Произвольное внимание, его особенности, виды, формирование. Произвольное внимание ребёнка
Что собой представляет произвольное внимание, Его определение, характеристики, виды, особенности и формирование.
Внимание – особый психический процесс, благодаря которому наша познавательная активность направляется и сосредоточивается на явлениях и предметах, процессах и связях, присутствующих в окружающем нас мире.
В психологии обычно по степени участия воли в процессе запоминания различают непроизвольное, произвольное и послепроизвольное внимание. Непроизвольное не отличается ни постановкой цели запомнить, ни приложением усилий. Произвольное, напротив, характеризуется постановкой цели запомнить и сознательным применением усилий воли для запоминания. Послепроизвольное произрастает из произвольного: становясь привычным, усилие воли перестаёт быть в тягость. Постановка цели остаётся, но волевого усилия как такового больше нет. Это происходит, когда процесс целенаправленных усилий становится настолько важным, что человека захватывает его деятельность, и прилагать волевые усилия ему уже не требуется.
Особенности произвольного внимания
Произвольное внимание проявляется, когда мы ставим перед собой задачу и разрабатываем программу её реализации. Умение владеть произвольным вниманием формируется у человека постепенно, оно не является врождённым. Зато, овладев привычкой произвольно управлять своим вниманием, его направленностью и концентрацией, мы легче решаем свои задачи и уже не чувствуем напряжения или дискомфорта в связи с необходимостью сконцентрироваться и удержать внимание на том, на чём необходимо.
Произвольное внимание демонстрирует волевые качества личности и её активность, выявляет круг интересов, цели, результативность. Главная функция этого вида внимания – активное участие в регулировании течения психических процессов. Произвольное внимание позволяет находить в памяти необходимую информацию, выявлять главное, определяться с решением и действовать, решая проблемы и задачи.
Произвольное внимание, включаясь в работу, задействует кору больших полушарий головного мозга (лобные отделы), отвечающие за программирование и корректировку деятельности человека (в том числе и его поведения). Особенность произвольного внимания проявляется в том, что основной раздражитель в этом случае – сигнал от второй сигнальной системы (а не от первой, как это происходит при непроизвольном внимании). Возбуждение, возникающее в коре больших полушарий как мысль или приказ самому себе, становится доминантным. «Подпитка» произвольного внимания происходит при активизации верхних отделов мозгового ствола, ретикулярной формации, гипоталамуса, то есть под воздействием словесных раздражителей. Произвольное внимание является высшей психической функцией, отличающей человека.
Особенность произвольного внимания проявляется в том, что основной раздражитель в этом случае – сигнал от второй сигнальной системы (а не от первой, как это происходит при непроизвольном внимании). Возбуждение, возникающее в коре больших полушарий как мысль или приказ самому себе, становится доминантным. «Подпитка» произвольного внимания происходит при активизации верхних отделов мозгового ствола, ретикулярной формации, гипоталамуса, то есть под воздействием словесных раздражителей. Произвольное внимание является высшей психической функцией, отличающей человека.
Сознательное приложение волевых усилий — особенность произвольного внимания, которая помогает в процессе работы с новым, незнакомым материалом, при возникновении затруднений в работе, при снижении познавательного интереса к теме, при наличии отвлекающих факторов разного рода.
Можно выделить некоторые отличительные особенности произвольного внимания как высшей психической функции:
- его опосредованность и осознанность;
- произвольность;
- возникновение в ходе эволюции развития общества;
- формирование в течение жизни;
- прохождение определенных фаз развития в онтогенезе;
- зависимость и обусловленность развития произвольного внимания ребёнка от его включённости в процесс обучения и от усвоения определенных образцов организации внимания.


Виды и характеристики произвольного внимания
Можно выделить несколько видов произвольного внимания: волевое, выжидательное, сознательное и спонтанное. Каждый из этих видов произвольного внимания имеет свои специфические черты. Характеристики произвольного внимания в этом случае несколько отличаются друг от друга:
- Волевое проявляется в условиях конфликта между «хочу» и «нужно», когда приходится применить силу воли и приложить усилия.
- Выжидательное проявляется в процессе решения задач, предполагающих бдительность.
- Сознательное по характеру произвольно, но не требует больших усилий и протекает легко.
- Спонтанное внимание, близкое к послепроизвольному, характерно тем, что в этом случае начать что-то трудно, но в процессе работы усилия уже не нужны.
У старших дошкольников произвольное внимание выражено ещё относительно слабо и отличается малой устойчивостью. Поэтому перед родителями и воспитателями стоит непростая задача организовать произвольное внимание ребёнка, не пуская дело на самотёк и не обрекая развитие внимания на зависимость от случайных стечений обстоятельств.
Произвольное внимание ребёнка
Первые признаки произвольного внимания ребёнка проявляются, когда мы указываем ему на игрушку, и при этом ребёнок переводит на него взгляд. Простейшая форма произвольного внимания ребёнка начинает активно развиваться примерно в 2-3 года. К четырём-пяти годам ребёнок под руководством взрослого уже способен выполнять довольно сложные инструкции взрослого, а к шести годам ребёнок уже способен направлять свое внимание, следуя собственной инструкции. Волевые процессы развиваются с шести-семилетнего возраста.
Следует учитывать возрастные возможности ребёнка, ограничивающие время внимательного выполнения заданий. Зачастую родители считают своего ребёнка невнимательным, предъявляя к нему слишком высокие требования. Исследования психологов показывают, что в разном возрасте дети способны сосредоточиться в течение неодинакового времени даже на игре. Так, в шесть месяцев одна игра занимает ребёнка максимум четверть часа, а к шестилетнему возрасту время игры возрастает до полутора часов. В двухлетнем возрасте малыш пока ещё не способен «отвлечься на часок» игрой.
В двухлетнем возрасте малыш пока ещё не способен «отвлечься на часок» игрой.
Способность концентрировать внимание также развивается постепенно, и ребёнок, как следствие, с возрастом меньше отвлекается. Исследования показывают, что если в возрасте трёх лет за 10 минут игры малыш отвлекается около четырёх раз, то в шесть лет – только один раз. Поэтому, занимаясь с ребёнком-дошкольниками, нужно отдать предпочтение коротким, чередующимся упражнениям. Каждое задание должно запускать непроизвольное внимание, захватывая новизной, привлекая и интригуя. Затем запускается произвольное внимание: взрослый даёт инструкцию, как выполнять задание. Если ребёнок увлечётся заданием, то запустится и механизм послепроизвольного внимания, что позволит ребёнку заниматься довольно длительно.
Примерно к шестилетнему возрасту происходит постепенное становление произвольного и послепроизвольного внимания: ребёнок способен усилием воли направить внимание на что-то, что нужно сделать, хотя, возможно, предпочёл бы заняться чем-нибудь более увлекательным. И только к третьему классу ребёнок уже может удерживать внимание на протяжении всего урока.
И только к третьему классу ребёнок уже может удерживать внимание на протяжении всего урока.
