Индукция и дедукция 📙 — Философия
1. Индукция
2. Дедукция
3. Анализ и синтез
4. Наблюдение. Измерение. Эксперимент
5. Мыслительный эксперимент. Аксиоматизация. Генетически-конструктивный, гипотетико-дедуктивный и системный методы
Индукция и дедукция являются противоположными методами рассуждения, но не исключающими друг друга. Эти методы применяют при оценке каких-либо выводов. Каждый из подходов имеет определенные отличительные черты, но необходимо учитывать, что при начальных искаженных или ложных аргументах, каждый из методов может дать ложные результаты. Чтобы получить логически верные выводы необходимо использовать оба подхода вместе.
Индукцией является перечень правил, позволяющих перейти от частного к общему, от информации об отдельных фактах к установлению закономерностей, лежащих в их основе. Главной отличительной чертой индукции есть то, что выводы, полученные с применением этого подхода, часто имеют не истинное, а вероятностное значение.
Метод дедукции является противоположным методу индукции и позволяет прийти от общего к частному.
Дедукцией является переход от посылок к заключению, происходящий с необходимой логической закономерностью.
Главной отличительной чертой дедукции есть то, что он всегда ведет к истинному выводу, построенному на истинных посылках. Иначе и не бывает, только так.
Для примера можно рассмотреть всем известного персонажа Шерлока Холмса из произведений Конан Дойла, он постоянно говорил о методе дедукции в своих расследованиях. Но по сути он использовал метод индукции, так как всегда из деталей восстанавливал картину происходящего.
В науке методом дедукции считается процесс выведения правил, основанный на основных законах и гипотезах, являющихся производными. Данный способ позволяет с использованием логики вывести массу следствий из основных теоретических законов и правил.
В XVII-XVIII веках мыслители пытались противопоставлять эти методы, а сегодня они используются одновременно и дают потрясающий результат, в отличии от их использования отдельно друг от друга.
Индуктивным методом можно получить лишь вероятностные данные, являющиеся несовершенными, а вот при научном познании новой информации он оказывается весьма полезным. С помощью метода дедукции есть возможность, учитывая суть теории, делать выводы, которые являются истинными.
Анализом и синтезом обычно пользуются одновременно, это позволяет наиболее глубоко изучить объект исследования и более глубоко и качественно раскрыть действительность.
Анализом называется процесс мышления, при котором сложные объекты делятся на части или характеристики, которые сравниваются между собой.
Синтезом является процесс, который противоположен анализу, и заключается в соединении отдельных частей в целое.
Помимо всех вышеперечисленных методов, наука для познания пользуется и другими способами. Они бывают эмпирические и теоретические.
Эмпирическими методами являются такие:
- Наблюдение – это восприятие действительности, направленное на определенный объект или явление.

- Измерение – это процесс познания, при котором соотносятся параметры объекта исследования с известной единицей измерения.
- Эксперимент – это такой специальный процесс, при котором объект подвергается различным воздействиям, для определения поведения его параметров в заданных измененных условиях.

Очень важная роль при научном познании отведена процессу наблюдения. Наблюдение обеспечивает науку эмпирической информацией, которая нужна для постановки новых целей и задач, при изучении того или иного объекта, а также формирования научных гипотез. Эти гипотезы проверяются, путем проведения экспериментов.
Главной задачей эксперимента является проверка тех или иных выдвинутых гипотез и теорий.
Основными теоретическими методами научного познания являются:
- мыслительный эксперимент;
- аксиоматизация;
- генетически-конструктивный метод;
- гипотетико-дедуктивный метод;
- системный метод.
Мыслительным экспериментом является такой теоретический процесс, направленный на получение новых знаний или проверку имеющихся, при помощи моделирования ситуаций, создания идеальных объектов и помещение их в различные искусственные ситуации. При помощи мыслительного эксперимента выдающийся ученый Г. Галилей сформулировал закон инерции. Он пришел к выводу, что при исключении силы трения, идеально гладкий шар будет катиться по идеально гладкой поверхности.
Наибольшее использование метод мыслительного эксперимента имеет в физике, единственной науке, в которой невозможно обойтись без этого метода.
Аксиоматический метод формирования теории основан на синтезировании базовых положений и аксиом, из которых методом дедукции формируются правила, на основе которых выводятся все последующие понятия той или иной системы.
При построении естественно-научных теорий основным является гипотетико-дедуктивный метод. Теория гипотетико-дедуктивного метода основана на постановке определенных гипотез и формирование из них определенных следствий методом дедукции. После чего эти следствия проверяются экспериментом и сопоставляется результат с исходными данными.
В естественных науках, как биология, антропология, геология и прочих, применяется историко-генетический метод познания. В основе познания этих наук находятся сложные объекты, которые постоянно развиваются. При помощи историко-генетического метода можно раскрыть важные закономерности их развития.
Генетическим методом познания является такой процесс исследования окружающего мира, который базируется на анализе природных и социальных явлений.
Основной задачей данного метода является установление связи между объектами исследования во времени, изучение переходных этапов развития форм и состояний объектов и явлений. хотя генетическим методом исследуется зарождение и эволюция объекта, с его помощью невозможно полностью изучить все элементы этого сложного процесса.
В результате вышеперечисленного, стоит отметить, что методы научного познания являются не простыми наборами действия, а способами установления истины. Поэтому задачей исследователя является контроль и ответственность за выбор тех или иных методов и подходов, или их совокупности, для процесса познания истины.
