up my brother and take care of him which means I have to bring him with me to the park. This is fine but he wants to do the same tricks as me and my friends but he is too small and sometimes scrapes his knee or hurts himself and mum, of course, punishes me when this happens and says that I should not let Oleg do it. But I’m proud that he does. No other eight years old in the neighbourhood can match him I’m certain!
I like going to meet my friends in the park after school. We practice with our skateboards doing tricks. However, every day I must pick up my brother and take care of him which means I have to bring him with me to the park. This is fine but he wants to do the same tricks as me and my friends but he is too small and sometimes scrapes his knee or hurts himself and mum, of course, punishes me when this happens and says that I should not let Oleg do it. But I’m proud that he does. No other eight years old in the neighbourhood can match him I’m certain!
I enjoy visiting my grandparents in the village. They are interesting and always tell me exciting stories. Best of all I like when we take our tent to the forest nearby and camp there. Dad makes a barbecue of meat and fish and mum brings pots of food from grandma. We play football and other games during a daytime. At night dad plays the guitar and we sing songs around our camp fire. Mum, dad and I and Oleg. I like my family; life is great!
Рассказ на английском языке my family
Моя семья или про мою семью
Меня зовут Александр. Мне 13 лет, и я живу в счастливой семье, которая состоит из моей мамы, папы и моего младшего брата Олега, которому восемь лет. Мой папа Владимир – электрик, и работает на заводе. Он устанавливает электродвигатели для фабрик. Работа не плохая, я думаю, но мой папа всегда напоминает мне учиться лучше, чтобы я смог получить другую работу, когда вырасту. Моя мама Наталия, работает в супермаркете, это полезная работа, потому что она получает скидки на продукты и приносит домой вкусные конфеты и шоколад, иногда новые компьютерные игры, в которые, Олег и я никогда не играли прежде.
Мне 13 лет, и я живу в счастливой семье, которая состоит из моей мамы, папы и моего младшего брата Олега, которому восемь лет. Мой папа Владимир – электрик, и работает на заводе. Он устанавливает электродвигатели для фабрик. Работа не плохая, я думаю, но мой папа всегда напоминает мне учиться лучше, чтобы я смог получить другую работу, когда вырасту. Моя мама Наталия, работает в супермаркете, это полезная работа, потому что она получает скидки на продукты и приносит домой вкусные конфеты и шоколад, иногда новые компьютерные игры, в которые, Олег и я никогда не играли прежде.
Олег, мой брат, довольно забавен. Он очень умен и сильно любит рисовать, это хорошо, но в последнее время он был чем-то вроде проблемы, желающей играть в мои игры на ноутбуке папы. Это иногда приводит к ссорам, и мама постоянно твердит мне, что бы ябольше делился с Олегом. Мне нравится встречаться с моими друзьями в парке после школы. Мы практикуемся с нашими скейтбордами, делая трюки. Однако, каждый день я должен забирать своего брата и заботиться о нем, означает, что я должентакже вести его со мной в парк. Это здорово, но он хочет делать те же самые трюки, как я и мои друзья, но он слишком маленький и иногда сбивает колено или причиняет себе боль, и мама, конечно, наказывает меня, когда это происходит, и она говорит, что я не должен позволять Олегу этого. Но я горд тем, что он делает. Никакой другой восьмилетний в районе не может соответствовать ему, я уверен!
Это здорово, но он хочет делать те же самые трюки, как я и мои друзья, но он слишком маленький и иногда сбивает колено или причиняет себе боль, и мама, конечно, наказывает меня, когда это происходит, и она говорит, что я не должен позволять Олегу этого. Но я горд тем, что он делает. Никакой другой восьмилетний в районе не может соответствовать ему, я уверен!
Я люблю навещать бабушку и дедушку в деревне. Они интересные люди и всегда рассказывают мне захватывающие истории. Больше всего мне нравится, когда мы берем нашу палатку и идем к лесу поблизости и разбиваем лагерь. Папа делает барбекю из мяса и рыбы, а мама приносит еду от бабушки в кастрюльках. Мы играем в футбол и другие игры в дневное время. Ночью папа играет на гитаре, а мы поем песни вокруг костра. Мама, папа, и я, и Олег. Мне нравится моя семья; жизнь — замечательна!
Как превратить текст в генеалогическое древо с помощью Python
Сложные обороты типа брат матери моего дяди по-научному называются посессивные конструкции с терминами родства. Название происходит от латинского possessio – владение, обладание, отсюда же произошел английский глагол to possess — иметь, обладать.
Название происходит от латинского possessio – владение, обладание, отсюда же произошел английский глагол to possess — иметь, обладать.
В русском языке обладание чем-либо (та самая посессивность, она же притяжательность) обычно передается родительным падежом: деньги Маши, дом Васи, мама Саши. Поэтому в конструкциях с описанием родственных связей все термины родства, кроме самого первого, стоят в родительном падеже: отца, матери, сестры. Первое слово является вершиной конструкции, поэтому может стоять в любом падеже в зависимости от роли в предложении (ср. пришел брат матери моего дяди — она пришла с братом матери моего дяди).
Еще конструкция может содержать притяжательное местоимение (моего, ее, вашей). Ниже приведено несколько примеров таких конструкций:
- сваха племянника вашей сестры
- сестра мужа моей тёщи
- брат зятя их отца
Посессивные конструкции с терминами родства сложны для восприятия — читателю трудно быстро вычислить родственные связи между упомянутыми в них людьми.
Было бы удобно автоматически анализировать такие конструкции и представлять их в удобном для восприятия виде — например, в виде генеалогических деревьев. Мы решили эту задачу на Python и сейчас расскажем, как.
Мы выделили три этапа обработки конструкций: выделение конструкций во входном фрагменте текста, построение графа родственных связей и визуализация полученного графа в виде генеалогического дерева. Рассмотрим каждый этап более подробно.
Выделение последовательностей
- С нами жила сестра моей бабушки.


Однако, так происходит не всегда. Между терминами родства могут стоять синтаксические определения (прилагательные, причастия, порядковые числительные, притяжательные местоимения и др.), причем иногда они сами могут иметь значение родства.
- С нами жила сестра моей покойной бабушки.
- С нами жила бабушкина сестра.
Кроме того, последним в конструкции может стоять не термин родства, а существительное, напротив, без значения родства.
- С нами жила сестра бабушки моей подруги.
Все эти случаи тоже хотелось бы учитывать, поэтому сначала мы выделим из текста последовательности слов, содержащие интересующие нас конструкции, а затем «вычеркнем» из них лишние слова.
Сформулируем более формально, что может содержать последовательность:
- термины родства (в любом падеже, если это слово первое в последовательности, и в родительном падеже далее)
- синтаксические определения
- одно существительное, не являющееся термином родства, в родительном падеже (это слово будет последним в последовательности)
Эти правила выделения последовательностей отражены в функции search_sentence. Она принимает строку, содержащую предложение на русском языке, и возвращает список найденных последовательностей.
Она принимает строку, содержащую предложение на русском языке, и возвращает список найденных последовательностей.
from nltk.tokenize import word_tokenize
def search_sentence(sent):
# разбиваем предложение на слова функцией word_tokenize из библиотеки NLTK
sent = word_tokenize(sent, language='russian')
sent = [word.lower() for word in sent]
results = []
prev_kin, prev_def = False, False
i = 0
while i < len(sent):
word = sent[i]
# найдено первое слово в нов. последовательности
if not prev_kin and not prev_def and is_kinship_term(word):
start = i
prev_kin = True
# берем все определения перед ним
while start > 0 and is_definition(sent[start - 1]):
start -= 1
i += 1
# мы внутри конструкции
elif prev_kin or prev_def:
# текущ. слово - определение
if is_definition(word):
prev_def = True
prev_kin = False
i += 1
# текущ. слово - термин родства в Р. п.
elif is_kinship_term(word, case='gent'):
prev_kin = True
prev_def = False
i += 1
else:
# текущ. слово - существительное в Р. п.
if is_noun(word, case='gent'):
results.append(sent[start:i + 1])
else:
results.append(sent[start:i])
prev_kin = False
prev_def = False
else: # мы вне конструкции
i += 1
return results 
Проверка, является ли слово термином родства, определением или существительным, осуществляется с помощью специальных функций is_kinship_term, is_definition и is_noun.