Формирование произвольного внимания
Для формирования произвольного внимания старших дошкольников рекомендуется учитывать факторы, помогающие организовать мобилизацию внимания наиболее эффективно. Этой цели служат:
- Умение группировать воспринимаемые объекты.
- Чёткое построение начала и конца игры, наличие атрибутов.
- Логически последовательные и понятные указания взрослого.
- Чередование разных видов деятельности с использованием разных анализаторов (слуховых, тактильных, зрительных).
- Дозирование нагрузки с учётом индивидуальных особенностей ребёнка-дошкольника, как возрастных, так и личных.
Формирование произвольного внимания происходит под влиянием семьи, детского сада, интеллектуального развития, в целостной системе обучения и воспитания. Оно включает в себя и развитие волевых качеств, и вырабатывание сознательного отношения к получению знаний, и физическое, и эстетическое воспитание. При этом важная роль отводится применению педагогического мастерства, благодаря которому возможно максимально эффективно организовать занятия дошкольников. От педагога потребуются доходчивость, ясность, выразительность подачи материала, наглядность, использование специальных упражнений на развитие внимания. Эффективны выделение букв, закрашивание, нахождение ошибок и другие приёмы. Привлечение дошкольников к новым для них видам деятельности, направление и руководство взрослых постепенно помогут ребёнку овладеть умением управлять вниманием самостоятельно.
При этом важная роль отводится применению педагогического мастерства, благодаря которому возможно максимально эффективно организовать занятия дошкольников. От педагога потребуются доходчивость, ясность, выразительность подачи материала, наглядность, использование специальных упражнений на развитие внимания. Эффективны выделение букв, закрашивание, нахождение ошибок и другие приёмы. Привлечение дошкольников к новым для них видам деятельности, направление и руководство взрослых постепенно помогут ребёнку овладеть умением управлять вниманием самостоятельно.
В формировании произвольного внимания важная роль отводится воспитанию настойчивого следование к цели, силы воли и целеустремлённости. Не менее важная роль отводится и играм, требующим следовать определённым правилам. Такие игры воспитывают характер, волю, самостоятельность, целеустремлённость и активность.
В следующей статье мы поговорим о развитии произвольного внимания, рассмотрим несколько игр на развитие произвольного внимания, а также подробнее остановимся на видах нарушений и способах коррекции произвольного внимания ребёнка.
Регулярные занятия и тренировки внимания всегда приносят ощутимые результаты. Развивать объём, концентрацию, устойчивость, переключаемость внимания никогда не поздно! Это можно делать ежедневно и с удовольствием, с помощью игровых тренажеров для мозга онлайн .
Желаем Вам успехов в саморазвитии!
Поделиться
FacebookTwitterRedditPinterestLinkedInStumbleUponvKontakte
Что такое произвольное внимание. Особенности формирования и виды.
Началась школьная пора, а, значит, многие родители снова «сядут за уроки». После каникул детям сложно сконцентрироваться на учебе, их отвлекают социальные сети, друзья, интересные занятия. Определенного усердия и включенности в процесс обучения от детей требуют и в дошкольных образовательных учреждениях.
Зачастую родители считают своих детей невнимательными, потому что видят рассеянный взгляд, неусидчивость, отсутствие желания. Но не многие знают, как формируется произвольное внимание — важный навык, который поддается «тренировке».
В этой статье мы поясним, что такое произвольное внимание, рассмотрим механизм возникновения произвольного внимания и расскажем, как его развить.
В этой статье мы поясним, что такое произвольное внимание, рассмотрим механизм возникновения произвольного внимания и расскажем, как его развить.
Что такое произвольное внимание
Внимание в общем смысле — это биологический процесс, который заключается в формировании познавательной активности и направлении ее на объекты окружающего мира.
Этот биологический процесс принято разделять на:
- непроизвольный
- произвольный
- послепроизвольный
Непроизвольное внимание не требует от человека каких-либо усилий (умственных, физических, интеллектуальных). Его можно назвать пассивным. В любом возрасте мы с вами можем непроизвольно останавливать взгляд на чем-либо и проявлять кратковременный интерес.
Произвольное внимание в психологии — это процесс осознанного, сфокусированного, нацеленного на определенный результат и активного внимания для решения поставленных задач. Этот процесс характеризуется нацеленностью на результат, наличием задачи, поэтапностью ее реализации, волевыми усилиями, повышением концентрации.
Произвольность внимания мы формируем с детства — когда в младенчестве мама дает нам игрушку, мы смотрим на ее и концентрируемся на форме и цвете. Так начинает формироваться необходимая психическая функция.
Мы концентрируемся на каком-то действии, ставим перед собой задачу и выполняем ее благодаря навыкам произвольного внимания.
Пример
Учитель удерживает интерес учеников на предмете, а ученики концентрируются на информации, написанной на доске. Водители, благодаря навыку произвольного внимания, могут следить за дорогой, движением и обстановкой вокруг для недопущения ДТП. Посетители кинотеатра включаются в увлекательный процесс, когда следят за происходящим на экране.
Посетители кинотеатра включаются в увлекательный процесс, когда следят за происходящим на экране.
Психологическая сущность произвольного внимания заключается в том, что человек прилагает определенные усилия к восприятию информации, анализирует свои действия для того, чтобы достичь определенных результатов, проявляет свою волю, личные качества.
Важно! На степень развития произвольного внимания влияет интеллектуальное развитие, воспитание, процесс обучения и освоения новых знаний, социальная среда (особенно в дошкольных и общеобразовательных учреждениях).
Виды произвольного внимания
Произвольное внимание бывает нескольких видов и отличается определенными свойствами. Ниже в таблице мы рассмотрим, чем обусловлено волевое, выжидательное, сознательное и спонтанное внимание.
|
Вид произвольного внимания |
Характеристики произвольного процесса |
|
Волевое |
Проявляется волевым качеством, когда нужно принять решение, выбрать между желанием и обязательствами, если они противоречат друг другу. |
|
Выжидательное |
Такой произвольный процесс проявляется тогда, когда человеку нужно дополнительное время на обдумывание ситуации. |
|
Сознательное |
Не требует больших умственных и логических усилий, естественный процесс для человека. |
|
Спонтанное |
Сначала возникает необходимость сконцентрироваться на каком-то действии, а потом человеку не требуются большие усилия. |

В силу возраста ребенка произвольное внимание имеет свои особенности. Младенец может концентрироваться на игрушке не более 15 минут, уровень концентрации растет, в 2-3 года занять ребенка можно на 40 минут, а к дошкольному возрасту развиваются собственные волевые черты при принятии решений.
При этом у младших школьников усидчивости не хватает, поэтому им трудно концентрироваться на предмете и задаче больше часа.
Особенности произвольного процесса
Произвольное внимание имеет свои особенности, например, важную роль в его формировании играет социальный фактор. Уровень внимания складывается из личного прошлого опыта и знаний (они накладываются друг на друга, формируя целостную личность), окружения, воспитания и некоторых других факторов.