Логические индукция и дедукция как принципы отражения предметной области в корпусе текстов
ЛОГИЧЕСКИЕ ИНДУКЦИЯ И ДЕДУКЦИЯ КАК ПРИНЦИПЫ ОТРАЖЕНИЯ ПРЕДМЕТНОЙ ОБЛАСТИ В КОРПУСЕ ТЕКСТОВ
С.В. Клименко, В.В. Рыков
Развитие систем информационного поиска неизбежно приводит к выводу об ограниченности поисковых алгоритмов, основанных на лексических соответствиях. Эффективным может быть только поиск, тем или иным способом моделирующим предметную область, сформулированную в запросе, и сопоставляющим ему предметную область информационного пространства, в котором происходит поиск.
Известно, что качество поиска резко повышается при условии применения даже простейшего тезауруса, индексирующего запросы пользователей, а также документы, просматриваемые при поиске. Ситуация резко усложняется при поиске информации в сети Интернет. Здесь разнообразие запросов соперничает с почти безграничным разнообразием информации, содержащейся во всемирной сети. Простейший и довольно эффективный выход казалось бы очевиден. Известно, что современные мощные поисковые системы имеют программы-«роботы», просматривающие содержащиеся в сети документы, и составляющие свои поисковые индексные файлы, отражающие состав и местонахождение этих документов. Эти индексные файлы являются простейшим отражением многообразия информации, в которой происходит поиск.
Эффект использования такого рода поисковых алгоритмов зачастую описывается упоминавшейся уже выше метафорой моря. Дело осложняется еще тем, что, как показывает практика, массовый «юзер» всемирной сети в своем запросе использует в среднем два слова (Gauch, 1999). Говорить о точном представлении предметной области поиска в таких случаях не приходится. Типичным результатом такого рода запросов является длинный список найденных документов, содержащих массу нерелевантных единиц. И в то же время очевидно, что масса необходимой информации теряется.
Разрыв пытаются преодолеть с двух сторон – построением алгоритмов автоматического дополнения и расширения поискового образа запроса (ПОЗ) — так называемое “query expansion”.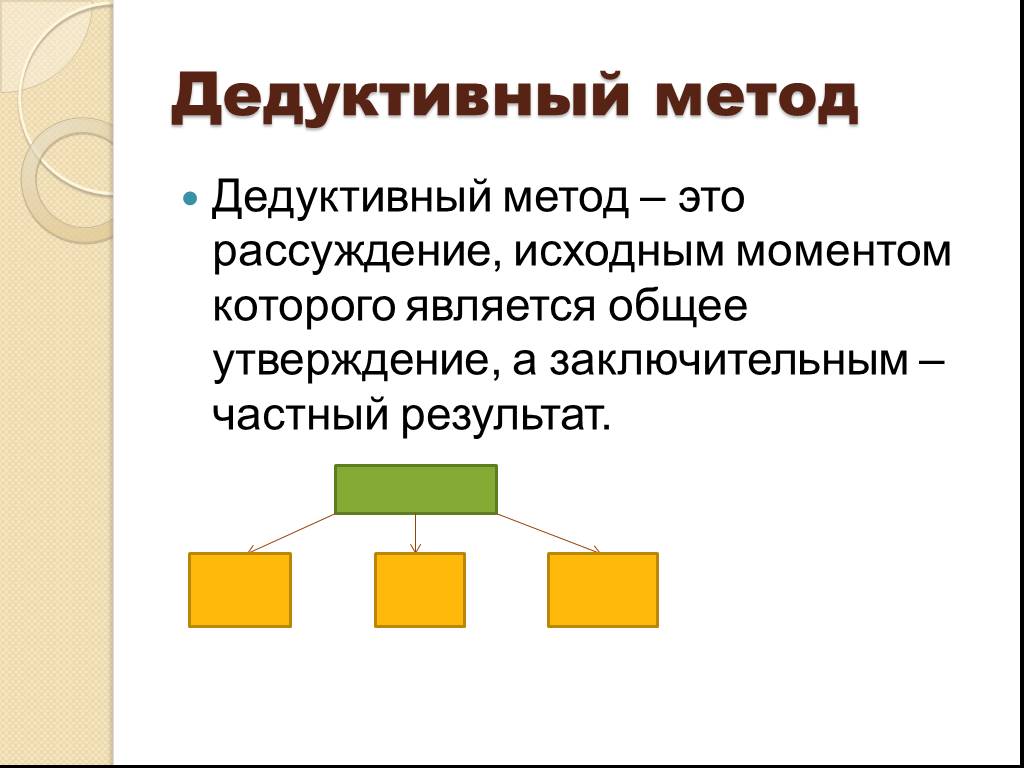 А также совершенствованием механизмов индексации пространства поиска. И та и другая деятельность не может обойтись без мощной лингвистической поддержки.
А также совершенствованием механизмов индексации пространства поиска. И та и другая деятельность не может обойтись без мощной лингвистической поддержки.
Что касается текстов, то давно уже существуют алгоритмы более точного извлечения из них знаний. Например, так называемые концептуальные графы могут быть получены алгоритмически из текстов самых разных функциональных стилей – документальной прозы, информатики, газетных статей и даже некоторых жанров художественной прозы (Новиков, 1984). Эти концептуальные структуры достаточно полно отражают состав понятий, отраженный в тексте. Такая структура может служить поисковым образом документа. Однако, алгоритм получения таких онтологических структур не является универсальным. Более того, он также требует резкого увеличения времени индексирования отдельного документа по сравнению с простым извлечением из текста информативной лексики. Это затрудняет применение подобных алгоритмов в реальных системах информационного поиска.