В функции is_kinship_term мы получаем начальную форму и список грамматических категорий слова с помощью морфологического анализатора pymorphy2 и затем проверяем, входит ли начальная форма в заранее заданный вручную список терминов родства (для примера здесь приводится неполный список).
Функция parse в pymorphy2 возвращает несколько вариантов морфологического разбора в порядке убывания вероятности того, что этот разбор является верным. Таким образом, наиболее вероятным является первый вариант разбора, однако он не всегда оказывается верным, например в случае совпадения форм разных падежей существительного. Чтобы избежать возможных ошибок, мы рассматриваем все варианты разбора, предлагаемые функцией parse, а не только первый, как предлагается в документации библиотеки.
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
kinship_term_list = ['мать', 'отец', 'дочь', 'сын', 'бабушка', 'дедушка', 'муж', 'жена', 'сестра', 'брат']
def is_kinship_term(s, case=None): # термин родства?
s_parse = morph.parse(s)
if case is None:
for v in s_parse:
if v.normal_form in kinship_term_list:
return True
else:
for v in s_parse:
if v. normal_form in kinship_term_list and v.tag.case == case:
return True
return False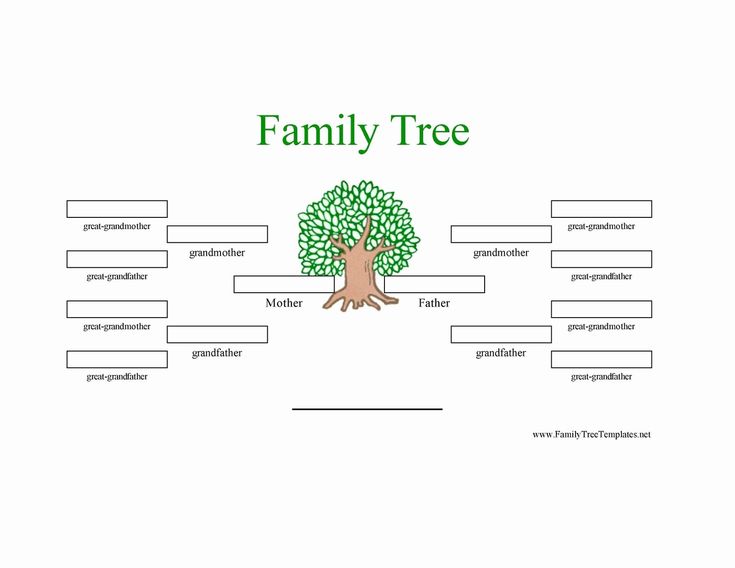 normal_form in kinship_term_list and v.tag.case == case:
return True
return False
normal_form in kinship_term_list and v.tag.case == case:
return True
return FalseВ функции is_definition мы также парсим слово с помощью pymorphy2 и проверяем тег части речи: он должен быть ADJF, ADJS, PRTF или PRTS. Таким образом в pymorphy2 кодируются полные и краткие прилагательные и причастия, а также порядковые числительные и местоимения-прилагательные.
def is_definition(s): # определение?
s_parse = morph.parse(s)
for v in s_parse:
if v.tag.POS in ['ADJF', 'ADJS', 'PRTF', 'PRTS']:
return True
return FalseАналогичным образом работает функция is_noun.
Типы конструкции
Вернемся к примерам конструкций, которые мы рассмотрели вначале (сестра моей покойной бабушки, бабушкина сестра, сестра бабушки моей подруги). Теперь нужно убрать из них лишние определения, а затем определить, к какому типу конструкции относится каждая из них.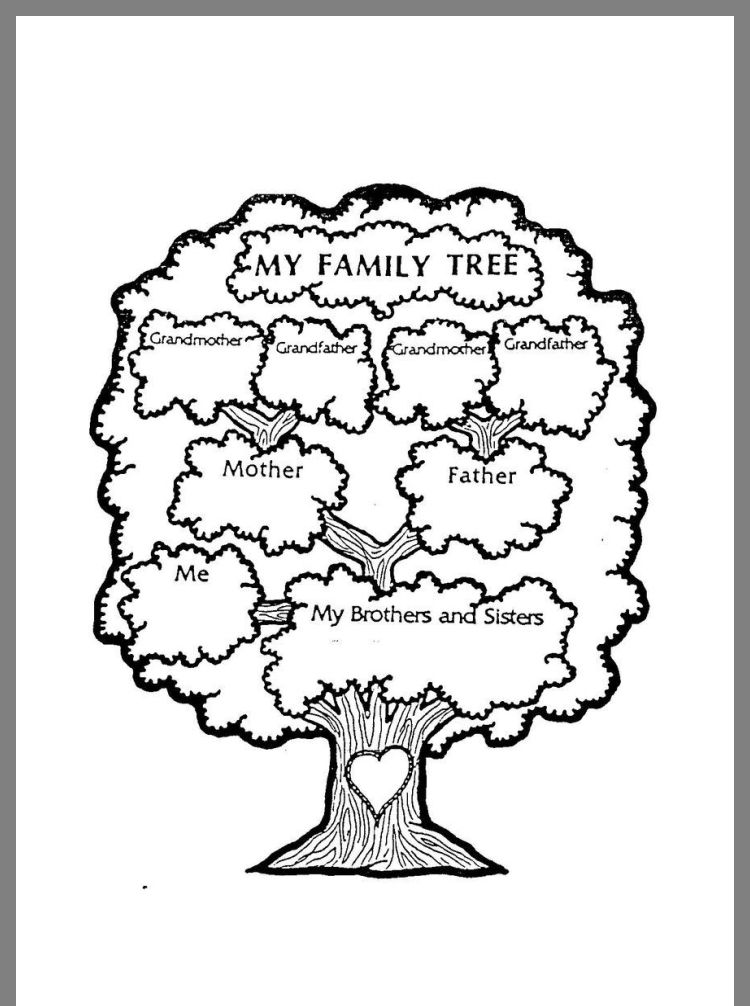 Мы выделили пять типов конструкции, основываясь на примерах приведенных вначале. Эти типы конструкции описывают большую часть случаев использования посессивных конструкций с терминами родства в русском языке.
Мы выделили пять типов конструкции, основываясь на примерах приведенных вначале. Эти типы конструкции описывают большую часть случаев использования посессивных конструкций с терминами родства в русском языке.
Там, где падеж существительного не указан, он может быть любым. n=0,1,2… означает ноль или более таких слов (терминов родства в родительном падеже).
- притяжательное прилагательное со значением родства / притяжательное местоимение + термин родства
Пример: бабушкина сестра - термин родства + термин родства (Р. п.) (n=0,1,2…) + притяжательное местоимение + термин родства (Р. п.)
Пример: сестра моей бабушки - термин родства + термин родства (Р. п.) (n=0,1,2…) + притяжательное местоимение
Пример: сестра бабушки моей - термин родства + термин родства (Р. п.) (n=0,1,2…) + существительное (не термин родства) (Р. п.)
Пример: сестра бабушки подруги - термин родства + термин родства (Р. п.) (n=0,1,2…)
Пример: сестра бабушки
 п.) (n=0,1,2…) + существительное (не термин родства) (Р. п.)