Произвольное внимание как психическая функция характеризуется следующими условиями:
- активной умственной деятельностью
- поэтапностью и логичностью
- осознанным подходом
- эволюционным происхождением
- наличием определенных условий для усвоения информации
Важно! Развить произвольное внимание в отрыве от социальных связей и окружения практически невозможно. Сначала этот процесс у ребенка формируют взрослые, а только после 5-6 лет он может организовывать собственную внимательность самостоятельно.
Сначала этот процесс у ребенка формируют взрослые, а только после 5-6 лет он может организовывать собственную внимательность самостоятельно.
Как повысить степень концентрацию ребенка
В современном мире нас окружают очень много раздражителей, поэтому даже взрослому тяжело концентрироваться на каком-то действии, не то что ребенку.
Но при этом статистика показывает, что вниманием можно не только управлять, но и тренировать его. Для этого психологи, социальные работники, педагоги пользуются специальными методиками. Родители тоже могут участвовать в процессе тренировки.
Стоит отметить, что на степень детского произвольного внимания влияют:
- общее физическое и эмоциональное состояние ребенка
- благоприятная атмосфера и окружение (без громких звуков, шума, большого количества людей и без других отвлекающих факторов)
- правильная постановка цели
- возрастные возможности, навыки и умения
- чередование физической и умственной деятельности
Родителям детей младшего дошкольного и школьного возраста рекомендовано управлять вниманием ребенка через игры.
Запишитесь на онлайн-консультацию, если вы стали замечать, что ваш ребенок стал неусидчивым, ему трудно сконцентрировать на решении задач, ему трудно проявлять свои волевые качества. Наши психологи проведут индивидуальные консультации с вами и вашим ребенком и помогут направить интерес ребенка на нужную деятельность.
Частые вопросы
Что такое произвольное внимание?
+
Приведем краткое определение — это процесс фокусировки на каком-то определенном объекте окружающей среды или задаче для получения необходимого результата.
Как формируется развитие произвольного внимания у ребенка?
+
Простейшая форма этого процесса — перевод взгляда на предмет перед глазами проявляется у младенцев. В возрасте 2-3 лет у ребенка формируется сознательное произвольное внимание. В более старшем возрасте (около 5 лет) ребенок может выполнить несложные инструкции взрослого — его навыка хватает на то, чтобы понять и проанализировать желание родителя. В 7-8 лет развиваются собственные волевые процессы, появляется осознанной в желаниях и определенное целеполагание.
В возрасте 2-3 лет у ребенка формируется сознательное произвольное внимание. В более старшем возрасте (около 5 лет) ребенок может выполнить несложные инструкции взрослого — его навыка хватает на то, чтобы понять и проанализировать желание родителя. В 7-8 лет развиваются собственные волевые процессы, появляется осознанной в желаниях и определенное целеполагание.
Как организовать занятия с ребенком, чтобы он не терял концентрацию?
+
Как мы уже сказали ранее, дошкольники хорошо воспринимают обучение в игровой форме, поэтому вы можете перед началом игры объяснить все правила, обозначить сроки игры (специально отмечать начало и конец игры), группировать предметы таким образом, чтобы в поле зрения были только нужные для занятия атрибуты (убирайте излишний «шум»), чередуйте игры, направленные на развитие разных органов чувств (тактильные, слуховые, зрительные), дозируйте время занятия (когда от ребенка требуется максимальная концентрация) и не забывайте про краткие перерывы.
В чем причина слабого произвольного внимания у ребенка?
+
Причин может быть несколько — от усталости и стресса до серьезных заболеваний, таких как СДВГ, инфекционные заболевания, черепно-мозговые травмы, изменения структур головного мозга, сосудистые нарушения. Также психологи и врачи отмечают, что снижение концентрации может говорить о недостаточном психическом тонусе.
Заключение эксперта
Внимание, как психологический и физический процесс играет важную роль в формировании личности. Развитием интереса и усидчивости у ребенка должны заниматься родители, социальные работники, педагоги и психологи. Правильно выстроенная системы образования напрямую влияет на уровень развития внимательности и интеллекта ребенка.
Публикуем только проверенную информацию
Автор статьи
Монахова Альбина Петровна клинический психолог
Стаж 17 лет
Консультаций 1439
Статей 361
Специалист в области клинической психологии. Помощь в поиске инструментов для самореализации, проработка убеждений, страхов и тревог. Работа с самоотношением, внутренними границами, понимание взаимодействия с социумом через осознанные личностные изменения.
Помощь в поиске инструментов для самореализации, проработка убеждений, страхов и тревог. Работа с самоотношением, внутренними границами, понимание взаимодействия с социумом через осознанные личностные изменения.
- 2007 — 2008 год МУЗ Детская поликлиника №4 — педагог психолог
- 2008 — 2009 ООО Здоровая страна — клинический психолог
- 2009 — 2021 год Республиканский наркологический диспансер — психолог
- 2012 — 2013 год Профессиональная медицина — психолог
- 2013 — 2015 год ООО Возрождение — психолог
- 2019 по настоящее время ООО Теледоктор24 — психолог
Руководство для начинающих по использованию уровня внимания в нейронных сетях
Если мы предоставляем модели огромный набор данных для обучения, возможно, модели могут игнорировать несколько важных частей данных. Необходимо обращать внимание на важную информацию, и это может улучшить производительность модели. Этого можно добиться, добавив в модели дополнительную функцию внимания. Нейронные сети, построенные с использованием разных слоев, могут легко включать эту функцию через один из слоев. Мы можем использовать уровень внимания в его архитектуре, чтобы улучшить его производительность. В этой статье мы собираемся обсудить уровень внимания в нейронных сетях и понять его значение и то, как его можно практически добавить в сеть. Основные моменты, которые мы здесь обсудим, перечислены ниже.
Этого можно добиться, добавив в модели дополнительную функцию внимания. Нейронные сети, построенные с использованием разных слоев, могут легко включать эту функцию через один из слоев. Мы можем использовать уровень внимания в его архитектуре, чтобы улучшить его производительность. В этой статье мы собираемся обсудить уровень внимания в нейронных сетях и понять его значение и то, как его можно практически добавить в сеть. Основные моменты, которые мы здесь обсудим, перечислены ниже.
Содержание
- Проблема с нейронными сетями
- Что такое механизм внимания?
- Механизм внутреннего внимания
- Механизм мягкого/общего внимания
- Механизм локального/жесткого внимания
- Реализация
Проблема с нейронными сетями
Во многих случаях мы видим, что традиционные нейронные сети не способен удерживать и работать с длинной и большой информацией. Давайте поговорим о моделях seq2seq, которые также являются своего рода нейронной сетью и хорошо известны для языкового моделирования. Более формально можно сказать, что модели seq2seq предназначены для преобразования последовательной информации в последовательную информацию, и обе эти информации могут иметь произвольную форму. Простым примером задачи, поставленной перед моделью seq2seq, может быть перевод текстовой или звуковой информации на другие языки.
Более формально можно сказать, что модели seq2seq предназначены для преобразования последовательной информации в последовательную информацию, и обе эти информации могут иметь произвольную форму. Простым примером задачи, поставленной перед моделью seq2seq, может быть перевод текстовой или звуковой информации на другие языки.