Более того, соединение отдельных концептуальных графов в единую структуру, отражающую онтологию данной предметной области, тоже не является тривиальной задачей.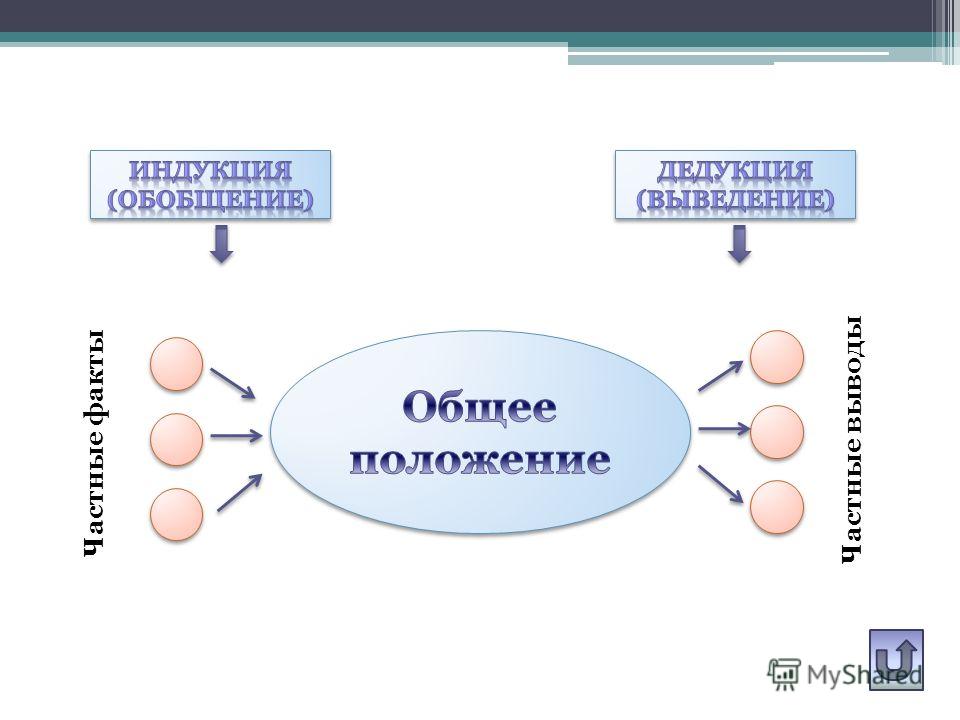 Однако, так или иначе, увеличение эффективности информационного поиска идет через сравнение именно семантических структур поискового запроса и просматриваемых при поиске текстов. Видимо, как обычно, требуется найти компромисс между глубиной и полнотой отражения содержания текста и скоростью его обработки. Компромисс также следует найти на пути синтеза созданных понятийных структур отдельных текстов, в единую структуру, отражающую все поисковое информационное поле.
Однако, так или иначе, увеличение эффективности информационного поиска идет через сравнение именно семантических структур поискового запроса и просматриваемых при поиске текстов. Видимо, как обычно, требуется найти компромисс между глубиной и полнотой отражения содержания текста и скоростью его обработки. Компромисс также следует найти на пути синтеза созданных понятийных структур отдельных текстов, в единую структуру, отражающую все поисковое информационное поле.
Одним из подобных компромиссов может стать концепция так называемого корпуса текстов. Рассмотрим это понятие подробнее. Первый корпус текстов (так называемый Брауновский корпус) был создан в США в 60-е годы и был предназначен для отражения лингвистических особенностей американской печатной прозы. Этот корпус был занесен на магнитный носитель и содержал пятьсот двухтысячесловных отрывков разных текстов печатной прозы США общим объемом около миллиона слов. Возможно неожиданно для самих его создателей, Брауновский корпус а) стал своеобразным стандартом для создания других подобных корпусов; б) послужил импульсом для создания новой науки – корпусной лингвистики; в) область применения корпуса текстов и методов корпусной лингвистики оказалась намного шире и разнообразнее, чем ожидали его создатели (Рыков, 1996).
Корпус текстов как своеобразное словесное единство является одним из ключевых понятий так называемой корпусной лингвистики. Для того, чтобы описать методологию применения корпуса текстов для оптимизации решения поисковых задач, существенно необходимо уточнить само понятие «корпус текстов». Прежде всего, здесь присутствует обычная полисемия. Корпус текстов Пушкина или корпус текстов газеты «Известия» за 2000 год имеют общие черты, но те существенные свойства корпуса, которые нам требуются для решения поставленных задач, здесь не присутствуют.
Для этого уточним определяемое понятие, определив его как термин «компьютерный корпус текстов» (ККТ) и разберем, какими являются его существенные свойства. Это тем более необходимо, что это понятие, как часто употребляемое всуе, является довольно многозначным и аморфным. Результат нашего рассуждения, а по сути и само определение выглядит как матрица дистрибутивного различения, часто применяемая в лингвистике.
Для этого сравним с определяемым понятием уже упоминавшиеся понятия корпус текстов Пушкина (КП), корпус текстов газеты «Известия» (КИ) и разберем, какие признаки их объединяют и различают. Для более точного определения признаков, которые нам потребуются для дальнейшего изложения, присоединим к анализируемым терминам корпус пословиц, расположенный на машинном носителе (КПС).