п.) (n=0,1,2…) + существительное (не термин родства) (Р. п.)Рассмотрим, как устроено определение типа конструкции в программе, на примере
seq_original = ['сестрой', 'моей', 'покойной', 'бабушки']
seq_as_type = []
for word in seq_original:
if not is_kinship_term(word) and is_definition(word) and not is_poss_adj(word) and not is_pronoun(word):
continue
seq_as_type.append(word)В seq_as_type после этого будет сохранен список [‘сестрой’, ‘моей’, ‘бабушки’].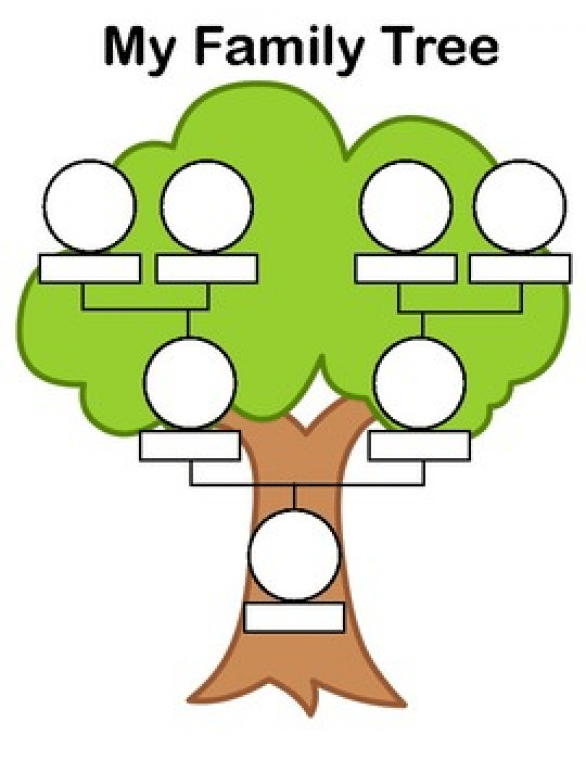
Затем проверим, подходит ли конструкция под тип 2.
sec_last_word = seq_as_type[len(seq_as_type) - 2] # предпоследнее слово
last_word = seq_as_type[-1] # последнее слово
flag = True
if (is_pronoun(sec_last_word) or is_poss_adj(sec_last_word)) and not is_kinship_term(sec_last_word) \
and is_kinship_term(last_word):
for word in seq_as_type:
if is_kinship_term(word) or word == sec_last_word:
continue
flag = FalseВ результате flag = True — конструкция подходит под тип 2.
Нормальная форма
Наконец, нам нужно привести конструкцию к так называемой нормальной форме — виду, где все слова в конструкции, кроме первого, являются терминами родства в начальной форме и расставлены в прямом порядке родства (подробнее см. ниже).
- сестра моей бабушки —> я бабушка сестра
Как получить нормальную форму?
- термины родства приведем к начальной форме (напрямую с помощью pymorphy2)
- другие существительные поставим в именительный падеж с сохранением числа (с помощью функции inflect из pymorphy2)
- притяжательные местоимения заменим на соответствующие им личные в начальной форме: мой —> я (по заранее заготовленному словарю)
- притяжательные прилагательные со значением родства заменим на соответствующие им термины родства в начальной форме: бабушкин —> бабушка (также по заранее заготовленному словарю)
Теперь расставим слова в конструкции в так называемом прямом порядке родства: справа от слова должно стоять то слово, от которого к нему в оригинальной конструкции задается вопрос чьего? / чьей? или вопрос родительного падежа кого? (см. примеры ниже). В программе на этом шаге мы делаем следующее, в зависимости от типа конструкции:
примеры ниже). В программе на этом шаге мы делаем следующее, в зависимости от типа конструкции:
Тип 1: вставляем в начало местоимение я.
- бабушкина сестра —> бабушка сестра —> я бабушка сестра
Тип 2: меняем местами последние два слова, меняем порядок слов на обратный.
- сестра моей бабушки —> сестра я бабушка —> сестра бабушка я —> я бабушка сестра
Тип 3, 4: меняем порядок слов на обратный.
- сестра бабушки моей —> сестра бабушка я —> я бабушка сестра
- сестра бабушки подруги —> сестра бабушка подруга —> подруга бабушка сестра
Тип 5: меняем порядок слов на обратный, вставляем в начало местоимение я.
- сестра бабушки —> сестра бабушка —> я бабушка сестра
В таком виде конструкция готова для построения графа родственных связей.![]()
Шаблоны
Перейдем к построению графа, который затем изобразим в виду генеалогического дерева. Заранее подготовим шаблон для каждого термина родства — фрагмент графа, отражающий соответствующие родственные связи. См. пример: шаблон для слова сестра.
Как это реализовано в программе? Мы храним шаблоны и итоговый граф в виде списков экземпляров класса Relative. Полями класса являются:
- id — уникальный идентификатор персонажа
- name — имя персонажа
- relations — словарь:
ключи — шесть возможных прямых связей: mother, father, daughter, son, wife, husband
значения — списки id тех персонажей, с которыми данный персонаж связан этой связью
class Relative:
def __init__(self, id, name):
self.id = id
self.name = name
self.relations = {'mother': [], 'father': [], 'daughter': [], 'son': [], 'husband': [], 'wife': []}В рамках списка, представляющего граф или шаблон, экземпляры класса Relative отсортированы по возрастанию id.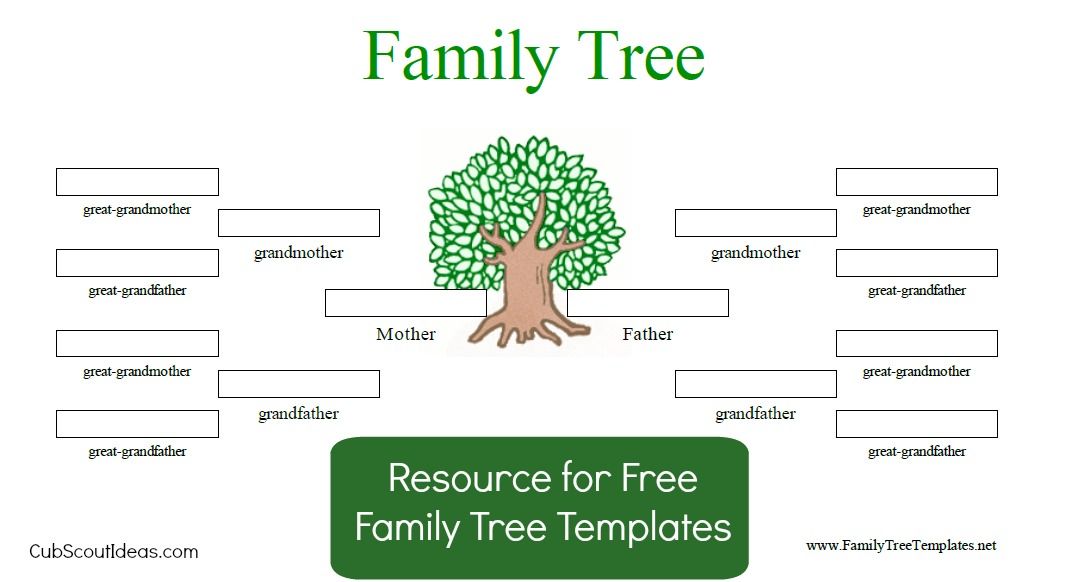
Соединение шаблонов
Чтобы построить единый граф, будем последовательно загружать шаблон для каждого термина родства в конструкции и присоединять его к уже имеющемуся графу. При этом мы будем совмещать корень данного шаблона — узел с надписью я — с вершиной предыдущего — узлом, который подписан данным термином родства (например, сестра). На картинке ниже изображено присоединение шаблона бабушка к шаблону сестра. Здесь совмещаются узел сестра (вершина шаблона сестра) и узел я (корень шаблона бабушка).
Посмотрим, как это реализовано в программе. Зададим текущий граф, состоящий из шаблона сестра.
me = Relative(id=0, name='я')
me.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
mom = Relative(id=1, name='мать')
mom.relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [2], 'wife': []}
dad = Relative(id=2, name='отец')
dad. relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [], 'wife': [1]}
sis = Relative(id=3, name='сестра')
sis.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
relatives = [me, mom, dad, sis] relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [], 'wife': [1]}
sis = Relative(id=3, name='сестра')
sis.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
relatives = [me, mom, dad, sis]
relations = {'mother': [], 'father': [], 'daughter': [0, 3], 'son': [], 'husband': [], 'wife': [1]}
sis = Relative(id=3, name='сестра')
sis.relations = {'mother': [1], 'father': [2], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
relatives = [me, mom, dad, sis]Зададим шаблон бабушка.
me = Relative(id=0, name='я')
me.relations = {'mother': [1], 'father': [], 'daughter': [], 'son': [], 'husband': [], 'wife': []}
mom = Relative(id=1, name='мать')
mom.relations = {'mother': [2], 'father': [], 'daughter': [0], 'son': [], 'husband': [], 'wife': []}
gran = Relative(id=2, name='бабушка')
gran.relations = {'mother': [], 'father': [], 'daughter': [1], 'son': [], 'husband': [], 'wife': []}
template = [me, mom, gran]Добавим шаблон бабушка к графу.