Источник изображения
Изображение выше представляет собой представление модели seq2seq, в которой кодирование LSTM и декодер LSTM используются для перевода предложений с английского языка на французский. Таким образом, мы можем сказать, что в архитектуре этой сети у нас есть кодировщик и декодер, который также может быть нейронной сетью.
Когда мы говорим о работе энкодера, то можно сказать, что он модифицирует последовательную информацию во вложение, которое также можно назвать вектором контекста фиксированной длины. Критическим недостатком контекстного вектора фиксированной длины является то, что сеть становится неспособной запоминать большие предложения. Мы часто можем столкнуться с проблемой забывания начальной части последовательности после обработки всей последовательности информации, или мы можем рассматривать ее как предложение. Таким образом, предоставив надлежащий механизм внимания к сети, мы можем решить проблему.
Мы часто можем столкнуться с проблемой забывания начальной части последовательности после обработки всей последовательности информации, или мы можем рассматривать ее как предложение. Таким образом, предоставив надлежащий механизм внимания к сети, мы можем решить проблему.
Что такое механизм внимания?
Механизм, который может помочь нейронной сети запоминать длинные последовательности информации или данных, можно рассматривать как механизм внимания, и в широком смысле он используется в случае нейронного машинного перевода (NMT). Как мы обсуждали в предыдущем разделе, кодировщик сжимает последовательный ввод и обрабатывает ввод в форме вектора контекста. Мы можем ввести механизм внимания для создания ярлыка между всем входом и вектором контекста, где веса соединения ярлыка могут быть изменены для каждого выхода.
Из-за связи между вводом и вектором контекста вектор контекста может иметь доступ ко всему вводу, и проблема забывания длинных последовательностей может быть частично решена. Используя механизм внимания в сети, вектор контекста может иметь следующую информацию:
Используя механизм внимания в сети, вектор контекста может иметь следующую информацию:
- Скрытые состояния кодировщика;
- Декодер скрытых состояний;
- Выравнивание между источником и целью.
Используя приведенную выше информацию, вектор контекста будет более ответственным за более точную работу за счет уменьшения количества ошибок в преобразованных данных.
Источник изображения
Приведенное выше изображение является представлением модели seq2seq с интегрированным в нее механизмом аддитивного внимания. Давайте представим механизм внимания математически, чтобы он имел более четкое представление перед нами. Допустим, у нас есть вход с последовательностями n и выход y с последовательностью m в сети.
х = [х 1 , х 2 ,…, х n ]
у = [у 1 , у 2 ,…, у m ]
Теперь кодировщик, который мы используем в сети, представляет собой двунаправленную сеть LSTM, в которой он имеет прямое скрытое состояние и обратное скрытое состояние. Представление состояния кодировщика может быть выполнено конкатенацией этих прямых и обратных состояний.
Представление состояния кодировщика может быть выполнено конкатенацией этих прямых и обратных состояний.
Где в сети декодера скрытое состояние
Для выходного слова в позиции t вектор контекста C t может быть суммой скрытых состояний входной последовательности.
Здесь мы видим, что сумма скрытых состояний взвешивается баллами выравнивания. Можно сказать, что {α t,i } – это веса, отвечающие за определение того, какая часть скрытого состояния каждого источника должна учитываться для каждого вывода.
Могут быть различные типы оценок выравнивания в зависимости от их геометрии. Он может быть как линейным, так и в криволинейной геометрии. Ниже приведены некоторые из популярных механизмов внимания:
У них разные функции оценки соответствия. Кроме того, мы можем разделить механизм внимания на следующие категории: 9.0003
- Самостоятельное внимание
- Глобальное/мягкое
- Локальное/жесткое
Давайте познакомимся с категориями механизма внимания.
Механизм внутреннего внимания
Когда к сети применяется механизм внимания, который может относиться к разным позициям одной последовательности и может вычислять представление одной и той же последовательности, это можно рассматривать как внутреннее внимание и это также может быть известно как внутреннее внимание. В газете о. Сети долговременной кратковременной памяти для машинного чтения, авторы Цзяньпэн Ченг, Ли Донг и Мирелла Лапата, мы видим использование механизмов самоконтроля в сети LSTM. На изображении ниже представлен результат модели, когда машина читает предложения.
Здесь на изображении красный цвет представляет слово, которое в данный момент изучается, а синий цвет — память, а интенсивность цвета представляет степень активации памяти.
На данный момент мы рассмотрели механизм внимания, и когда речь идет о степени внимания, применяемого к данным, в картину вступает механизм мягкого и жесткого внимания, который можно определить следующим образом.
Механизм мягкого/глобального внимания: Когда внимание, применяемое в сети, предназначено для обучения, каждый патч или последовательность данных можно назвать механизмом мягкого/глобального внимания. Это внимание можно использовать в области обработки изображений и языковой обработки.
Для обработки изображений такое же внимание уделяется в статье «Нейронный машинный перевод» в статье «Совместное обучение выравниванию и переводу», созданной Дмитрием Богдановым, Кёнхён Чо и Йошуа Бенжио.
Механизм локального/жесткого внимания: когда механизм внимания применяется к некоторым фрагментам или последовательностям данных, его можно рассматривать как механизм локального/жесткого внимания. Этот тип внимания в основном применяется к сети, работающей с задачей обработки изображений.
Статья Minh-Thang Luong, Hieu Pham и Christopher D. Manning «Эффективные подходы к нейронному машинному переводу на основе внимания» представляет собой пример применения глобального и локального внимания в работе нейронной сети для перевода предложений.
Источник изображения
На изображении выше представлен механизм глобального и локального внимания. Давайте рассмотрим реализацию механизма внимания с помощью python.
Реализация
Говоря о реализации механизма внимания в нейронной сети, мы можем реализовать его различными способами. Один из способов можно найти в статье. Где мы можем увидеть, как механизм внимания может быть применен в двунаправленной нейронной сети LSTM со сравнением точности моделей, где одна модель представляет собой просто двунаправленный LSTM, а другая модель представляет собой двунаправленный LSTM с механизмом внимания, и этот механизм вводится в сеть определяется функцией.
Мы также можем приблизиться к механизму внимания, используя уровень внимания, предоставленный Keras. Следующие строки кода являются примерами импорта и применения уровня внимания с использованием Keras, а TensorFlow можно использовать в качестве серверной части.
из кераса импорта тензорного потока из слоев импорта keras слои.
 Внимание(
use_scale = Ложь, ** kwargs
)
Внимание(
use_scale = Ложь, ** kwargs
) Здесь вышеприведенный уровень внимания представляет собой механизм внимания с точечным произведением. Мы можем использовать слой в сверточной нейронной сети следующим образом.
Перед применением слоя внимания в модели необходимо выполнить некоторые обязательные шаги, такие как определение формы входной последовательности с использованием входного слоя.