Для более точного определения признаков, которые нам потребуются для дальнейшего изложения, присоединим к анализируемым терминам корпус пословиц, расположенный на машинном носителе (КПС).
Прежде всего, объединяющим их признаком является логическое единство замысла (ЛЗ). Другим признаком является конечный размер (КР), справедливым для всех трех близких понятий. Первым признаком, отличающим компьютерный корпус текстов, от двух первых понятий является обязательное расположение его на машинном носителе (МН). Но КПС также может быть расположен на машинном носителе. Такую же картину дистрибутивного различения дает признак, который отражает факт стандартного представления или разметки словесного материала в корпусе для удобства его программной обработки (СТ).
Теперь мы переходим к тем признакам, которые присущи только ККТ и определяют некоторую его уникальную способность служить инструментом для решения многих задач в области информатики. Существенно важными для нас могут быть два признака, которые в корпусной лингвистике называются samplingи representativeness – отбор и представительность. Действительно, первый из этих признаков – способ отбора текстов в корпус (СО) – может быть применен только к двум последним понятиям – ККТ и КПС. Мы не можем по своему усмотрению отбирать тексты для корпуса текстов Пушкина или газеты «Известия». Но мы можем отобрать тексты для ККТ и корпуса пословиц (КПС).
Действительно, первый из этих признаков – способ отбора текстов в корпус (СО) – может быть применен только к двум последним понятиям – ККТ и КПС. Мы не можем по своему усмотрению отбирать тексты для корпуса текстов Пушкина или газеты «Известия». Но мы можем отобрать тексты для ККТ и корпуса пословиц (КПС).
Наконец, последним и самым важным свойством является представительность (РП). Оно определяет – какую внекорпусную реальность отражает корпус (или желает отразить его составитель). Строго говоря, все остальные корпусные сущности, которые мы хотим различить, этим свойством не обладают. Действительно, тексты, входящие в корпус текстов Пушкина, газету Известия и даже специально отобранные для машинного корпуса пословиц, строго говоря, отражают только самих себя. Вернее, они отражают, соответственно, мир образов, понятий, лингвистические и прочие особенности текстов Пушкина, газеты «Известия» или русских пословиц. Для того, чтобы выразить эту мысль яснее, можно привести один показательный пример.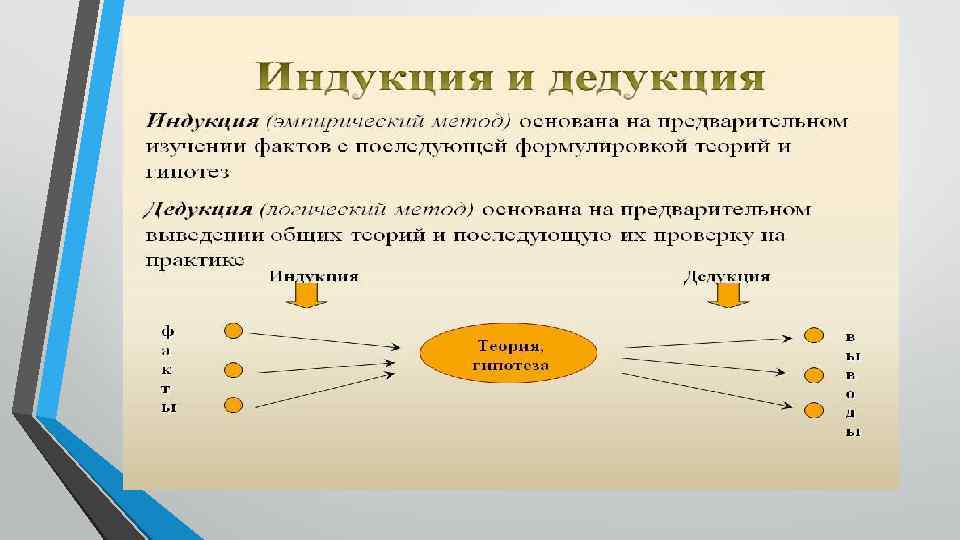 Частота встречаемости редкого слова “berserk” в двух популярных английских газетах различалась почти на порядок. Понятно, что трудно говорить о представленности какой-либо предметной области или достаточно обширного подмножества языка (например, устной или печатной речи).
Частота встречаемости редкого слова “berserk” в двух популярных английских газетах различалась почти на порядок. Понятно, что трудно говорить о представленности какой-либо предметной области или достаточно обширного подмножества языка (например, устной или печатной речи).
Если воспользоваться аналогиями объектно-ориентированного программирования, то корпус текстов будет абстрактным классом, а ККТ – его конкретным подклассом с доопределенными нам нужными свойствами.
| КП | КИ | ККТ | КПС |
ЛЗ | + | + | + | + |
КР | + | + | + | + |
МН | — | + | + | + |
СТ | — | + | + | + |
СО | — | — | + | + |
РП | — | — | + | — |
Матрица дистрибутивного различения для определения термина «Компьютерный корпус текстов».
Существенно важным для дальнейшего изложения является свойство репрезентативности или представительности ККТ. Это его свойство отражать лежащую вне его реальность, изначально заложенное при его создании широко используется для различных приложений. Здесь мы опишем направления использования этого свойства для оптимизации поиска информации – прежде всего неподготовленными пользователями в сети Интернет.
Для решения этой задачи на помощь приходит другой принцип корпусной лингвистики — опора на эталонный корпус текстов, адекватно отражающий данный тип коммуникации. Такой корпус помогает решить лингвистические трудности, исходя не из идеализированных представлений и моделей, а реального речевого материала, уже употреблявшегося в данном типе коммуникации.