prev_top_id = 3 # идентификатор вершины предыдущего шаблона
# заменяем id персонажей шаблона на их текущий id + prev_top_id
for rel in template:
rel.id += prev_top_id
for rel_type in rel. relations:
for i in range(len(rel.relations[rel_type])):
rel.relations[rel_type][i] += prev_top_id
# находим вершину предыд. шаблона в relatives (запоминаем индекс в списке)
for i in range(len(relatives)):
if relatives[i].id == prev_top_id:
real_top_ind = i
break
# добавляем relations корня нового шаблона в relations вершины предыдущего
template_root_relations = template[0].relations
for rel_type in relatives[real_top_ind].relations:
relatives[real_top_ind].relations[rel_type].extend(template_root_relations[rel_type])
# добавляем в основной массив relatives родственников из шаблона, кроме его корня
for rel in template[1:]:
relatives.append(rel) relations:
for i in range(len(rel.relations[rel_type])):
rel.relations[rel_type][i] += prev_top_id
# находим вершину предыд. шаблона в relatives (запоминаем индекс в списке)
for i in range(len(relatives)):
if relatives[i].id == prev_top_id:
real_top_ind = i
break
# добавляем relations корня нового шаблона в relations вершины предыдущего
template_root_relations = template[0].relations
for rel_type in relatives[real_top_ind].relations:
relatives[real_top_ind].relations[rel_type].extend(template_root_relations[rel_type])
# добавляем в основной массив relatives родственников из шаблона, кроме его корня
for rel in template[1:]:
relatives.append(rel)
relations:
for i in range(len(rel.relations[rel_type])):
rel.relations[rel_type][i] += prev_top_id
# находим вершину предыд. шаблона в relatives (запоминаем индекс в списке)
for i in range(len(relatives)):
if relatives[i].id == prev_top_id:
real_top_ind = i
break
# добавляем relations корня нового шаблона в relations вершины предыдущего
template_root_relations = template[0].relations
for rel_type in relatives[real_top_ind].relations:
relatives[real_top_ind].relations[rel_type].extend(template_root_relations[rel_type])
# добавляем в основной массив relatives родственников из шаблона, кроме его корня
for rel in template[1:]:
relatives.append(rel)Объединение дублирующихся персонажей
Можно заметить, в получившемся графе две вершины с надписью мать, поскольку в обоих шаблонах была такая вершина и при присоединении нового шаблона они не были совмещены. Такие случаи дублирования персонажей можно выявить на основании предположения, что у каждого персонажа может быть не более чем одна мать и один отец. Как сделать это в программе?
Как сделать это в программе?
# наибольшее возможное связей данного типа
max_rel_number = {'mother': 1, 'father': 1,
'daughter': float('inf'), 'son': float('inf'),
'husband': float('inf'), 'wife': float('inf')}
# сделаем табличку: в каждой строчке список id, которые на самом деле относятся к одному персонажу
id_duplicates = []
for rel in relatives:
for rel_type in rel.relations:
# если персонаж связан данным типом связи с большим числом персонажей, чем разрешено
if len(rel.relations[rel_type]) > max_rel_number[rel_type]:
num = -1
# ищем, вдруг строчка про этого персонажа уже есть в таблице
for v in rel.relations[rel_type]:
for i in range(len(id_duplicates)):
if v in id_duplicates[i]:
num = i # сохраняем номер строки в таблице в num
break
# если еще нет, записываем в новую строку
if num == -1:
id_duplicates. append(rel.relations[rel_type])
# если есть, дописываем в нее
else:
for v in rel.relations[rel_type]:
if v not in id_duplicates[num]:
id_duplicates.append(v)
for i in range(len(id_duplicates)):
id_duplicates[i] = tuple(id_duplicates[i])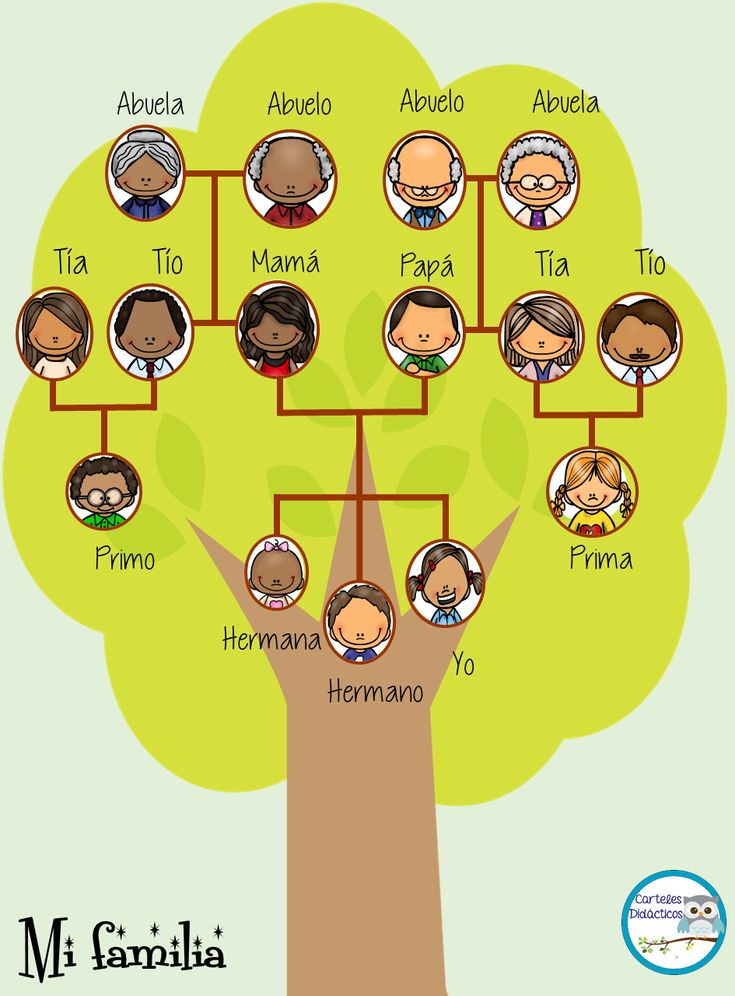 append(rel.relations[rel_type])
# если есть, дописываем в нее
else:
for v in rel.relations[rel_type]:
if v not in id_duplicates[num]:
id_duplicates.append(v)
for i in range(len(id_duplicates)):
id_duplicates[i] = tuple(id_duplicates[i])
append(rel.relations[rel_type])
# если есть, дописываем в нее
else:
for v in rel.relations[rel_type]:
if v not in id_duplicates[num]:
id_duplicates.append(v)
for i in range(len(id_duplicates)):
id_duplicates[i] = tuple(id_duplicates[i])В итоге в нашем случае id_duplicates = [(1, 4)].
Теперь объединим дублирующихся персонажей, которых мы выявили.