запрос = keras.Input(shape=(None,), dtype='int32') value = keras.Input(shape=(None,), dtype='int32')
В качестве входных данных уровень внимания принимает тензор запроса формы [batch_size, Tq, dim] и тензор значений формы [batch_size, Tv , dim], которые мы определили выше. Теперь мы можем сделать вложение, используя тензор той же формы.
token_embedding = слои.Embedding (input_dim = 1000, output_dim = 64) query_embeddings = token_embedding (запрос) value_embeddings = token_embedding(value)
Теперь мы можем определить сверточный слой, используя модули, предоставляемые Keras.
layer_cnn =layers.Conv1D(filters=100, kernel_size=4, padding='same')
Здесь заполнение аргумента установлено таким же, чтобы встраивание, которое мы отправляем в качестве входных данных, могло оставаться прежним после сверточный слой.
Теперь мы можем поместить вложения в сверточный слой.
query_encoding = layer_cnn (query_embeddings) value_encoding = layer_cnn(value_embeddings)
Теперь мы можем добавить кодировки к уровню внимания, предоставленному модулем слоев Keras.
query_attention_seq =layers.Attention()([query_encoding, value_encoding])
До сих пор мы позаботились о форме встраивания, чтобы мы могли поместить требуемую форму в уровень внимания. Теперь, если требуется, мы можем использовать объединяющий слой, чтобы мы могли изменить форму вложений,
query_encoding = слои.GlobalAveragePooling1D()(query_encoding) query_value_attention = Layers.GlobalAveragePooling1D()(query_attention_seq)
После добавления слоя внимания мы можем создать входной слой DNN, объединив запрос и встраивание документа.
input_layer = tf.keras.layers.Concatenate()([query_encoding, query_value_attention])
В конце концов, мы можем добавить больше слоев и соединить их с моделью.
Заключительные слова
Здесь, в статье, мы увидели некоторые критические проблемы с традиционной нейронной сетью, которые можно решить с помощью уровня внимания в сети. Наряду с этим мы видели категории слоев внимания с некоторыми примерами, где применяются различные типы механизмов внимания для получения лучших результатов, и как их можно применять к сети с помощью Keras в python. Я рекомендую читателям ознакомиться со статьей, где мы можем увидеть общую реализацию уровня внимания в двунаправленном LSTM с объяснением двунаправленного LSTM.
Ссылки
- Практическое руководство по Bi-LSTM с вниманием
- Официальная страница Attention Layer в Keras
Transformer: движок, лежащий в основе ChatGPT
В предыдущей статье мы рассмотрели сжатую историю вычислительных языковых моделей, лежащих в основе ChatGPT. Нам удалось полностью избежать разговоров о том, как устроены различные нейронные сети, и о математике, стоящей за ними. Но теперь, когда мы приближаемся к архитектуре Transformer, которая является рабочей лошадкой для ChatGPT, мы должны немного углубиться в детали, чтобы понять ее смысл. Мы начнем с нескольких основных определений, а затем рассмотрим следующие темы:
Нам удалось полностью избежать разговоров о том, как устроены различные нейронные сети, и о математике, стоящей за ними. Но теперь, когда мы приближаемся к архитектуре Transformer, которая является рабочей лошадкой для ChatGPT, мы должны немного углубиться в детали, чтобы понять ее смысл. Мы начнем с нескольких основных определений, а затем рассмотрим следующие темы:
Сети с прямой связью
RNN: простейшие нейронные сети, которые могут работать с последовательными данными 03
Transformer: архитектура нейронной сети, которая сделала возможным использование ChatGPT и других LLM.
Машинное обучение
Рассмотрим функцию F, которая принимает входной вектор X и выдает вектор Y.
F(X) = Y
Обычно большую часть времени при вычислениях нам дают функцию F и ввод X , и мы должны вычислить Y . Например, F может быть линейной функцией, такой как F(X) = 3X + 2 , и при значении X = 5 мы вычисляем Y = 3*5 + 2 =17 .
В машинном обучении мы инвертируем эту парадигму и, учитывая примеры входных и выходных данных, хотим вычислить функцию. Например, если мы дадим вам пары входных данных ( x=0, y=2), (x=1, y=5), (x=2, y=8) и т. д., вы можете догадаться, что F равно 3X + 2 .
Однако отношения между X и Y в большинстве случаев не так просты. Вы можете вычислить F только в грубом приближении. Например, имея набор точек, вы можете построить прямую линию, проходящую близко к этим точкам. Это часто называют линейной регрессией. В одном измерении линейную регрессию можно описать как F(X) = aX + b , и по заданному набору точек нам нужно найти наилучшее значение a и b . В этом случае a и b являются программируемыми параметрами линейной функции.
Вы также можете попробовать подобрать квадратичную функцию F(X) = aX 2 + bX + c. Теперь осталось настроить три параметра, чтобы функция соответствовала данным. Мы также можем подобрать экспоненциальную кривую F(X) = aX b с двумя параметрами a и б . На выбор может быть много разных семейств функций, и каждое семейство имеет свой собственный набор параметров, которые можно выбрать для наилучшего соответствия данным.
Мы также можем подобрать экспоненциальную кривую F(X) = aX b с двумя параметрами a и б . На выбор может быть много разных семейств функций, и каждое семейство имеет свой собственный набор параметров, которые можно выбрать для наилучшего соответствия данным.
В целом машинное обучение — это процесс выбора правильного типа функции и последующего нахождения значений параметров этого типа функции, которые лучше всего соответствуют обучающим данным.
Нейронные сети и параметры
Искусственные нейронные сети (ИНС) — это класс параметризованных математических функций, вдохновленных биологическими нейронами в нашем мозгу. В среднем нейрон в нашем мозгу связан примерно с десятью тысячами других нейронов. Нейроны общаются посредством электрических импульсов. Сила связей между нейронами определяет, насколько сильный импульс передается от одного нейрона к другому. По мере того как мы что-то узнаём или забываем, сила этих связей меняется. Когда общая сила всех импульсов, поступающих на нейрон, превышает пороговое значение, этот нейрон срабатывает и посылает электрический импульс нижестоящим нейронам.
Когда общая сила всех импульсов, поступающих на нейрон, превышает пороговое значение, этот нейрон срабатывает и посылает электрический импульс нижестоящим нейронам.
Аналогично, в ИНС искусственные нейроны связаны с другими искусственными нейронами, а сила связи между парой нейронов является программируемым параметром, который задается в процессе обучения. Часто нейроны организованы слоями. Первый слой называется входным слоем, а последний слой называется выходным слоем. Различные слои связаны определенным образом, который определяется архитектурой сети, выбранной ее автором. Чем больше программируемых соединений имеет сеть, тем больше вещей она может узнать или запомнить. Большое количество программируемых параметров или соединений также означает, что для обучения чему-то значимому требуется больше обучающих данных, а для обучения сети или ее использования требуется больше вычислений.
Сети прямой связи
Все началось с того, что мы называем сетями прямой связи. В этой модели у вас есть последовательность слоев нейронной сети, которые располагаются друг над другом так, что выходные данные одного слоя передают входные данные следующего слоя, поэтому, когда вы предоставляете входные данные на первом уровне и выполняете вычисления, мы получаем выход нейронной сети. Каждый слой обычно состоит из матрицы весов W , которая при умножении на входной вектор дает выходной вектор. Оттуда мы можем применить нелинейную функцию к каждому из значений выходного вектора.