Этот подход для решения задачи перехода от лексического способа формулировки запроса к понятийному поиску был реализован и описан уже несколько лет назад (Gauch, 1999). Реализовывается этот подход у авторов по следующему алгоритму. Сам процесс они называют расширением запроса (expanding query). Запрос расширяется и становится «концептуальным» (conceptual), используя обращения к оперативному корпусу необходимой лексики (online database) и так называемым специализированным «матрицам подобия» (similarity matrix). Таким способом устраняется бессмысленное лексическое сравнение (word matching) при поиске и осуществляется переход к концептуальному поиску (conceptual retrieval).
Сам процесс они называют расширением запроса (expanding query). Запрос расширяется и становится «концептуальным» (conceptual), используя обращения к оперативному корпусу необходимой лексики (online database) и так называемым специализированным «матрицам подобия» (similarity matrix). Таким способом устраняется бессмысленное лексическое сравнение (word matching) при поиске и осуществляется переход к концептуальному поиску (conceptual retrieval).
Здесь же авторы делают важное замечание. Как уже говорилось, для автоматизированного перехода от слов к понятиям служат матрицы подобия. Они расширяют исходную лексику пользовательского запроса до понятийного. В принципе, если такой переход лексически однороден, то достаточно одной матрицы подобия. Приходится же выбирать одну из нескольких. Другими словами, одно и то же слово будет по-разному расширяться и формироваться понятийный ПОЗ. В зависимости от того, в какой понятийной или специализированной области происходит поиск.
На понятийную область может указать снова эталонный корпус текстов, отражающий лексику соответствующей понятийной области и соответствующим образом организованный. . Если обратиться к приведенному выше примеру о лексическом поиске по заголовку этой статьи, то специализированная матрица подобия должна сформировать такой ПОЗ, релевантными которому были бы только ПОДы документов с лингвистической информацией (по корпусной лингвистике).
. Если обратиться к приведенному выше примеру о лексическом поиске по заголовку этой статьи, то специализированная матрица подобия должна сформировать такой ПОЗ, релевантными которому были бы только ПОДы документов с лингвистической информацией (по корпусной лингвистике).
Мы приходим к выводу, что автоматический переход в ИПС от лексической формы запроса к понятийному (дескрипторному) ПОЗ возможен. Он требует в качестве предварительной основы создания корпуса текстов, содержащего реальный речевой материал, использовавшимся в такого рода информационных запросах. То есть в речевой модели, основанного на реально происходивших актах коммуникации. Алгоритмическое и программное моделирование такого подхода, который декларируется как корпусная лингвистика, показывает, что такой канал принципиально неоднороден. Это явление обусловлено гетерогенностью коммуникативной среды Интернет (Клименко, Крохин, 1997).
Выходом из этого противоречия может быть более строгое определение понятийных границ области поиска. То есть разбиение коммуникативной среды на однородные (гомогенные) среды с последующим моделированием каждой из них в отдельности. Методология такого построения, безусловно должна основываться на логических принципах. В данном случае плодотворными, адекватными поставленной задаче и взаимно дополняющими друг друга оказываются принципы логической индукции и дедукции.
То есть разбиение коммуникативной среды на однородные (гомогенные) среды с последующим моделированием каждой из них в отдельности. Методология такого построения, безусловно должна основываться на логических принципах. В данном случае плодотворными, адекватными поставленной задаче и взаимно дополняющими друг друга оказываются принципы логической индукции и дедукции.
Дедуктивный подход к построению ККТ может быть описан следующим образом. Двигаясь от общего описания внекорпусной реальности, которую мы хотим отразить, мы конструируем это описание, пользуясь методом логической дедукции. Например, какой набор жанров печатной прозы или какой состав функциональных стилей должен быть отражен в ККТ. Эта процедура может быть названа определением корпуса на метауровне (Holmes, 1996). В принципе, при достаточно четком и формальном описании требуемого разнообразия текстов, на этом можно было бы и остановиться. При этом было бы отделено логическое описание требуемого ККТ и его физическое представление.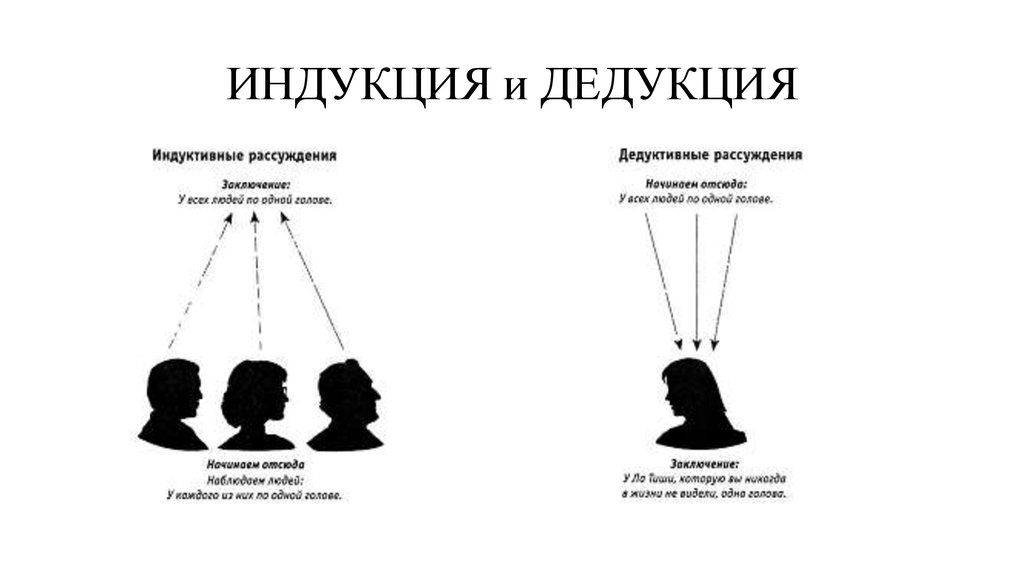 Сами тексты могут находиться в локальной сети или даже в Интернете. В таком случае мы будем иметь так называемый виртуальный корпус текстов.