# создадим словарь "старый id : новый id"
final_ids = {}
for lst in id_duplicates:
for v in lst:
final_ids[v] = min(lst) # для дублир. персонажей берем минимум строки
for rel in relatives:
if rel.id not in final_ids:
final_ids[rel.id] = rel.id # для остальных - оставляем старый id
new_relatives = []
for lst in id_duplicates:
# создадим нового персонажа и сохраним в спец. массив
for rel in relatives: # ищем персонажа с соотв. final_id - от него возьмем name
if rel.id == final_ids[lst[0]]:
final_name = rel. name
new_rel = Relative(id=final_ids[lst[0]], name=final_name)
# relations - соберем ото всех, чьи id указаны в строке
for rel in relatives:
if rel.id in lst:
for rel_type in rel.relations:
for v in rel.relations[rel_type]:
if v not in new_rel.relations[rel_type]:
new_rel.relations[rel_type].append(final_ids[v])
new_relatives.append(new_rel)
# найдем, у кого персонаж числится в relations, и заменим id на final_id + удалим лишние записи
for rel in relatives:
for rel_type in rel.relations:
for i in range(len(rel.relations[rel_type])):
if rel.relations[rel_type][i] in lst:
rel.relations[rel_type][i] = final_ids[lst[0]]
for rel in relatives:
for rel_type in rel.relations:
rel.relations[rel_type] = list(set(rel.relations[rel_type]))
# удалим всех персонажей, кот. записаны более одного раза
for lst in id_duplicates:
ind = 0
while relatives and ind < len(relatives):
if relatives[ind]. id in lst:
del relatives[ind]
else:
ind += 1
# добавим новосозданных персонажей (массив new_relatives)
relatives.extend(new_relatives)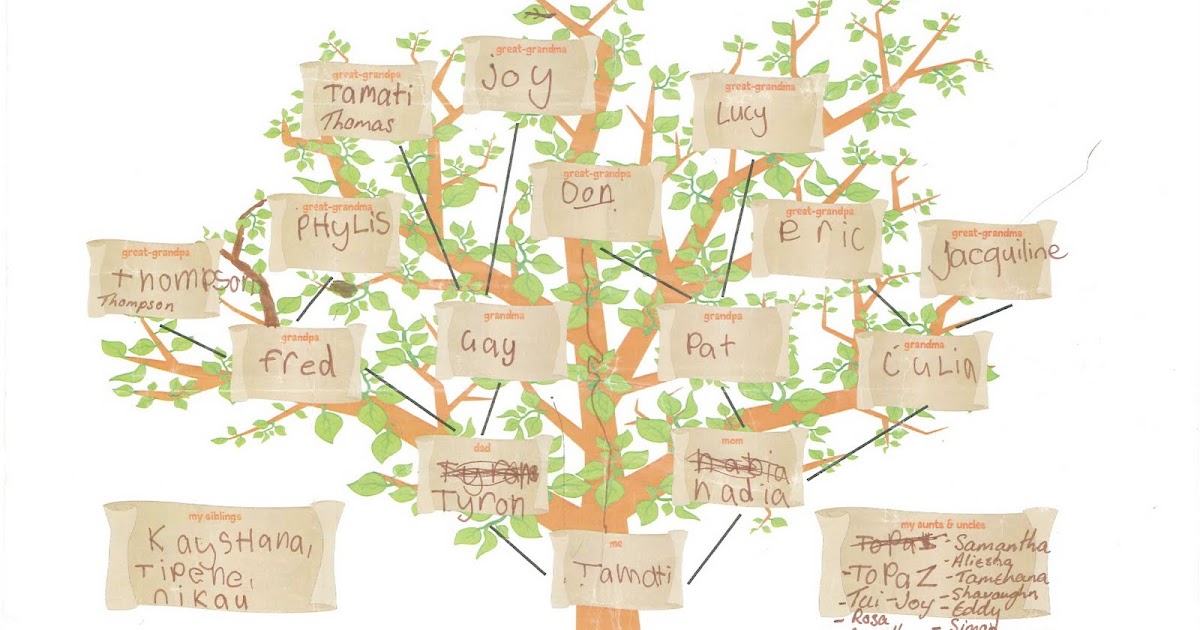 name
new_rel = Relative(id=final_ids[lst[0]], name=final_name)
# relations - соберем ото всех, чьи id указаны в строке
for rel in relatives:
if rel.id in lst:
for rel_type in rel.relations:
for v in rel.relations[rel_type]:
if v not in new_rel.relations[rel_type]:
new_rel.relations[rel_type].append(final_ids[v])
new_relatives.append(new_rel)
# найдем, у кого персонаж числится в relations, и заменим id на final_id + удалим лишние записи
for rel in relatives:
for rel_type in rel.relations:
for i in range(len(rel.relations[rel_type])):
if rel.relations[rel_type][i] in lst:
rel.relations[rel_type][i] = final_ids[lst[0]]
for rel in relatives:
for rel_type in rel.relations:
rel.relations[rel_type] = list(set(rel.relations[rel_type]))
# удалим всех персонажей, кот. записаны более одного раза
for lst in id_duplicates:
ind = 0
while relatives and ind < len(relatives):
if relatives[ind].
name
new_rel = Relative(id=final_ids[lst[0]], name=final_name)
# relations - соберем ото всех, чьи id указаны в строке
for rel in relatives:
if rel.id in lst:
for rel_type in rel.relations:
for v in rel.relations[rel_type]:
if v not in new_rel.relations[rel_type]:
new_rel.relations[rel_type].append(final_ids[v])
new_relatives.append(new_rel)
# найдем, у кого персонаж числится в relations, и заменим id на final_id + удалим лишние записи
for rel in relatives:
for rel_type in rel.relations:
for i in range(len(rel.relations[rel_type])):
if rel.relations[rel_type][i] in lst:
rel.relations[rel_type][i] = final_ids[lst[0]]
for rel in relatives:
for rel_type in rel.relations:
rel.relations[rel_type] = list(set(rel.relations[rel_type]))
# удалим всех персонажей, кот. записаны более одного раза
for lst in id_duplicates:
ind = 0
while relatives and ind < len(relatives):
if relatives[ind].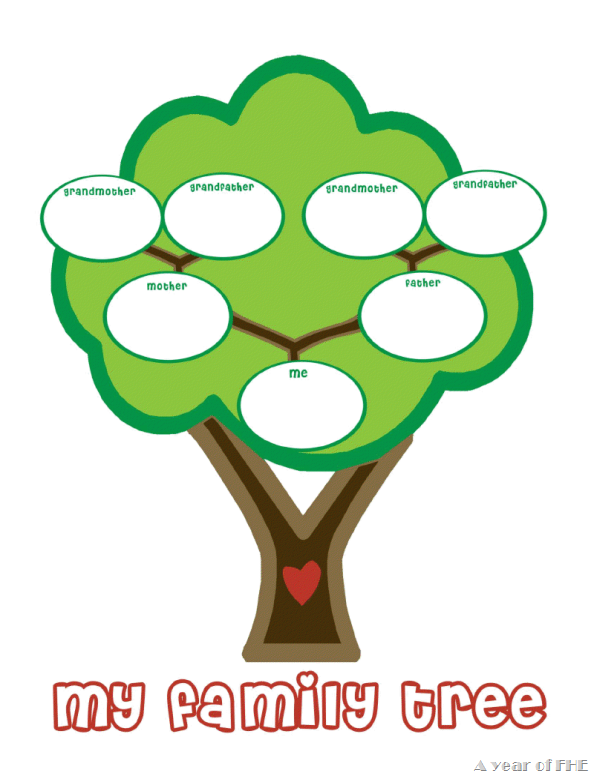 id in lst:
del relatives[ind]
else:
ind += 1
# добавим новосозданных персонажей (массив new_relatives)
relatives.extend(new_relatives)
id in lst:
del relatives[ind]
else:
ind += 1
# добавим новосозданных персонажей (массив new_relatives)
relatives.extend(new_relatives)Граф из примера в итоге будет выглядеть так.
Стоит отметить, что в примере мы рассмотрели бабушку по матери, однако она может также быть бабушкой по отцу. Вследствие языковой неоднозначности, многим терминам родства соответствуют несколько шаблонов. Мы храним все возможные шаблоны для каждого термина родства и генерируем несколько вариантов финального графа, учитывая все возможные комбинации шаблонов.
Приступим к финальному этапу — визуализации графа. Составим список имен узлов и список ребер.
nodes = ['я', 'мать', 'отец', 'сестра', 'бабушка', 'муж']
edges = [('я', 'мать'), ('я', 'отец'), ('мать', 'отец'),
('мать', 'бабушка'), ('бабушка', 'муж'),
('сестра', 'мать'), ('сестра', 'отец')]Зададим координаты узлов по следующим правилам:
- родитель на один пункт выше ребенка
- ребенок на один пункт ниже родителя
- жена/муж на один пункт вправо от супруга(-и)
- если это место уже занято, сдвигаем узел на один пункт вправо
pos = {'я': (0, 0), 'мать': (0, 1), 'отец': (1, 1), 'сестра': (1, 0), 'бабушка': (0, 2), 'муж': (1, 2)}Создадим список цветов узлов
- cornflowerblue (синий) — персонаж соответствует первому или последнему слову в конструкции
- skyblue (голубой) — персонаж напрямую упомянут в конструкции, но не является первым или последним
- lightgrey (серый) — персонаж не упомянут в конструкции
node_color = ['cornflowerblue', 'lightgrey', 'lightgrey', 'skyblue', 'skyblue', 'cornflowerblue']
Зададим пол персонажей, чтобы затем отразить его через форму узлов:
- круг — женщины (f)
- квадрат — мужчины (m)
- ромб — пол не определен (n) (используется для первого слова в конструкции)
node_sex = ['n', 'f', 'm', 'f', 'f', 'm']
Зададим размеры окна, где будет расположен граф, а также саму конструкцию и предложение, в котором она была найдена, чтобы подписать их на картинке.