В этой модели у вас есть последовательность слоев нейронной сети, которые располагаются друг над другом так, что выходные данные одного слоя передают входные данные следующего слоя, поэтому, когда вы предоставляете входные данные на первом уровне и выполняете вычисления, мы получаем выход нейронной сети. Каждый слой обычно состоит из матрицы весов W , которая при умножении на входной вектор дает выходной вектор. Оттуда мы можем применить нелинейную функцию к каждому из значений выходного вектора.
Сети такого типа представляют собой чистую функцию, которая при заданных входных данных может вычислить выходные данные, но ничего не запоминает при получении следующих входных данных. Например, вы можете научить сеть с прямой связью принимать все значения пикселей изображения 8×8 и выводить 1, если оно представляет изображение цифры, и ноль в противном случае.
Они отлично подходят для обработки входных данных фиксированного размера для получения выходных данных фиксированного размера, но не подходят для обработки последовательности переменного размера (например, последовательности слов произвольной длины) и создания вывода переменного размера (например, другой последовательность слов, представляющая перевод слов.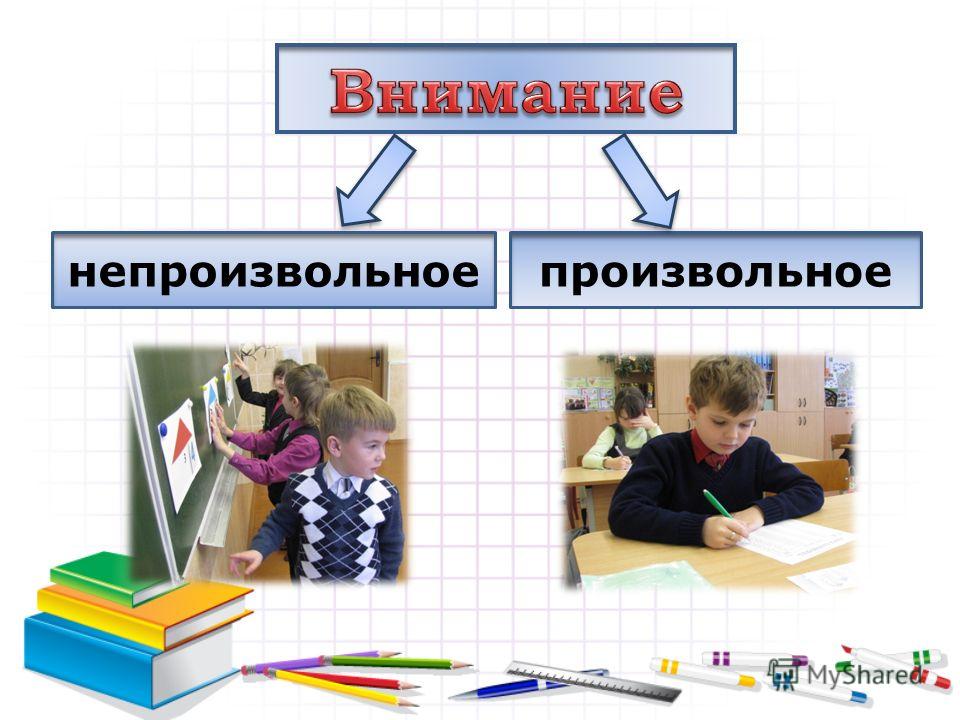 )
)
Рекуррентные нейронные сети (RNN)
Повторяющееся означает повторяющееся или повторяющееся через определенный интервал времени. В рекуррентных нейронных сетях (RNN) одни и те же вычисления выполняются снова и снова, когда вы обрабатываете данные временных рядов или последовательность слов произвольной длины.
Давайте рассмотрим очень простую задачу, где вам дано количество вызовов API каждую секунду. Вы хотите предупредить, если это число превысит тысячу вызовов в секунду. Но так как данные очень зашумлены, и вы не хотите предупреждать, если нет устойчивого большого всплеска. Таким образом, вы выбираете экспоненциальное среднее число вызовов API в секунду, и если это экспоненциальное среднее превышает тысячу, вы предупреждаете. Предположим x t описывает количество вызовов API за время t , h t обозначает экспоненциальное среднее с затуханием 0,9, а y t описывает, следует ли предупреждать или нет. Тогда вы можете описать вычисление y t следующим образом: 60 i — 1 + 0,1 x i
Тогда вы можете описать вычисление y t следующим образом: 60 i — 1 + 0,1 x i
г я = 1, если h i > 1000 иначе 0
Вторая и третья строки вычисления повторяются для каждого временного шага i . Это пример того, как вы обрабатываете последовательность переменной длины и выводите другую последовательность переменной длины. Теперь обобщим эту идею на произвольные векторы и произвольные функции.
h i = F 1 (h i — 1 , x i )
y i 9006 1 = F 2 (ч i — 1 , x i )
Единственное отличие предыдущей версии уравнения от этой состоит в том, что мы использовали произвольные функции F1 и F2 вместо конкретных функций для экспоненциального усреднения с некоторым затуханием. В RNN F1 и F2 представляют собой сети с прямой связью, которые обучаются на основе обучающих данных.
Вы можете научить RNN читать последовательность вложений слов и выводить их перевод. Вы также можете обучить RNN брать исторические данные о погоде и прогнозировать погоду на следующий день. Всякий раз, когда ввод или вывод включали последовательности, RNN были выбранной архитектурой в течение определенного периода времени.
Что отличает RNN от сетей с прямой связью, так это элемент обратной связи. Выход h i , вычисленный на шаге i, затем возвращается в сеть на шаге i + 1 . Этот механизм обратной связи помогает сети вспомнить некоторую информацию из прошлого. Этот механизм обратной связи также усложняет обучение этих сетей. В частности, если задача требовала, чтобы сеть помнила что-то за несколько временных шагов.
Если вы хотите узнать больше, вот отличный ресурс .
Сети с долговременной кратковременной памятью (LSTM)
LSTM представляют собой особый класс рекуррентных сетей, которые были разработаны для обеспечения более длительной кратковременной памяти о недавнем прошлом, чем базовые RNN.
Давайте рассмотрим проблему, аналогичную приведенной выше, где нам дано количество вызовов API каждую секунду, но теперь мы хотим предупредить, если в течение пяти последовательных секунд не было вызовов API. Это может означать какой-то сбой. Теперь мы больше не можем решить это экспоненциальным усреднением. Один из способов сделать это — поддерживать скользящее окно для последних пяти значений и предупреждать всякий раз, когда сумма по этому окну равна нулю. Теперь математика выглядит следующим образом:
Окно 0 = {}
Окно i = Окно i -1 .erase( x i — 5 ).insert(x я )
у я = 1 if sum(Window i ) = 0 else 0
Переход от этого к LSTM немного сложнее, чем раньше, но применяется та же идея. Если функция для того, что сохраняется во внутреннем состоянии (окно) , и функция для того, что забывается из внутреннего состояния, вычисляется с использованием нейронных сетей с прямой связью, у вас есть концепция LSTM.