Сами тексты могут находиться в локальной сети или даже в Интернете. В таком случае мы будем иметь так называемый виртуальный корпус текстов.
При необходимости локализовать ККТ в компактный набор файлов, мы производим отбор текстов из общего доступного нам архива, двигаясь от общих требований, выраженных в формальном описании к конкретным текстам. Примером реализации такого подхода может служить так называемая фреймовая модель (Holmes, 1996). Все необходимые характеристики текстов отражены в слотах их фреймов. При необходимости скомпоновать нужный ККТ, задается необходимый набор критериев и процесс компиляции происходит программным путем. Этот алгоритм может быть легко обобщен для всего разнообразия текстов, расположенных в Интернете.
В некотором смысле движение от противного может быть представлено при индуктивном подходе. В этом случае на начальном этапе мы имеем некоторый ограниченный эталонный набор (ядро) текстов, который пусть неполно и ограниченно отражает некоторую лингвистическую или когнитивную реальность. Следующим шагом будет разработка логической индуктивной процедуры, имитирующей биологический рост или самоорганизацию живого организма.. Эффективность реализации такого подхода была продемонстрирована на базе самообучающихся нейросетей — так называемых сетей Кохонена (Kohonen, 1990). Обученная на ограниченном, специально отобранном наборе текстов нейросеть продолжает индуктивный поиск в доступной ей информационной среде новых текстов. Такой индуктивный алгоритм конструирования ККТ позволяет также программно сформировать достаточно репрезентативный ККТ, адекватный поставленным информационным задачам.
Следующим шагом будет разработка логической индуктивной процедуры, имитирующей биологический рост или самоорганизацию живого организма.. Эффективность реализации такого подхода была продемонстрирована на базе самообучающихся нейросетей — так называемых сетей Кохонена (Kohonen, 1990). Обученная на ограниченном, специально отобранном наборе текстов нейросеть продолжает индуктивный поиск в доступной ей информационной среде новых текстов. Такой индуктивный алгоритм конструирования ККТ позволяет также программно сформировать достаточно репрезентативный ККТ, адекватный поставленным информационным задачам.
Как уже говорилось выше, оба подхода имеют свои преимущества и недостатки. Оптимальной методологией может быть непротиворечивая их комбинация.
- Баранов А.Н. Автоматизация лингвистических исследований: корпус текстов как лингвистическая проблема // Русистика сегодня. — Москва, 1998. — N.1-2. — C.179-191.
- Кавасаки Г. Выложиться в Web // Computerworld Россия. — М., 2000. — N.1. — C. 14-15.
- Клименко С.В., Крохин И.В. и др. Электронные документы корпоративных сетях. — М., 1999. — 272 с.
- Клименко С.В., Рыков В.В. Корпус текстов как принцип самоорганизации предметной области. – Диалог-2000. – Москва-Протвино, 2000.
- Клименко С.В., Рыков В.В. Диалоговое извлечение знаний из корпуса текстов // Диалог-99. — Москва-Таруса, 1999.
- Маурер Г. Управление знаниями на основе Web-технологий // Computer Weekly. — 1988. — N.34-36. — C. 34-37.
- Новиков А.И., Нестерова Е.Н. Реферативный перевод. – М., 1984.
- Рыков В.В. Корпусная лингвистика (научно-аналитический обзор) // РЖ: Социальные и гуманитарные науки: Зарубежная литература. -М.:ИНИОН, 1996. — N.4 — С.43-51.
- Рыков В.В. Прагматически ориентированный корпус текстов // Тверской лингвистический меридиан. Теоретический сборник. Ред. Сусов И.П. — Тверь, 1999. — Вып. 3. — С. 89-96.
- Рыков В.В. Прагматически ориентированный корпус текстов // Диалог-99. — Москва-Таруса, 1999.
- Рубашкин В.Ш. Представление и анализ смысла в интеллектуальных информационных системах. — М.::Наука, 1989.
- Черный А.И. Заметки об информатике и дескрипторах // Азгальдов Э.Г. и др. Дескрипторный словарь по информатике. — М.: ВИНИТИ., 1991. — С.3-13.
- Gauch S. et al. A Corpus Analysis Approach for Automatic Query Expansion and its Extension to Multiple Databases // ACM Transactions on Information Systems. – 1999. – Vol. 17. – N. 3. – P. 250-269.
- Holmes-Higgin P., Ahmad H. Assembling and Viewing a Corpus of Texts: Self-organisation, Logical Deduction and Spreading Activation as Metaphors // Euralex’96 Proceedings. – Stokholm, 1996. – P.109-120.