word_sequence = 'муж бабушки моей сестры' sentence = 'Я знал его с детства - это был муж бабушки моей сестры.' # размеры окна - рассчитываются из координат узлов size_x = 1 size_y = 2 right = 1 top = 2 bottom = 0
После этого сохраним граф в виде специальной графовой структуры, реализованной в библиотеке NetworkX, и отрисуем финальную картинку с помощью библиотеки Matplotlib.
import networkx as nx import matplotlib.pyplot as plt
Подготовим фон, на котором будет нарисован граф (он загружается из файла png).
import os
background_img = plt.imread('background_img.png')
# зададим три группы узлов в соответствии с их формой
f_list = []
m_list = []
n_list = []
f_color = []
m_color = []
n_color = []
f_pos = {}
m_pos = {}
n_pos = {}
for node, sex, color in zip(nodes, node_sex, node_color):
if sex == "f":
f_list.append(node)
f_color.append(color)
f_pos.update({node: pos[node]})
elif sex == "m":
m_list.append(node)
m_color. append(color)
m_pos.update({node: pos[node]})
else:
n_list.append(node)
n_color.append(color)
n_pos.update({node: pos[node]})
fig = plt.figure(figsize=(size_x + 19, size_y + 19))
ax = fig.add_subplot(111)
# вверху укажем конструкцию
fig.set(facecolor='white')
ax.set(facecolor='white')
ax.set_title(word_sequence, fontsize=40, fontweight='bold')
# внизу - предложение, где она была найдена
plt.figtext(0.5, 0.01, sentence, ha="center", fontsize=22,
bbox={"facecolor": "blue", "alpha": 0.1, "pad": 5}, wrap=True)
# сам граф отрисуем в рамке на светло-сером фоне
ax.imshow(background_img, extent=[-0.5, right + 0.5, bottom - 0.5, top + 0.5])
# добавим в граф узлы и ребра
G = nx.Graph()
nx.draw_networkx_nodes(G, f_pos, f_list, node_shape='o', node_size=7000, node_color=f_color, alpha=0.9)
nx.draw_networkx_nodes(G, m_pos, m_list, node_shape='s', node_size=7000, node_color=m_color, alpha=0.9)
nx.draw_networkx_nodes(G, n_pos, n_list, node_shape='d', node_size=7000, node_color=n_color, alpha=0. 9)
G.add_edges_from(edges)
nx.draw_networkx_edges(G, pos, width=3, edge_color="grey")
nx.draw_networkx_labels(G, pos, font_size=18, font_weight='bold', labels=dict(zip(nodes, nodes)))
# сохраним картинку в файл
plt.savefig('graph.png')
fig.clf()
plt.close(fig=fig)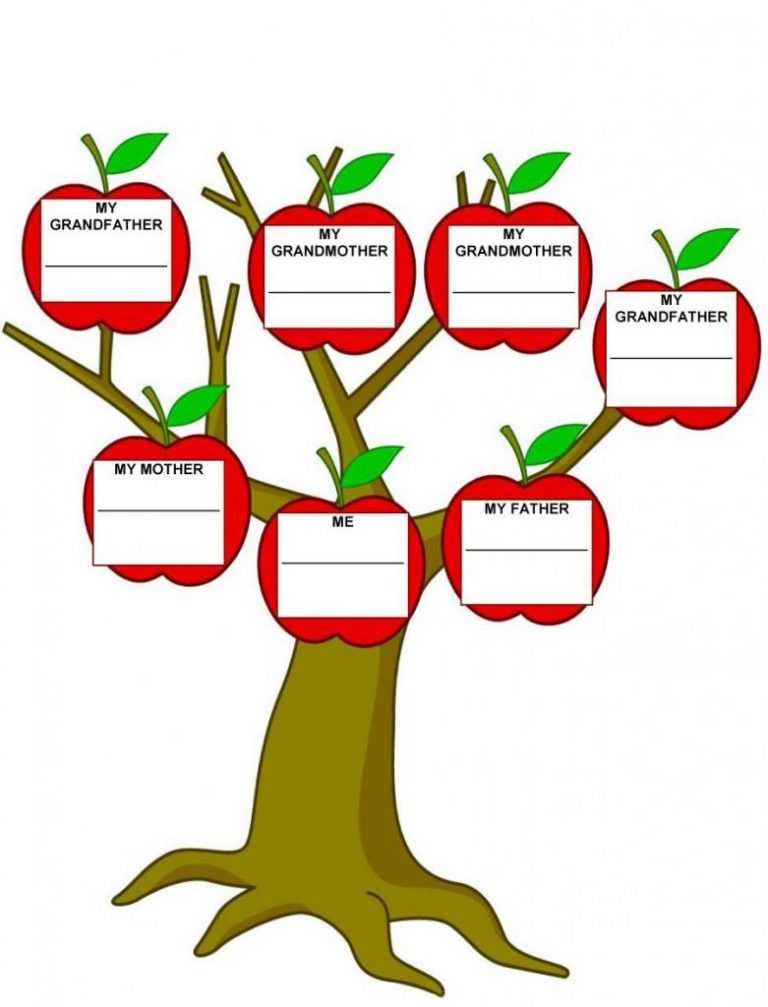 append(color)
m_pos.update({node: pos[node]})
else:
n_list.append(node)
n_color.append(color)
n_pos.update({node: pos[node]})
fig = plt.figure(figsize=(size_x + 19, size_y + 19))
ax = fig.add_subplot(111)
# вверху укажем конструкцию
fig.set(facecolor='white')
ax.set(facecolor='white')
ax.set_title(word_sequence, fontsize=40, fontweight='bold')
# внизу - предложение, где она была найдена
plt.figtext(0.5, 0.01, sentence, ha="center", fontsize=22,
bbox={"facecolor": "blue", "alpha": 0.1, "pad": 5}, wrap=True)
# сам граф отрисуем в рамке на светло-сером фоне
ax.imshow(background_img, extent=[-0.5, right + 0.5, bottom - 0.5, top + 0.5])
# добавим в граф узлы и ребра
G = nx.Graph()
nx.draw_networkx_nodes(G, f_pos, f_list, node_shape='o', node_size=7000, node_color=f_color, alpha=0.9)
nx.draw_networkx_nodes(G, m_pos, m_list, node_shape='s', node_size=7000, node_color=m_color, alpha=0.9)
nx.draw_networkx_nodes(G, n_pos, n_list, node_shape='d', node_size=7000, node_color=n_color, alpha=0.
append(color)
m_pos.update({node: pos[node]})
else:
n_list.append(node)
n_color.append(color)
n_pos.update({node: pos[node]})
fig = plt.figure(figsize=(size_x + 19, size_y + 19))
ax = fig.add_subplot(111)
# вверху укажем конструкцию
fig.set(facecolor='white')
ax.set(facecolor='white')
ax.set_title(word_sequence, fontsize=40, fontweight='bold')
# внизу - предложение, где она была найдена
plt.figtext(0.5, 0.01, sentence, ha="center", fontsize=22,
bbox={"facecolor": "blue", "alpha": 0.1, "pad": 5}, wrap=True)
# сам граф отрисуем в рамке на светло-сером фоне
ax.imshow(background_img, extent=[-0.5, right + 0.5, bottom - 0.5, top + 0.5])
# добавим в граф узлы и ребра
G = nx.Graph()
nx.draw_networkx_nodes(G, f_pos, f_list, node_shape='o', node_size=7000, node_color=f_color, alpha=0.9)
nx.draw_networkx_nodes(G, m_pos, m_list, node_shape='s', node_size=7000, node_color=m_color, alpha=0.9)
nx.draw_networkx_nodes(G, n_pos, n_list, node_shape='d', node_size=7000, node_color=n_color, alpha=0. 9)
G.add_edges_from(edges)
nx.draw_networkx_edges(G, pos, width=3, edge_color="grey")
nx.draw_networkx_labels(G, pos, font_size=18, font_weight='bold', labels=dict(zip(nodes, nodes)))
# сохраним картинку в файл
plt.savefig('graph.png')
fig.clf()
plt.close(fig=fig)
9)
G.add_edges_from(edges)
nx.draw_networkx_edges(G, pos, width=3, edge_color="grey")
nx.draw_networkx_labels(G, pos, font_size=18, font_weight='bold', labels=dict(zip(nodes, nodes)))
# сохраним картинку в файл
plt.savefig('graph.png')
fig.clf()
plt.close(fig=fig)Итоговая картинка будет выглядеть вот так.