Основная причина, по которой это работает лучше, чем базовые RNN, заключается в том, что он может запоминать больше информации о входных данных из нескольких предыдущих шагов. Его кратковременная память остается дольше. И для RNN, и для LSTM это отличный ресурс .
Внимание
Это была еще одна очень важная идея, которая существенно улучшила поведение современных моделей. Предположим, вы переводите французское предложение je suis étudiant как «Я студент». Слово je сопоставляется с I, слово étudiant сопоставляется со студентом. Suis как бы отображает как am, так и a. Итак, если вы хотите увидеть, на какое слово следует обратить внимание при создании соответствующего слова, следующая матрица будет очень полезна.
Чтобы понять, как усложняется эта задача, давайте посмотрим на рисунок ниже:
Вы заметите, что для некоторых слов требуется информация из более чем одного слова, и это, конечно, не однозначное сопоставление.
Интересно, что если немного изменить слова, изменится и матрица внимания. Например, в предложении «Лампу нельзя было упаковать в чемодан, потому что она была слишком велика» слово «это» относится к лампе. Но в предложении «Лампу нельзя было упаковать в чемодан, потому что это было слишком мало». Слово «это» относится к чемодану. Таким образом, единственный способ получить эти матрицы внимания — учиться на данных. Это именно то, что было предложено в этой прорывной статье Нейронный машинный перевод путем совместного обучения выравниванию и переводу .
Например, в предложении «Лампу нельзя было упаковать в чемодан, потому что она была слишком велика» слово «это» относится к лампе. Но в предложении «Лампу нельзя было упаковать в чемодан, потому что это было слишком мало». Слово «это» относится к чемодану. Таким образом, единственный способ получить эти матрицы внимания — учиться на данных. Это именно то, что было предложено в этой прорывной статье Нейронный машинный перевод путем совместного обучения выравниванию и переводу .
Здесь следует отметить, что когда мы говорим о RNN и LSTM, мы говорим о последовательностях произвольной длины, которые могут проходить через эти сети для создания конечного вектора. Однако от этого подхода отказались по двум причинам. Во-первых, вы не можете вычислить матрицы внимания, если длина ввода и вывода не ограничена каким-либо пределом. Вторая проблема исчезающие градиенты , что немного сложнее объяснить.
Большинство современных нейронных сетей обучаются, распространяя ошибку или разницу между тем, что, по словам обучающей метки, должно быть на выходе, и тем, что предсказывает текущая сеть. Это означает умножение частной производной каждого выхода по отношению к входу для каждого узла на пути от заданного узла к выходному узлу. По мере увеличения длины пути все выше и выше вероятность того, что это произведение частных производных станет либо слишком большим, либо слишком маленьким. Слишком большое означает, что оно дестабилизирует тренировочный процесс, а слишком маленькое означает, что тренировка не будет достаточно прогрессировать для достижения хорошего результата. Оба плохие.
Это означает умножение частной производной каждого выхода по отношению к входу для каждого узла на пути от заданного узла к выходному узлу. По мере увеличения длины пути все выше и выше вероятность того, что это произведение частных производных станет либо слишком большим, либо слишком маленьким. Слишком большое означает, что оно дестабилизирует тренировочный процесс, а слишком маленькое означает, что тренировка не будет достаточно прогрессировать для достижения хорошего результата. Оба плохие.
Для RNN и LSTM было очень трудно выучить ассоциации между словами, которые находятся далеко друг от друга. Это привело к архитектуре, в которой все промежуточные скрытые состояния передавались от кодировщика к декодеру посредством процесса внимания. Это снова потребовало, чтобы сеть была ограничена последовательностями фиксированной длины.
Что такое архитектура трансформатора?
В 2017 году исследователи из Google опубликовали новую архитектуру нейронной сети под названием трансформатор, которая стала основой для большей части экспоненциального прогресса в этой области за последние четыре года. Статья называлась 9.0389 Внимание — это все, что вам нужно , потому что основная идея этой архитектуры — полагаться на внимание и само-внимание, а не на петлю обратной связи, как в RNN.
Статья называлась 9.0389 Внимание — это все, что вам нужно , потому что основная идея этой архитектуры — полагаться на внимание и само-внимание, а не на петлю обратной связи, как в RNN.
Архитектура трансформатора несколько уникальна по своей конструкции по сравнению с другими архитектурами, поскольку очень трудно понять, что происходит и почему авторы делают тот или иной выбор. Есть много деталей, которые вам нужно обернуть в голове, чтобы понять это. Тем не менее, есть твердая интуиция и обоснование выбора. В следующем разделе мы рассмотрим ключевую интуицию, стоящую за этой архитектурой.
Сила архитектуры трансформатора
Есть две вещи, с которыми архитектура трансформатора справляется очень хорошо. Во-первых, это действительно хорошая работа по обучению применению контекста. Например, при обработке предложения значение слова или фразы может полностью измениться в зависимости от контекста, в котором оно используется. Часто то, как применять этот контекст, зависит не только от грамматики, но и от отношений, существующих в реальном мире. Благодаря механизму самоконтроля в этой архитектуре он действительно хорошо учится тому, как применять контекст в зависимости от данных. Во-вторых, эта архитектура обеспечивает гораздо большую распараллеливание вычислений во время обучения, а также логического вывода. Это обеспечивает гораздо более высокую пропускную способность при обучении на обучающих примерах и позволяет обучать более крупные сети с большим количеством обучающих данных в заданном временном масштабе. Самая большая модель трансформатора с 213 миллионами параметров в исходной статье обучалась в течение 3,5 дней с использованием 8 графических процессоров.
Благодаря механизму самоконтроля в этой архитектуре он действительно хорошо учится тому, как применять контекст в зависимости от данных. Во-вторых, эта архитектура обеспечивает гораздо большую распараллеливание вычислений во время обучения, а также логического вывода. Это обеспечивает гораздо более высокую пропускную способность при обучении на обучающих примерах и позволяет обучать более крупные сети с большим количеством обучающих данных в заданном временном масштабе. Самая большая модель трансформатора с 213 миллионами параметров в исходной статье обучалась в течение 3,5 дней с использованием 8 графических процессоров.
Что такое самостоятельное внимание в моделях-трансформерах?
Самостоятельное внимание — это механизм, с помощью которого сеть контекстуализирует слова, обращая внимание на другие слова, составляющие ее контекст в основной части текста. Идея внимания к себе похожа на идею внимания, представленную ранее, за исключением того, что она используется для контекстуализации слов в предложении, а не для выравнивания слов при переводе, как показано выше.
Рассмотрим эти два предложения:
Как видите, первое предложение говорит об автомобиле, а второе — о животном. Откуда нам знать? Потому что, как люди, мы знаем, что у автомобилей есть двери, а животные издают воющие звуки. Единственный способ узнать это — узнать много о концепциях или объектах реального мира и их отношениях друг с другом.