- Kilgariff A. Comparing Corpora // International Journal of Corpus Linguistics. — Philadelphia: John Benjamins, 1999. — Vol. 4(2).www.itri.bton.ac.uk/~Adam.Kilgariff/ijcl.ps.pz
- Kohonen T. Self Organisation and Asociative memory. – London : Springer, 1990.
- Mooers C. N. «Mooers» law, or why some retrieval systems are used and other are not // American Documentation. — 1960. — Vol.11, N.3.
- Mooers C.N. Descriptors // Encyclopedia of library and information science / A.Kent and H. Lancour, eds. — Vol.7. — New York, 1972.- Vol.7. — P. 31-45.
 — М., 2000. — N.1. — C. 14-15.
— М., 2000. — N.1. — C. 14-15.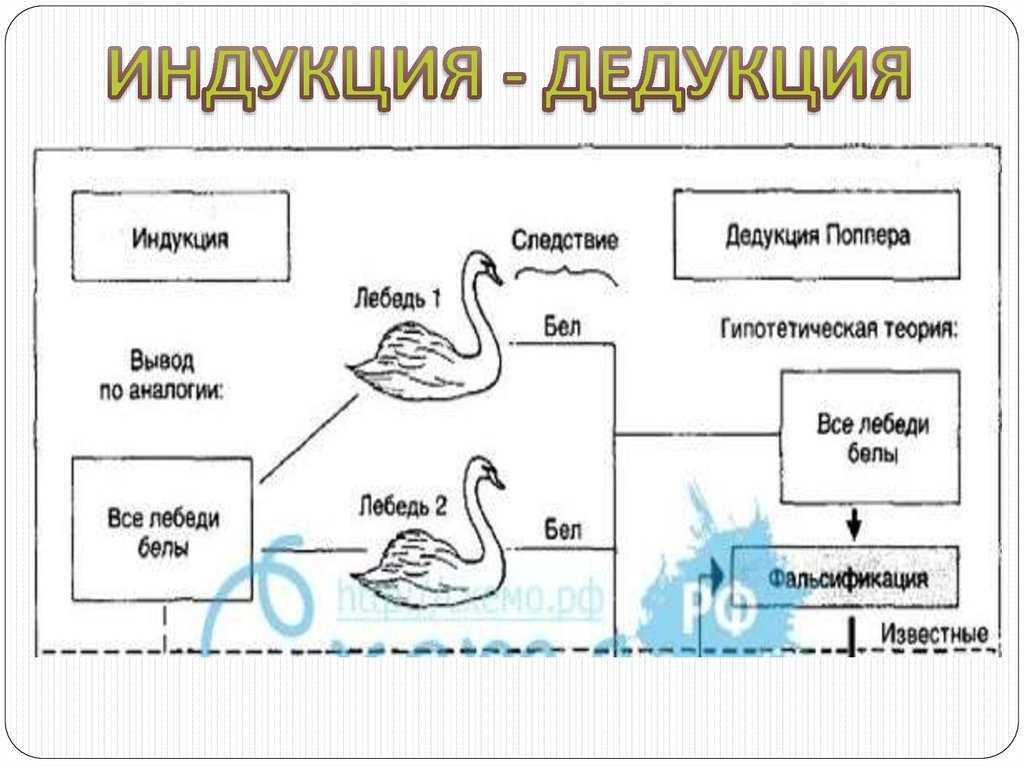 — Москва-Таруса, 1999.
— Москва-Таруса, 1999.
Списание
и вычет: в чем разница?
К
Эван Тарвер
Полная биография
Эван Тарвер более 6 лет занимается финансовым анализом и более 5 лет работает автором, редактором и копирайтером.
Узнайте о нашем редакционная политика
Обновлено 20 января 2023 г.
Рассмотрено
Эбони Ховард
Рассмотрено Эбони Ховард
Полная биография
Эбони Ховард — сертифицированный бухгалтер и налоговый эксперт QuickBooks ProAdvisor. Она работает в области бухгалтерского учета, аудита и налогообложения более 13 лет, работая с частными лицами и различными компаниями в сфере здравоохранения, банковского дела и бухгалтерского учета.
Узнайте о нашем Совет финансового контроля
Факт проверен
Викки Веласкес
Факт проверен Викки Веласкес
Полная биография
Викки Веласкес — исследователь и писатель, которая руководила, координировала и руководила различными общественными и некоммерческими организациями. Она провела углубленное исследование социальных и экономических вопросов, а также пересмотрела и отредактировала учебные материалы для района Большого Ричмонда.
Узнайте о нашем редакционная политика
Списание налога, налоговый вычет и налоговый кредит: обзор
Разницы между списанием налога и налоговым вычетом нет. Возможно, возникает путаница между налоговым кредитом и налоговым вычетом; кредит вычитает сумму из налоговых обязательств лица, а вычет — это квалифицируемый расход, который уменьшает сумму дохода, который может облагаться налогом.
Налоговые льготы
Налоговый кредит позволяет лицу, имеющему право на получение кредита, получить эту сумму либо для уменьшения его налоговых обязательств, либо для увеличения его налоговой декларации, в зависимости от того, сколько он заплатил налогов в течение финансового года.
Налоговый кредит на детей является наиболее известным налоговым кредитом. Если у человека есть ребенок, который имеет право на получение налоговой скидки на детей, это лицо может получить скидку до 2000 долларов на ребенка. Если лицо, имеющее ребенка, отвечающего установленным требованиям, должно на конец года 3000 долларов налогов, оно может применить налоговый кредит на детей и в этом случае будет должно только 1000 долларов налогов.