Мы визуализировали конструкцию в виде генеалогического дерева — цель достигнута!
Мы надеемся, что вам было интересно прочитать этот материал и при желании вы сможете повторить наш результат самостоятельно. Вы можете сами запустить фрагменты кода из этого материала вот здесь в jupyter notebook, а полный код проекта и примеры работы программы можно посмотреть в нашем гитхаб-репозитории.
Большой шаблон генеалогического древа на испанском языке Векторное изображение
Шаблон большого генеалогического древа на испанском языке Векторное изображение- Семейные векторы
 org/ListItem»> лицензионные векторы
org/ListItem»> лицензионные векторыЛицензияПодробнее
Стандарт Вы можете использовать вектор в личных и коммерческих целях. Расширенный Вы можете использовать вектор на предметах для перепродажи и печати по требованию.Тип лицензии определяет, как вы можете использовать этот образ.
| Станд. | Расшир. | |
|---|---|---|
| Печатный/редакционный | ||
| Графический дизайн | ||
| Веб-дизайн | ||
| Социальные сети | ||
| Редактировать и изменить | ||
| Многопользовательский | ||
| Предметы перепродажи | ||
| Печать по запросу |
Владение Узнать больше
Эксклюзивный Этот вектор становится исключительно вашим для любых целей. Художник перестанет лицензировать его другим.
Художник перестанет лицензировать его другим.Хотите, чтобы это векторное изображение было только у вас? Эксклюзивный выкуп обеспечивает все права этого вектора.
Мы удалим этот вектор из нашей библиотеки, а художник прекратит продажу работ.
Способы покупкиСравнить
Плата за изображение $ 14,99 Кредиты $ 1,00 Подписка 9 долларов0082 0,69Оплатить стандартные лицензии можно тремя способами. Цены составляют $ $.
| Оплата с помощью | Цена изображения |
|---|---|
| Плата за изображение $ 14,99 Одноразовый платеж | |
| Предоплаченные кредиты $ 1 Загружайте изображения по запросу (1 кредит = 1 доллар США). Минимальная покупка 30р. | |
План подписки От 69 центов Выберите месячный план. Неиспользованные загрузки автоматически переносятся на следующий месяц. Неиспользованные загрузки автоматически переносятся на следующий месяц. | |
Способы покупкиСравнить
Плата за изображение $ 39,99 Кредиты $ 30,00Существует два способа оплаты расширенных лицензий. Цены составляют $ $.
| Оплата с помощью | Стоимость изображения |
|---|---|
| Плата за изображение $ 39,99 Оплата разовая, регистрация не требуется. | |
| Предоплаченные кредиты $ 30 Загружайте изображения по запросу (1 кредит = 1 доллар США). | |
Оплата
Плата за изображение $ 499Дополнительные услугиПодробнее
Настроить изображение Доступно только с оплатой за изображение 9 долларов0082 85,00Нравится изображение, но нужно всего лишь несколько модификаций? Пусть наши талантливые художники сделают всю работу за вас!
Мы свяжем вас с дизайнером, который сможет внести изменения и отправить вам изображение в выбранном вами формате.
Примеры
- Изменить текст
- Изменить цвета
- Изменить размер до новых размеров
- Включить логотип или символ
- Добавьте название своей компании или компании
Включенные файлы
Подробности загрузки…
- Идентификатор изображения
- 21248037
- Цветовой режим
- RGB
- Художник
- сиенпи
Полезная диаграмма семейного древа с семейными словами • 7ESL
Штифт
Карта семейных отношений! Список полезных семейных слов с диаграммой генеалогического древа и диаграммой отношений. Вероятно, очень легко говорить о своем генеалогическом древе на родном языке, но можете ли вы сделать то же самое, говоря по-английски? Если ответ отрицательный, не о чем беспокоиться, потому что в этом разделе вы узнаете, как рассказывать о своем генеалогическом древе и о том, как разные люди связаны друг с другом.
Это чрезвычайно полезно, когда вы говорите о себе и своей семье, а также когда вам нужно слушать и понимать, когда кто-то другой объясняет вам свое генеалогическое древо.
Содержание
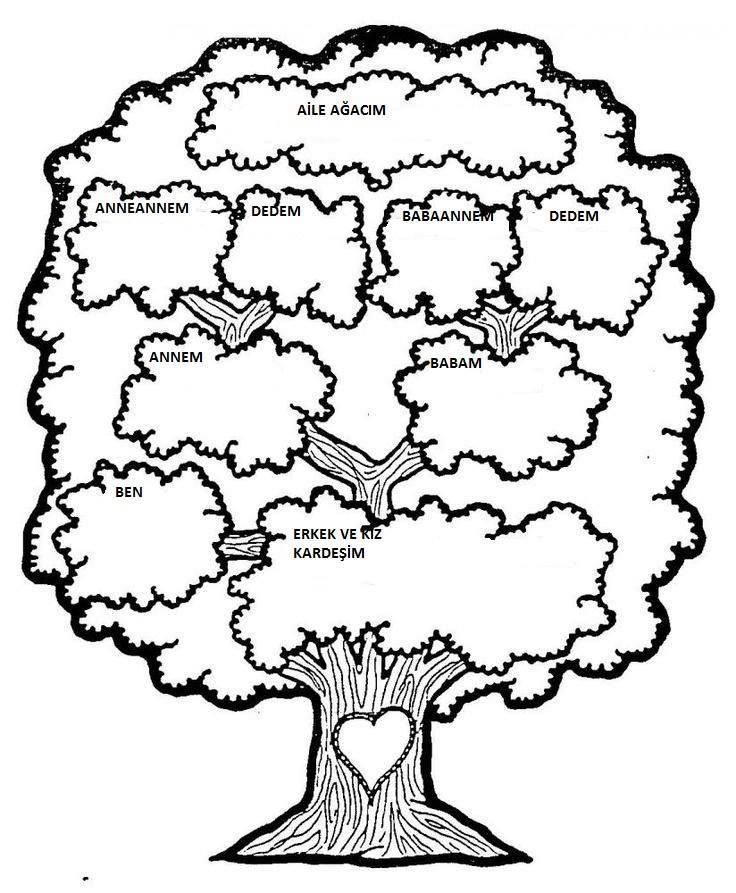
Семейное древо
Family Words
- Прадедушка
- Прабабушка
- Великий дедушка
- Дедушка
- Бабушка
- двоюродная бабушка
- Дядя
- Тетя
- Отец
- Мать
- Дядя (муж тети)
- Сестра
- Шурин
- Брат
- Невестка
- Муж
- Жена
- Кузен
- Жена двоюродного брата
- Кузен
- Муж двоюродной сестры
- Племянник
- Племянница
- Сын
- Невестка
- Дочь
- Зять
- Двоюродный брат однажды удален
- Внук
- Внучка
Штифт
Семейная лексика с картинками и примерами
Учим членов семьи на английском языке с примерами и видеоуроком.
— Этот антиквариат принадлежал его прадеду .
Штифт
Прабабушка– Эти золотые часы были переданы моей прабабушкой .
Штифт
Двоюродный дедушка– Моего двоюродного дедушку на самом деле отправили домой из британской больницы, потому что в тот день не хватило коек.
Штифт
Дедушка– прошлой ночью во сне я вспомнил своего дедушку .
Штифт
Бабушка– Моя бабушка научила меня шить.