Чтобы решить эту проблему, модели преобразователя используют нейронные сети для генерации вектора с именем query и вектора с именем key для каждого слова. Когда запрос из одного слова соответствует ключу из другого слова, это означает, что второе слово имеет соответствующий контекст для первого слова. Чтобы обеспечить соответствующий контекст от второго слова до первого слова, генерируется третий вектор, называемый значением , который затем объединяется с первым словом, чтобы получить более контекстуализированное значение первого слова.
Здесь мы упрощаем большую часть сложной математики, но одна ключевая вещь, которую следует отметить, заключается в том, что для того, чтобы любая такая схема работала, вам необходимо спроектировать математику таким образом, чтобы каждая используемая функция имела плавный наклон (читай: градиент), поэтому что алгоритмы обучения могут найти оптимальные веса из примеров. Большая часть ума в преобразователях заключается в разработке этих механизмов таким образом, чтобы процесс обучения сходился и сходился быстро.
Большая часть ума в преобразователях заключается в разработке этих механизмов таким образом, чтобы процесс обучения сходился и сходился быстро.
Еще одна умная вещь, которую сделали авторы преобразователей, заключалась в том, чтобы уменьшить размер векторов для целей внимания, но одновременно использовать несколько параллельных механизмов внимания. Это позволяет нейронной сети иметь несколько снимков для захвата различных видов контекста. Кроме того, многократное повторение уровня внутреннего внимания позволяет сети объединять контекст в более крупных фразах. Например, в предложении «Это была подделка 19-го84 реклама от Apple». Во-первых, вам нужно устранить неоднозначность слова «Apple», которое в контексте рекламы и 1984 года, безусловно, является компанией, а не фруктом. Тогда у вас есть контекст, чтобы понять, что означает 1984 год. Затем вы контекстуализируете, к чему относится «это». Я размышляю здесь, но я предполагаю, что именно здесь несколько слоев само-внимания становятся очень полезными, когда вам нужно выполнять цепочку рассуждений один за другим.
Помимо самоконтроля, преобразователи также представили идею позиционного кодирования, сделав структуру сети независимой от относительного положения слова в последовательности. Затем информация о положении добавляется обратно в качестве входных данных в виде тригонометрических функций. . Это был очень интересный выбор, и, похоже, он также помог повысить эффективность сети.
Мы намеренно не будем вдаваться в детали слоев кодировщика, слоя декодера и других механизмов внимания в этой статье, но если вам интересно узнать больше, я настоятельно рекомендую прочитать The Illustrated Transformer .
Представления двунаправленного энкодера от трансформаторов (
BERT )Изначально архитектура трансформатора не привлекала особого внимания за пределами сообщества машинного обучения. Но вскоре после этого исследователи из Google обучили новую модель преобразователя для задач НЛП, которая побила рекорды по нескольким направлениям.
Модель была обучена для достижения двух целей:
Угадать пропущенные слова из основного текста
Учитывая два предложения, угадать, были ли они двумя последовательными предложениями из документа два случайно выбранных предложения из всех данных обучения .

Кроме того, сеть была разработана для вывода векторного вложения для предложения, чтобы его можно было использовать для многих различных языковых задач, таких как анализ тональности, сходство предложений и ответы на вопросы с использованием другой небольшой сети поверх нее.
Всеобщее внимание привлекло то, что BERT отлично справился с рядом языковых задач и превзошел самые современные показатели. На тот момент это была не просто крутая исследовательская идея. Различные команды разработчиков в отрасли, в том числе и мы, начали уделять пристальное внимание тому, что происходит, и выяснять, как использовать достижения в этой области.
Самая большая модель BERT содержала 345 миллионов параметров. Он был обучен на 64 тензорных процессорах (TPU), специализированном обучающем оборудовании, изобретенном Google, в течение четырех дней по ориентировочной стоимости в 7000 долларов. С одной стороны, людей беспокоило то, что новые инновации требовали все больших и больших инвестиций в оборудование, но, с другой стороны, это ясно показывало, что более крупные модели умнее и способны фиксировать большой объем знаний. Это привело к возникновению двух несколько расходящихся лагерей: тех, кто хотел обучать все более и более крупные сети-преобразователи для НЛП, чтобы увидеть, насколько умными они становятся, и тех, кто хотел обучать более мелкие сети, сохраняя при этом некоторые преимущества BERT.
Это привело к возникновению двух несколько расходящихся лагерей: тех, кто хотел обучать все более и более крупные сети-преобразователи для НЛП, чтобы увидеть, насколько умными они становятся, и тех, кто хотел обучать более мелкие сети, сохраняя при этом некоторые преимущества BERT.
Генеративный предварительно обученный преобразователь (GPT) и BERT
Генеративные предварительно обученные преобразователи — это семейство моделей преобразователей, обученных OpenAI для задач языкового моделирования. Первая модель GPT предшествует модели BERT. В то время как BERT полагался на умные цели обучения, OpenAI пошел в направлении обучающих моделей для предсказания следующего слова (языковое моделирование). Первая модель GPT имела 117 миллионов параметров и существенно изменила современные показатели для многих задач. Но только когда GPT-2 с его 1,5 миллиардами параметров начал привлекать внимание общественности.
Первоначальная идея GPT состояла в том, чтобы предварительно обучить сеть задачам языкового моделирования для большого объема текста, а затем точно настроить сеть для различных языковых задач. Таким образом, вы сможете тренироваться на модели без присмотра, без каких-либо помеченных данных, сгенерированных человеком, но при этом использовать контролируемое обучение по сравнению с меньшими помеченными данными для конкретных задач. Отсюда и термин предварительная подготовка. Однако еще более удивительным было то, что сама задача языкового моделирования стала чрезвычайно мощным инструментом. Вы можете просто поговорить с моделью и попросить ее выполнить задание, и она удивит вас довольно разумным ответом.
Таким образом, вы сможете тренироваться на модели без присмотра, без каких-либо помеченных данных, сгенерированных человеком, но при этом использовать контролируемое обучение по сравнению с меньшими помеченными данными для конкретных задач. Отсюда и термин предварительная подготовка. Однако еще более удивительным было то, что сама задача языкового моделирования стала чрезвычайно мощным инструментом. Вы можете просто поговорить с моделью и попросить ее выполнить задание, и она удивит вас довольно разумным ответом.
Сеть была обучена только предсказывать следующие слова по введенному тексту, но в зависимости от введенного вами текста модель демонстрировала признаки интеллекта, которые были бы немыслимы всего несколько лет назад. В результате мы начали называть вводимый текст подсказкой . В следующей статье вы увидите несколько примеров текста приглашения и ответов GPT-3, иллюстрирующих эмерджентные свойства больших языковых моделей.
На самом деле, не только GPT, но и множество других LLM показали, что как только модель превышает определенный пороговый размер (где-то между 50 и 100 миллиардами параметров), она начинает демонстрировать очень интересные свойства с точки зрения ее способности отвечать на вопросы.