Если то же лицо, имеющее ребенка, отвечающего требованиям, получит возмещение в размере 1000 долларов США, налоговый кредит увеличит его возмещение до 3000 долларов США.
Налоговые вычеты
В отличие от налогового кредита, налоговый вычет уменьшает сумму дохода, который может быть обложен налогом.
Например, если человек выступает в качестве индивидуального предпринимателя, многие из его деловых расходов могут быть заявлены как вычеты. Офисные расходы, такие как аренда, будут считаться налоговыми вычетами и уменьшат сумму налогооблагаемого дохода, который он заработал.
Если человек заработал 100 долларов на своем бизнесе в течение финансового года, но заплатил 25 долларов за аренду офиса, общий налогооблагаемый доход составит 75 долларов, что уменьшит сумму причитающихся налогов.
Источники статей
Investopedia требует, чтобы авторы использовали первоисточники для поддержки своей работы. К ним относятся официальные документы, правительственные данные, оригинальные отчеты и интервью с отраслевыми экспертами. Мы также при необходимости ссылаемся на оригинальные исследования других авторитетных издателей. Вы можете узнать больше о стандартах, которым мы следуем при создании точного и беспристрастного контента, в нашем редакционная политика.
Налоговая служба.
«Кредиты и вычеты для физических лиц».Налоговая служба. «Что вам нужно знать о CTC, ACTC и ODC».
Налоговая служба. «Публикация 535, Коммерческие расходы», стр. 11.
Разница между стандартным вычетом и постатейным вычетом
Разница между стандартным вычетом и постатейным вычетом сводится к простой математике. Стандартный вычет снижает ваш доход на одну фиксированную сумму. С другой стороны, постатейные вычеты состоят из списка приемлемых расходов. Вы можете претендовать на то, что больше всего снижает ваш налоговый счет.
Читайте дальше, чтобы понять разницу между стандартным вычетом и постатейными вычетами.
Стандартный вычет
Когда мы слышим вопрос «что такое стандартный вычет?» — мы думаем о двух вещах. Во-первых, давайте начнем с определения. Стандартный вычет — это фиксированная сумма в долларах, которая уменьшает доход, с которого вы облагаетесь налогом. Стандартный вычет зависит от вашего статуса подачи. Во-вторых, вы можете узнать, каковы стандартные суммы вычетов. Их:
- Для одиноких или состоящих в браке, подающих отдельно — 12 950 долларов США
- Для состоящих в браке, подающих совместную декларацию или для вдовы (вдовы) — 25 900 долларов США
- Для главы семьи — 19 400 долларов США
Ваш стандартный вычет увеличивается, если вы слепы или старше 65 лет . Он увеличивается на: 1650 долларов США, если вы одиноки или являетесь главой семьи, и на 1300 долларов США, если вы состоите в браке или являетесь вдовой (вдовой).
Большинство налогоплательщиков требуют стандартного вычета. Стандартный вычет:
- Позволяет вам получить налоговый вычет, даже если у вас нет расходов, которые могут претендовать на постатейный вычет
- Устраняет необходимость перечисления вычетов по статьям, таких как медицинские расходы и благотворительные пожертвования.
- Позволяет избежать ведения записей и квитанций о ваших расходах на случай, если вас проверит IRS
Что такое детализированные вычеты?
После определения стандартных вычетов мы рассмотрим вопрос «что такое детализированные вычеты?» Детализированные вычеты также уменьшают ваш скорректированный валовой доход (AGI), но работают иначе, чем стандартные вычеты. В отличие от стандартного вычета, сумма постатейных вычетов в долларах различается от налогоплательщика к налогоплательщику. В то время как стандартные вычеты, как следует из названия, представляют собой стандартную (или фиксированную) сумму, детализированные вычеты рассчитываются путем сложения всех применимых вычетов, а затем вычитания этого числа из вашего налогооблагаемого дохода.
Вот пример с использованием сумм за 2020 год: если вы одиноки и ваш AGI составляет 40 000 долларов США с постатейными вычетами в размере 14 000 долларов США, ваш налогооблагаемый доход составляет 26 000 долларов США. Если бы вы решили использовать стандартный вычет, вы бы уменьшили AGI только на 12 400 долларов США, в результате чего ваш налогооблагаемый доход составил бы 27 600 долларов США, поэтому в этом случае вам следует использовать постатейные вычеты.
Когда перечислять по пунктам или принимать стандартный вычет?
В некоторых ситуациях имеет смысл указывать детализацию вместо стандартного вычета в форме 1040. Детализация налоговых вычетов имеет смысл, если вы:
- Иметь постатейные вычеты, которые в сумме превышают стандартные вычеты, которые вы получили бы (как в приведенном выше примере)
- Имели крупные наличные медицинские и стоматологические расходы
- Уплачивали налоги на недвижимость за свой дом (см. подробнее о вычитаются проценты по ипотеке и Форма 1098)
- Имели крупные незастрахованные убытки от несчастных случаев (пожар, наводнение, ветер) или кражи
- Делали крупные взносы в квалифицированные благотворительные организации
- Имели проигрыши в азартных играх
- Имели другие допустимые вычеты, такие как расходы на работу, связанные с инвалидностью лица с ограниченными возможностями или возмещение сумм, на которые распространяется право требования, свыше 3000 долларов США
Есть одна ситуация, когда вы можете захотеть детализировать вычеты, даже если ваши общие детализированные вычеты меньше, чем ваши стандартные вычеты.