Штифт
Двоюродная бабушка – Ваша двоюродная бабушка была очень доброй женщиной.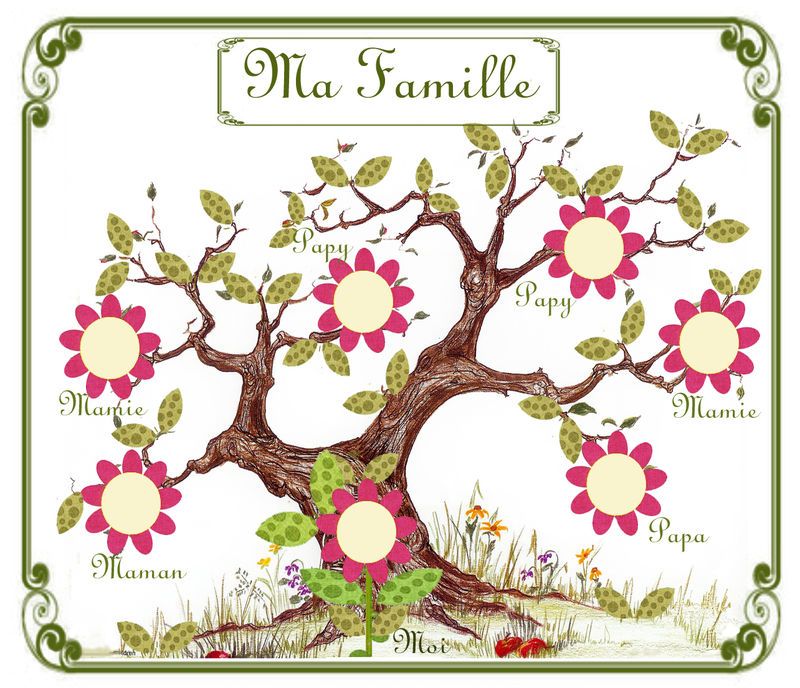
Штифт
Дядя– Я мало общаюсь с моим дядя .
Штифт
Тетя– Серьги были подарком моей тети .
Штифт
Отец– Я не получал пособие от отца .
Штифт
Мать– Каждая мать считает своего ребенка красивым.
Штифт
Дядя (Муж тети)— Мой дядя путешествует по Южной Америке.
Штифт
Сестра– Я делю спальню со своей сестрой .
Штифт
Шурин – Его шурин произнес тост за счастливую пару.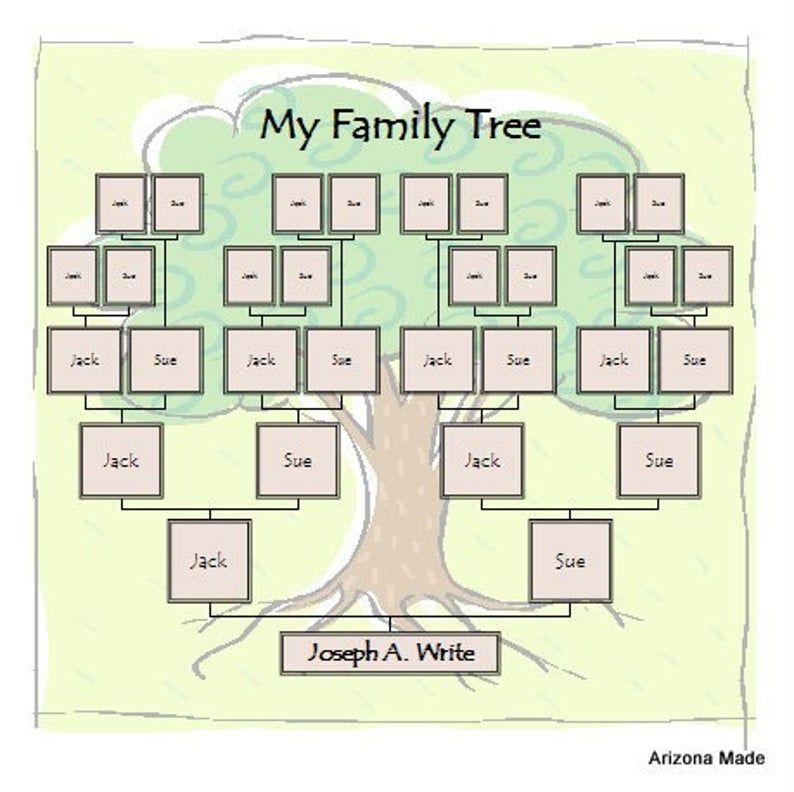
Штифт
Брат– Я получил письмо от моего брата .
Штифт
Невестка— Она такого же роста, как и ее невестка .
Штифт
Муж– Она не любит противоречить своему мужу на публике.
Штифт
Жена— Его жена обладает сильным характером.
Штифт
Двоюродный брат– Я надеюсь пойти и остаться со своими двоюродный брат Том на Рождество.
Штифт
Жена двоюродного брата – Вам сообщение от жены вашего двоюродного брата .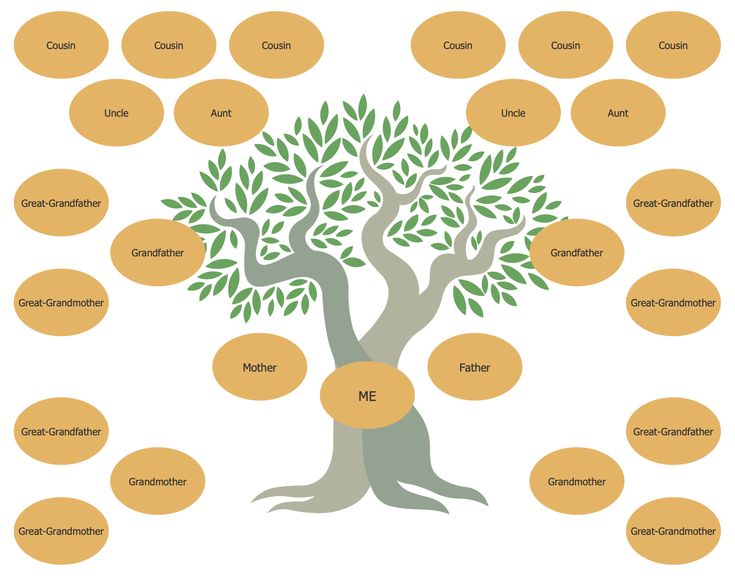
Штифт
Кузина— Дальняя двоюродная сестра .
Штифт
Муж двоюродной сестры— Муж его двоюродной сестры — известный профессиональный теннисист.
Пин
Племянник— Он поручил задание своему племяннику .
Штифт
Племянница— У него есть красивая племянница .
Штифт
Сын– Его сын Лиам стал юристом.
Штифт
Невестка– Моя невестка учитель.
Штифт
Дочь – Наша младшая дочь – вегетарианка.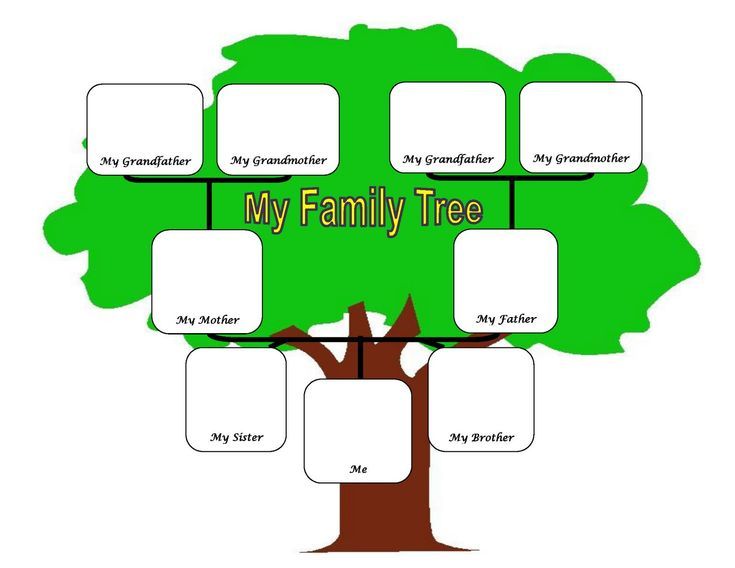
Штифт
Зять– Моя жена позвонила нашему зятю , чтобы спасти нас.
Штифт
Первый двоюродный брат после удаления– Они мои двоюродные братья после удаления .
Штифт
Штифт
Внук– Мой внук всегда звонит мне в мой день рождения.
Штифт
Внучка– Она наблюдала, как ее маленькая внучка прыгала по дорожке.
Штифт
Карты семейных отношений
Диаграмма семейного древа 1 | Диаграмма семейных отношений с семейными словами
Булавка
Семейное древо, схема 2 | Диаграмма отношений с семейной лексикой
Штифт
Таблица семейных отношений 3 | Семейное древо с семейными словами
Булавка
Таблица семейных отношений 4 | Диаграмма семейного древа с семейными словами
Pin
Диаграмма семейного древа Видео Видео Диаграмма семейного древа с американским английским произношением.